SpringCloud
SpringCloud简介
分布式微服务架构的一站式解决方案,多种微服务架构技术的集合体,俗称微服务全家桶,集成了二十多种微服务架构技术
微服务:SpringBoot是一个个的微服务【支付、物流、仓储..】,每个服务运行在独立进程中,服务间采用轻量级的HTTP协议的RESTFulApi通信机制协作,每个服务围绕业务进行构建,能够被独立部署,这样的服务也被称为微服务,独立的一个SpringBoot开发的服务单元;
架构、技术经理考虑通盘;程序员考虑一个具体功能的落地
形象比喻:服务就是桌子上的每一个菜,SpringCloud就是桌子
SpringCLoud的功能
SpringCloud融合、协调、组装微服务,使分布式系统构建变得更加容易,提供以下针对分布式系统的服务功能
微服务的服务注册与发现【Eureka、nacos】
服务负载均衡和调用【RiBBON、Feign】
服务熔断、降级【HyStrix】
服务消息队列
分布式配置中心【Config、nacos】
服务网关【Zuul】
服务监控
全链路追踪
自动化构建部署
服务定时任务、调度操作
服务开发【SpringBoot】
SpringCloud继承的分布式项目列表
SpringCloud Config:分布式配置中心和配置管理
把配置文件放在远程服务器,几种话管理集群配置,支持本地存储,Git和Subversion
SpringCloud Bus:消息总线
用于集群中传递状态变化【如配置文件变化】,与springCloud Config联合实现热部署
Eureka:云端服务发现【服务注册中心】,已经停止更新,现在用的是阿里巴巴的nacos
基于REST的服务,定位服务,实现云端服务发现和故障转移
Hystrix:熔断器,容错管理工具
通过熔断机制控制服务和第三方库的节点从而对延迟和故障提供强大的容错能力
Zuul:是在云平台上提供动态路由、监控、弹性、安全等边缘服务的框架
相当于客户端访问服务器的所有请求的前门
Archaius:配置管理API
提供动态类型化属性、线程安全配置操作、轮询框架、回调机制等功能
Consul:封装Consul操作
Consul操作是服务发现与配置工具、可以与docker无缝集成
Spring Cloud Sleuth:日志收集工具包
封装了Dapper、log-based追踪、Zipkin和Htrace操作,为SpringCloud应用实现分布式追踪方案
Spring Cloud Data Flow:大数据操作工具
是一个混合计算模型,结合了流数据和批量数据的处理方式
SpringCloud Security:基于Spring Security的安全工具包
为应用提供安全控制
Spring Cloud Zookeeper:操作Zookeeper的工具包
用于使用Zookeeper方式的服务发现和配置管理
Spring Cloud Stream:数据流操作开发包
封装了与redis、rabbit、kafka发送消息的功能
SpringCloud CLI
可以以命令行的方式快速建立云组件
Ribbon:服务负载均衡与调度
提供多种负载均衡策略,可配合服务发现和断路器使用
NetFlix Feign:是一种声明式、模板化的Http客户端
可以实现服务间的相互调用
SpringCloud Task:
提供云端计划任务管理、任务调度
Spring Cloud Connectors:
便于云端应用【如数据库和消息代理服务】在各种PaaS平台链接后端
SpringCloud Cluster:提供leadership选举
如Zookeeper、redis、Hazelcast、Consul等常见状态模式的抽象和实现
Spring Cloud Starter:SpringBoot方式的启动项目
为SpringCloud提供开箱即用的依赖管理
SpringCloud For Cloud Foundry:通过OAuth2协议绑定服务到Cloud Foundry
Cloud Foundry是VMvare推出的开源PaaS云平台
Turbine:聚合服务器发送事件流数据的一个工具
用来监控集群下的Hystrix的metrics情况
大厂微服务架构举例
【京东】

【阿里】

【京东物流】
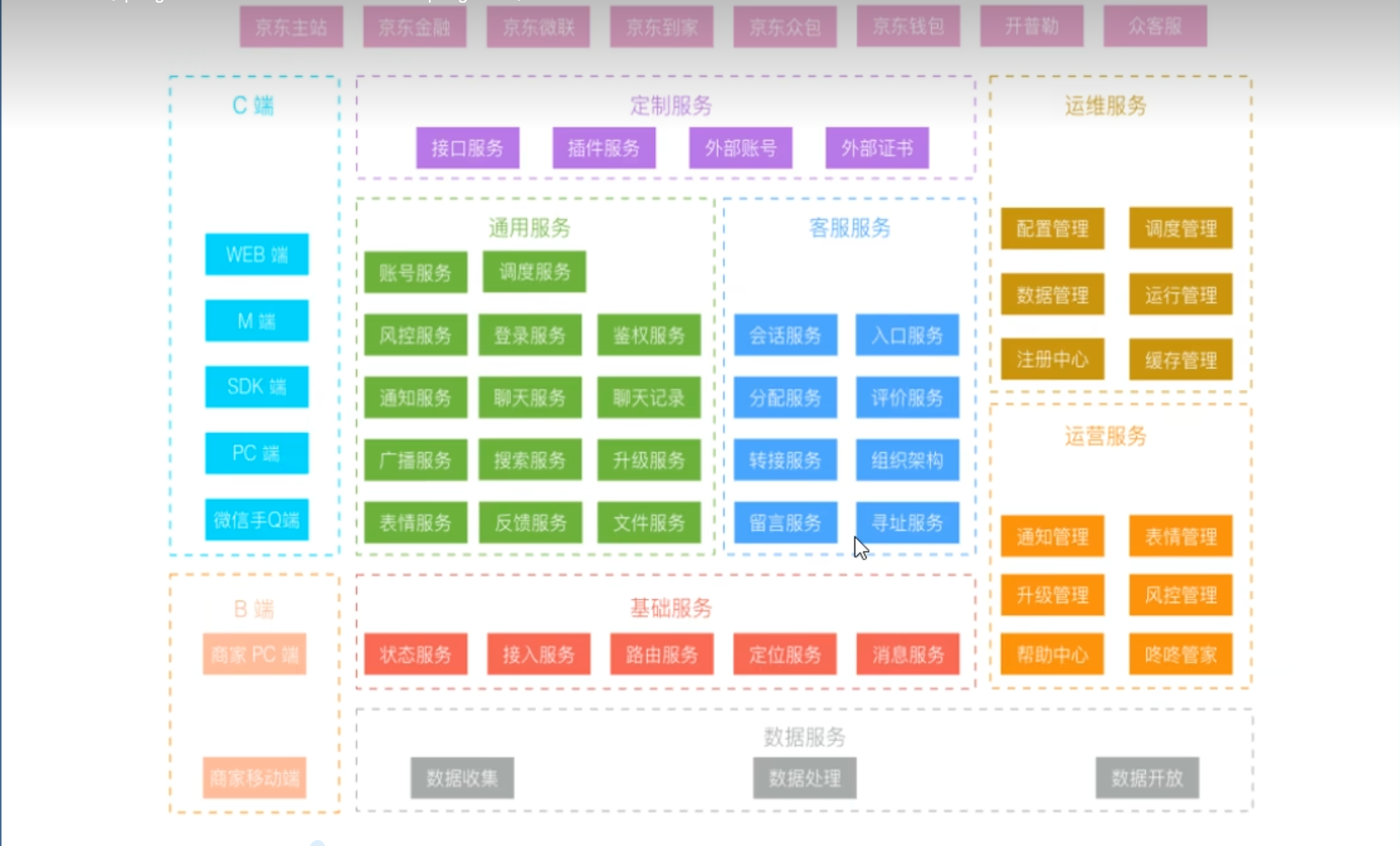
常见服务类型

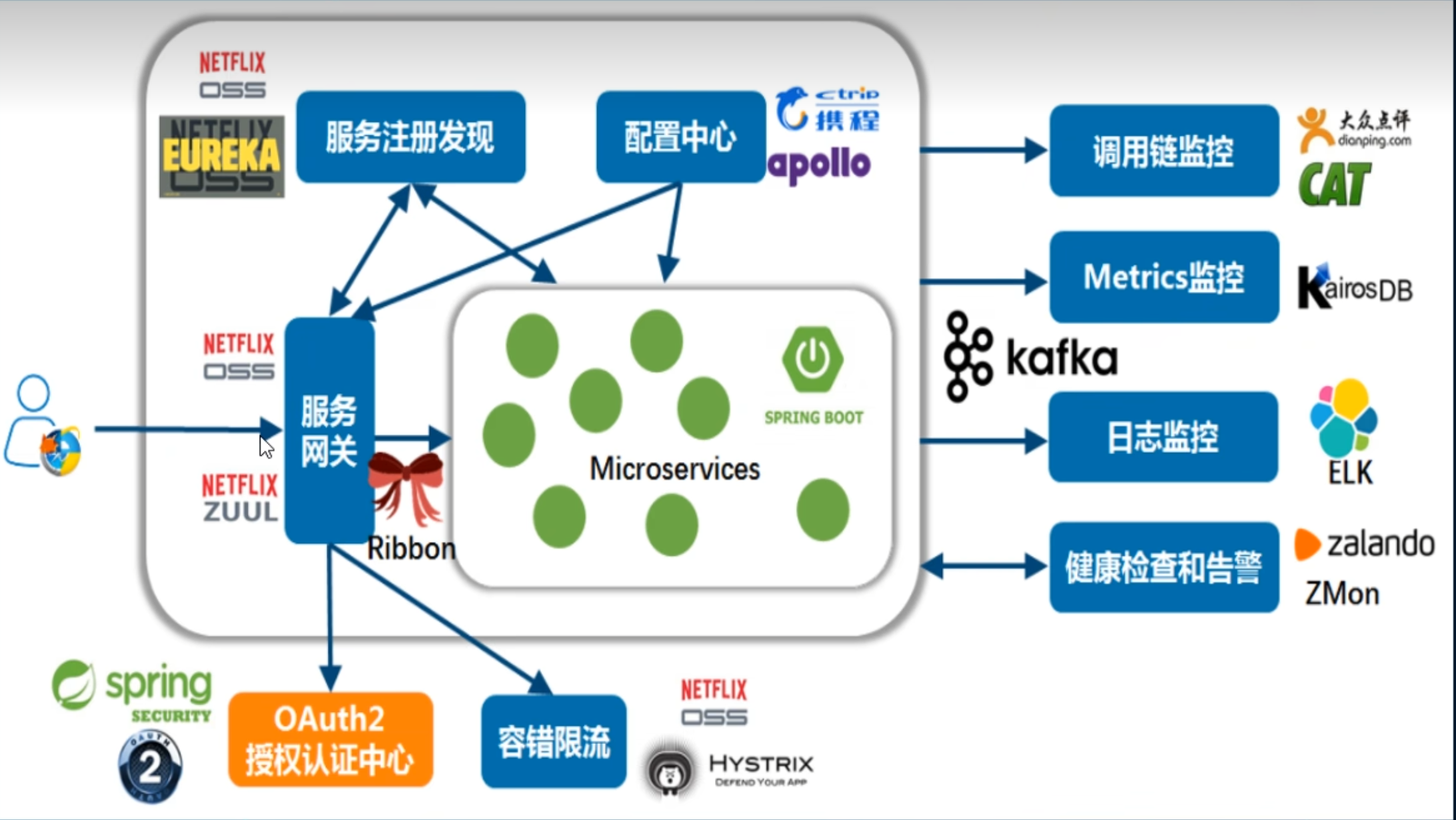
主流微服务架构体系
大框框中的是SpringCloud框架中的内容
SpringCloud的底子是NETFLIX,Cloud的工作者就是NETFLIX工作组,被Spring收编了
外部是第三方的微服务框架
SpringCloud版本
SpringBoot以数字作为版本,SpringCloud以伦敦地铁站英文大写首字母作为版本号【以A-Z依次递推形式迭代】
SpringBoot2对应SpringCloud H版
SpringBoot版本介绍
SpringBoot的git源码地址:https:github.com/spring-projects/spring-boot/releases/
SpringBoot2新特性:https:github.com/spring-projects/spring-boot/wiki/Spring-Boot-2.0-Release-Notes
自19年后SpringBoot2就已经发布稳定版本,支持Java8和Java9
SpringBoot的版本变更非常频繁
SpringCloud版本介绍
SpringCloud官网:htts://spring.io/projects/spring-cloud
Git源码地址:https:github.com/spring-projects/spring-cloud/releases/
SpringCloud发布内容基类到临界点或者重大BUG被解决后都会发布一个Service release版本,简称SRX版本【X表示数字,Greenwich.SR2就是SpringCloud发布的Greenwich版本的第二个SRX版本】
SpringBoot版本和SpringCloud版本对应关系
SpringCloud会停止对较老版本的维护,IDEA在构建项目会根据官网当前支持的版本供用户进行选择,所以官方不支持的版本在IDEA是无法选择的,但是可以在pom.xml中进行修改
版本对应信息网站:https://spring.io/projects/spring-cloud/#overview
SpringCloud和SpringBoot的版本不对应会出现非常大的麻烦,所以一定要确定好,同时使用boot和cloud,boot需要照顾cloud的版本
SpringCloud版本 SpringBoot版本 2022.0.x aka Kilburn 3.0.x, 3.1.x (Starting with 2022.0.3) 2021.0.x aka Jubilee 2.6.x, 2.7.x (Starting with 2021.0.3) 2020.0.x aka Ilford 2.4.x, 2.5.x (Starting with 2020.0.3) Hoxton 2.2.x, 2.3.x (Starting with SR5) Greenwich 2.1.x Finchley 2.0.x Edgware 1.5.x 可以通过SpringCloud提供的接口获取版本对应的详细信息:https://start.spring.io/actuator/info
使用浏览器的JsonView插件会自动把json格式字符串转换成下列格式
xxxxxxxxxx{"git": {"branch": "155e08d25081f81ecbda6cedcaf322f5ede79842","commit": {"id": "155e08d","time": "2023-10-17T15:00:04Z"}},"build": {"version": "0.0.1-SNAPSHOT","artifact": "start-site","versions": {"spring-boot": "3.1.4","initializr": "0.21.0-SNAPSHOT"},"name": "start.spring.io website","time": "2023-10-17T17:58:29.439Z","group": "io.spring.start"},"bom-ranges": {"codecentric-spring-boot-admin": {"2.6.8": "Spring Boot >=2.6.0 and <2.7.0-M1","2.7.4": "Spring Boot >=2.7.0-M1 and <3.0.0-M1","3.0.4": "Spring Boot >=3.0.0-M1 and <3.1.0-M1","3.1.5": "Spring Boot >=3.1.0-M1 and <3.2.0-M1"},"hilla": {"2.1.9": "Spring Boot >=3.1.0-M1 and <3.2.0-M1"},"sentry": {"6.28.0": "Spring Boot >=2.7.0 and <3.2.0-M1"},"solace-spring-boot": {"1.2.2": "Spring Boot >=2.6.0 and <3.0.0-M1","2.0.0": "Spring Boot >=3.0.0-M1"},"solace-spring-cloud": {"2.3.2": "Spring Boot >=2.6.0 and <3.0.0-M1","3.0.0": "Spring Boot >=3.0.0-M1"},"spring-cloud": {"2021.0.8": "Spring Boot >=2.6.0 and <3.0.0","2022.0.4": "Spring Boot >=3.0.0 and <3.2.0-M1","2023.0.0-M2": "Spring Boot >=3.2.0-M1 and <3.2.0-SNAPSHOT","2023.0.0-SNAPSHOT": "Spring Boot >=3.2.0-SNAPSHOT"},"spring-cloud-azure": {"4.11.0": "Spring Boot >=2.6.0 and <3.0.0-M1","5.5.0": "Spring Boot >=3.0.0-M1 and <3.2.0-M1"},"spring-cloud-gcp": {"3.7.1": "Spring Boot >=2.6.0 and <3.0.0-M1","4.8.1": "Spring Boot >=3.0.0-M1 and <3.2.0-M1"},"spring-cloud-services": {"3.4.0": "Spring Boot >=2.6.0 and <2.7.0-M1","3.5.0": "Spring Boot >=2.7.0-M1 and <3.0.0-M1","4.0.3": "Spring Boot >=3.0.0 and <3.2.0-M1"},"spring-modulith": {"1.0.0": "Spring Boot >=3.1.0 and <3.2.0-M1","1.1.0-M1": "Spring Boot >=3.2.0-M1"},"spring-shell": {"2.1.13": "Spring Boot >=2.7.0 and <3.0.0-M1","3.0.8": "Spring Boot >=3.0.0 and <3.1.0-M1","3.1.4": "Spring Boot >=3.1.0 and <3.2.0-M1","3.2.0-M2": "Spring Boot >=3.2.0-M1"},"vaadin": {"23.2.15": "Spring Boot >=2.6.0 and <2.7.0-M1","23.3.25": "Spring Boot >=2.7.0-M1 and <3.0.0-M1","24.1.12": "Spring Boot >=3.0.0-M1 and <3.2.0-M1"},"wavefront": {"2.2.2": "Spring Boot >=2.6.0 and <2.7.0-M1","2.3.4": "Spring Boot >=2.7.0-M1 and <3.0.0-M1","3.0.2": "Spring Boot >=3.0.0-M1 and <3.1.0-M1"}},"dependency-ranges": {"okta": {"2.1.6": "Spring Boot >=2.6.0 and <3.0.0-M1","3.0.5": "Spring Boot >=3.0.0-M1 and <3.2.0-M1"},"mybatis": {"2.2.2": "Spring Boot >=2.6.0 and <2.7.0-M1","2.3.1": "Spring Boot >=2.7.0-M1 and <3.0.0-M1","3.0.2": "Spring Boot >=3.0.0-M1"},"pulsar": {"0.2.0": "Spring Boot >=3.0.0 and <3.2.0-M3"},"pulsar-reactive": {"0.2.0": "Spring Boot >=3.0.0 and <3.2.0-M1"},"camel": {"3.14.9": "Spring Boot >=2.6.0 and <2.7.0-M1","3.20.6": "Spring Boot >=2.7.0.M1 and <3.0.0-M1","4.1.0": "Spring Boot >=3.0.0-M1 and <3.2.0-M1"},"picocli": {"4.7.4": "Spring Boot >=2.6.0 and <3.1.0-M1"}}}
demo版本保持和教程一致,避免不必要的麻烦
框架 版本 cloud Hoxton.SR1 boot 2.2.RELEASE cloud alibaba 2.1.0.RELEASE java Java8 Maven 3.5及以上 SpringCloud的停更策略
Nacos能替换掉原来SpringCloud中的服务注册中心、服务配置中心和消息总线,干翻了Eureka、Config和Bus
停更不停用
被动更新【不是致命bug不修】,git上的代码合并请求不受理,不再发布新版本
Cloud升级到H版的更新点
服务注册中心
停用Eureka【重度患者,进ICU】,可选的替代品有
Zookeeper【老系统用Dubbo做服务调用,Zookeeper很适合做老项目的服务注册中心替代Eureka】、
Consul【go语言实现的框架,不推荐使用】、
Nacos【经过百万级并发量考验,不仅能替换Eureka,还能替换其他一些组件,非常重要】
负载均衡
Ribbon停更了【轻度患者】,但是现行的版本还在使用,
Spring希望用LoadBalancer逐渐取代Ribbon
服务调用
最初做服务调用的Feign也几乎停用了
现在的替代品是OpenFeign
服务降级
Hystrix,SpringCloud原生自带的熔断降级框架正在被大规模使用,但是官网不再使用
其中的设计理念:服务熔断、服务降级、服务限流、服务隔离思想很值得借鉴
国外现在使用广泛的替代品是resilience4j【4j表示for java】,但国内使用很少
国内有望替换Hystrix的产品是SpringCloud Alibaba Sentinel【实现熔断和限流,非常好用】
服务网关
Zuul【服务网关作为总的服务接入口,做服务的协调、调度】,网飞的Zuul2没弄成,基本出不来
Spring自身出了Gateway作为Zuul的替代,现在使用也很广泛
服务配置
Config也停用了
携程的阿波罗appollo还可以
主流还是使用Nacos
服务总线
服务总线原生Bus消息总线也被Nacos替换
SpringCloud文档
最权威的就是官网上对应版本号的官方文档
英文文档
中文文档
对应SpringBoot2.2.2的官方文档
微服务搭建
使用Mybatis+SpringBoot搭建订单-支付两个存在调用关系的微服务模块
约定>配置>编码
约定:Java规范、SQL语句规范、Git提交流程...
配置:组件选型
编码:业务组件落地
创建父工程
第一步,创建maven工程,页面原型选择site结尾的原型,maven不要选择IDEA默认的maven
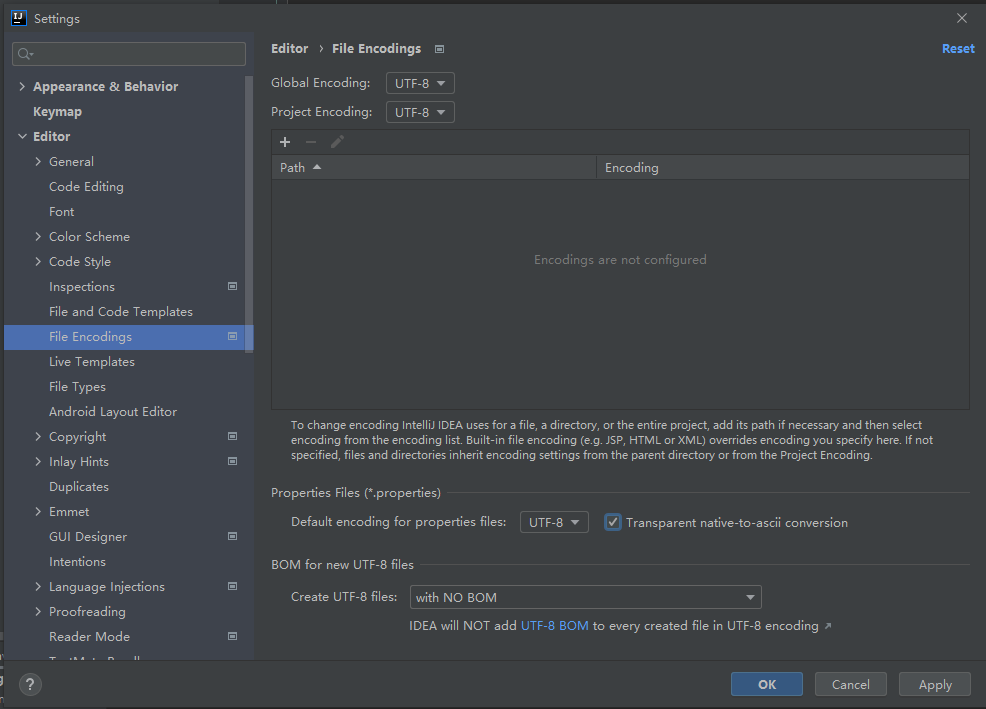
第二步,设置项目字符编码格式为UTF-8
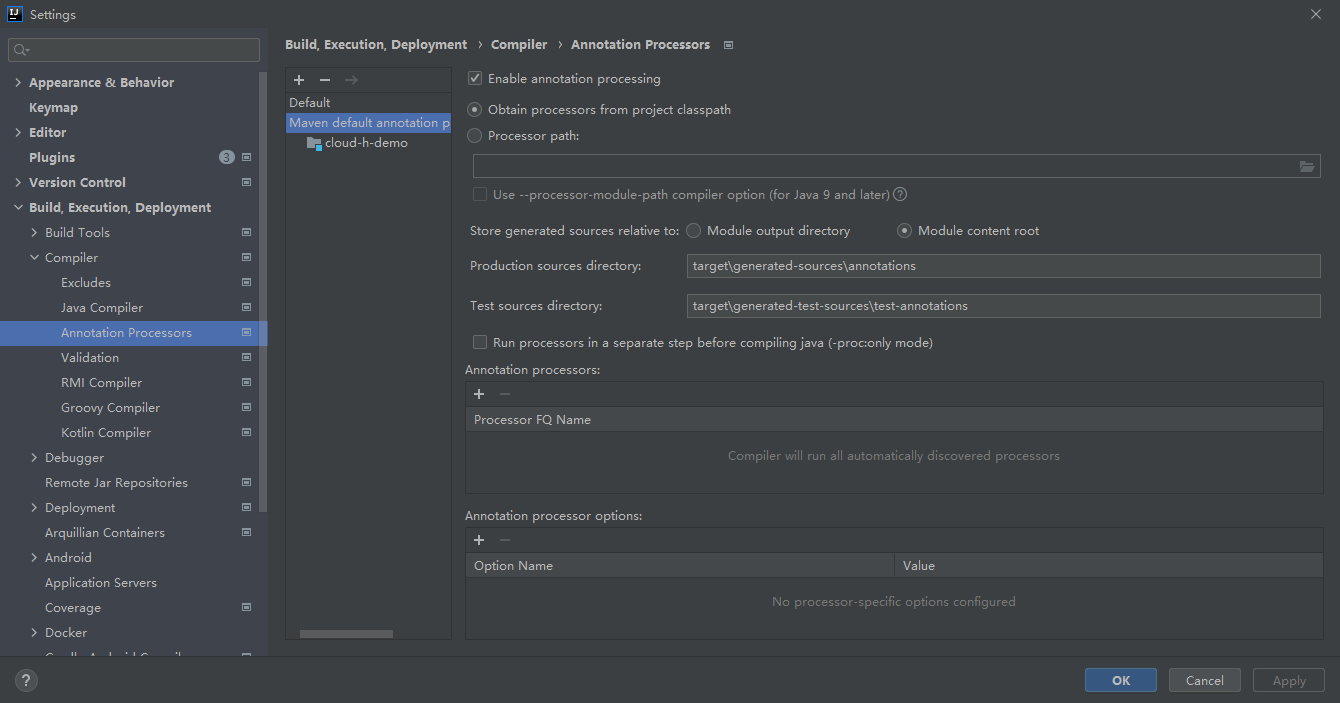
第三步,开启注解生效激活
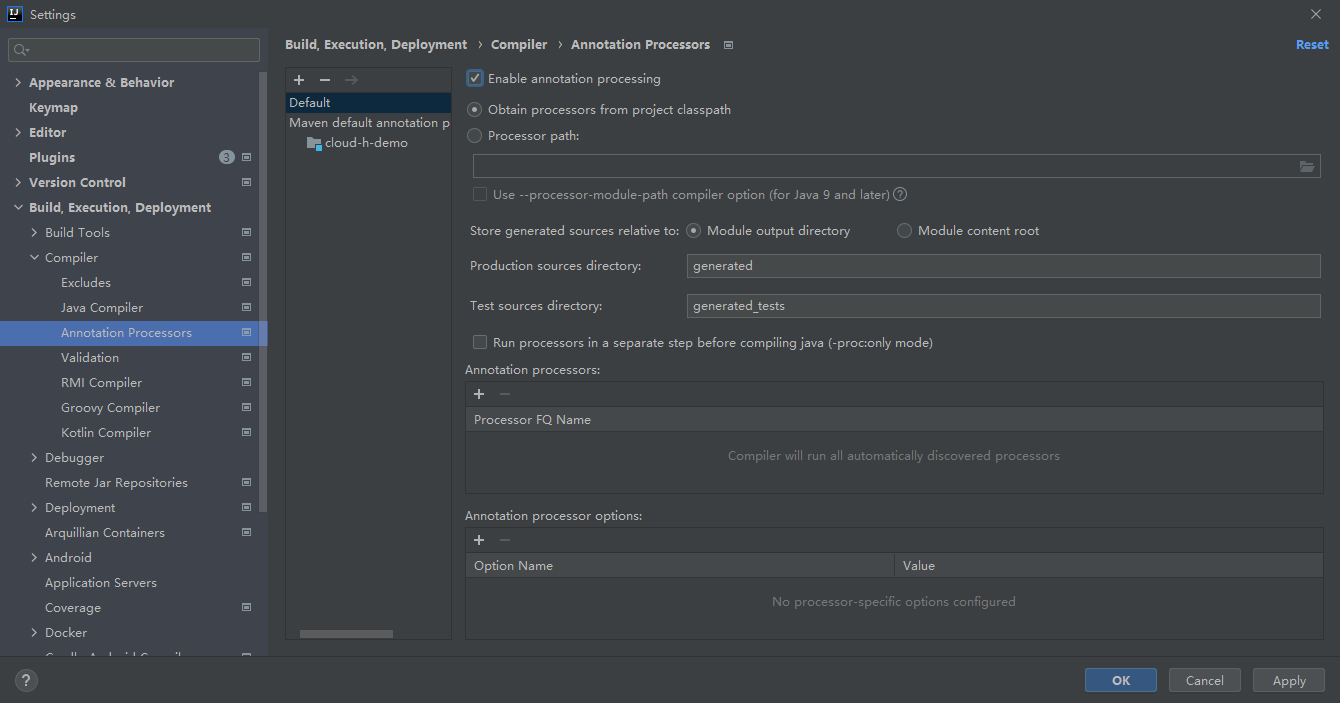
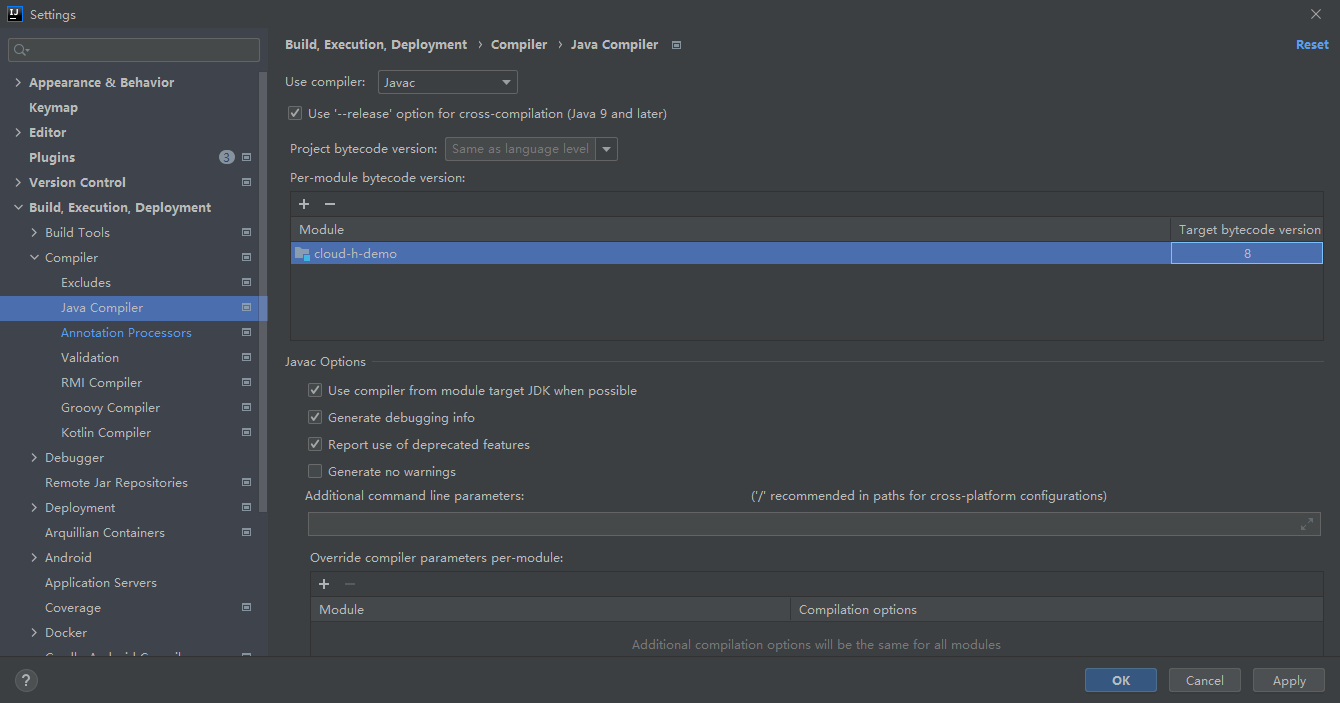
第四步,开启Java8编译
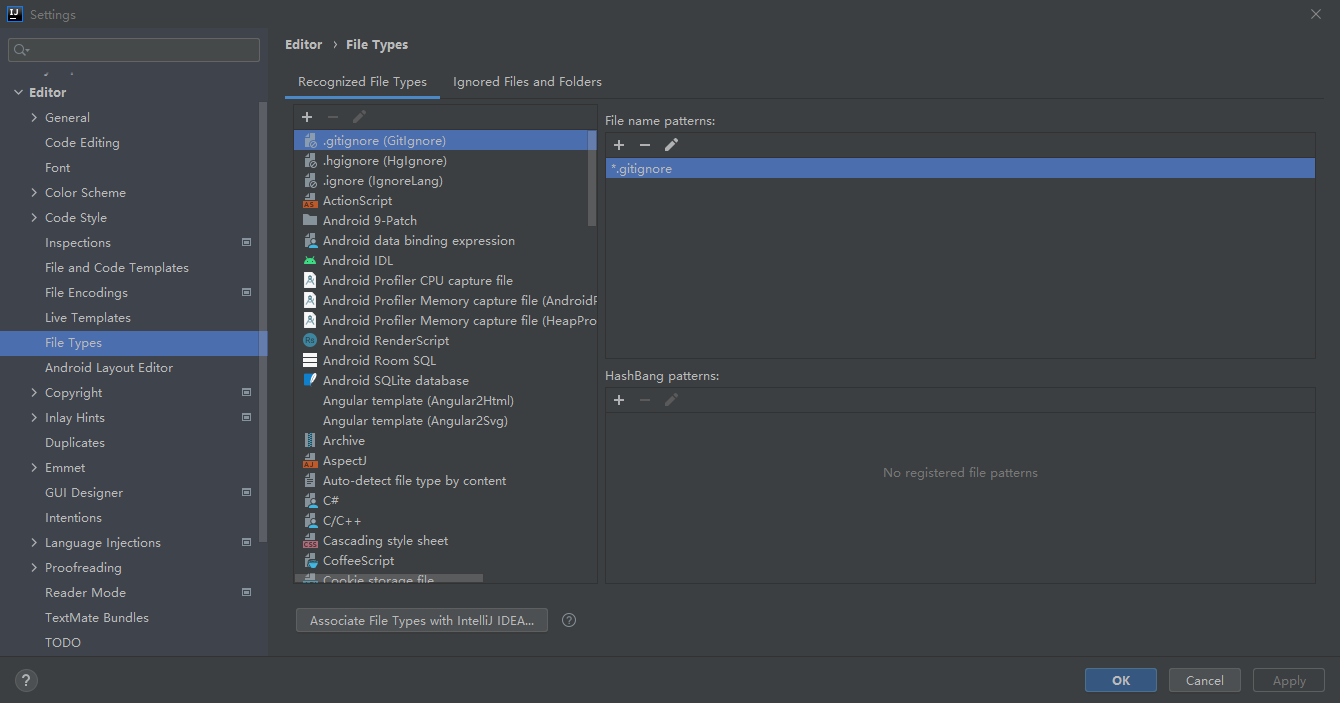
第五步,选择fileType过滤,目录结构中不显示特定后缀名的文件【个人习惯,可以不设置】
3.设置父工程的pom.xml
删除父工程的src目录
dependencyManagement和dependencies的区别
dependencyManagement:
通常会在一个组织或者项目的最顶层的父POM中看到dependencyManagement
能让所有在子项目中引用一个依赖而不用显示的列出版本号,Maven会沿着父子层次向上直到找到拥有dependencyManagement元素的项目,自动使用dependencyManagement元素中指定的版本号,
好处是所有的子项目都是采用父容器规定的版本号,无需每个子版本都进行声明,子版本需要另外版本可以在子项目中单独声明
dependencyManagement只是声明依赖,并不会引入,子项目需要显示声明需要用到的依赖
由于本机mysql的版本是mysql8.0.27,这里更改了mysql驱动的版本
dependencies是真正的引入依赖,通常在子模块中使用
x <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion>
<groupId>com.atlisheng</groupId> <artifactId>cloud-h-demo</artifactId> <version>1.0-SNAPSHOT</version> <packaging>pom</packaging>
<!--统一管理jar包的版本--> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <!--老四件套--> <junit.version>4.12</junit.version> <log4j.version>1.2.17</log4j.version> <lombok.version>1.16.18</lombok.version> <mysql.version>8.0.27</mysql.version> <!--mybatis和德鲁伊的版本号--> <druid.version>1.1.16</druid.version> <mybatis.spring.boot.version>1.3.0</mybatis.spring.boot.version> </properties>
<!--子模块继承后提供:锁定版本+子模块不用写groupId和version--> <dependencyManagement> <!--dependencyManagement和dependencies的区别 dependencyManagement:通常会在一个组织或者项目的最顶层的父POM中看到dependencyManagement, 能让所有在子项目中引用一个依赖而不用显示的列出版本号,Maven会沿着父子层次向上直到找到拥有dependencyManagement元素的项目,自动使用 dependencyManagement元素中指定的版本号,好处是所有的子项目都是采用父容器规定的版本号,无需每个子版本都进行声明,子版本需要另外版本 可以在子项目中单独声明 dependencyManagement只是声明依赖,并不会引入,子项目需要显示声明需要用到的依赖 由于本机mysql的版本是mysql8.0.27,这里更改了mysql驱动的版本 dependencies是真正的引入依赖,通常在子模块中使用 --> <dependencies> <!--springboot 2.2.2--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.2.2.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <!--spring cloud Hoxton.SR1--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <!--spring cloud alibaba 2.1.0.RELEASE--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>${druid.version}</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>${mybatis.spring.boot.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> <optional>true</optional> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <!--plugin提示fork不可用,加一个和springboot一样的版本号,但是2.2.2RELEASE提示不存在,这里用最近的2.2.1--> <version>2.2.1.RELEASE</version> <configuration> <fork>true</fork> <addResources>true</addResources> </configuration> </plugin> </plugins> </build></project>【点击闪电掉过maven的测试阶段】
不知道有啥用,作用是跳过测试阶段,但是原因不清楚
编写业务
controller-service-dao-mysql
一个应用启动后在IDEA中的run空间,多个微服务开启后IDEA最好用的是run DashBoard,没有该功能需要开启,可以在finish中自动启动上次关闭的所有微服务,这个功能很强
新版本叫做services,点击Views--Tool Windows--services可以打开services窗口【或者快捷键
alt+8】,默认界面不显示任何服务,需要配置add Configuration Type为SpringBoot,会自动导入正在运行的SpringBoot项目也可以通过修改IDEA的.idea/workspace.xml的方式快速打开Run Dashboard窗口,替换掉workspace.xml下name为configurationTypes的整个option为以下内容,上一步操作成功该配置文件会自动出现该内容
xxxxxxxxxx<component name="RunDashboard"><option name="configurationTypes"><set><option value="SpringBootApplicationConfigurationType" /></set></option></component>
【创建子模块01-provider-payment】
【pom.xml】
xxxxxxxxxx <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>cloud-h-demo</artifactId> <groupId>com.atlisheng</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion>
<artifactId>01-provider-payment</artifactId>
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties>
<dependencies> <!--包含了sleuth+zipkin--> <!--<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>--> <!--eureka-client--> <!--<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency> <!--mysql-connector-java--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!--jdbc--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies></project>
建数据库表
使用cloud_h_demo作为数据库
字段名必须用`包围,不能用单引号,否则报错
xxxxxxxxxxCREATE TABLE `payment` (`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',`serial` VARCHAR(200) DEFAULT '',PRIMARY KEY(`id`))ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mybatis+springboot的基本业务结构
业务结构总览
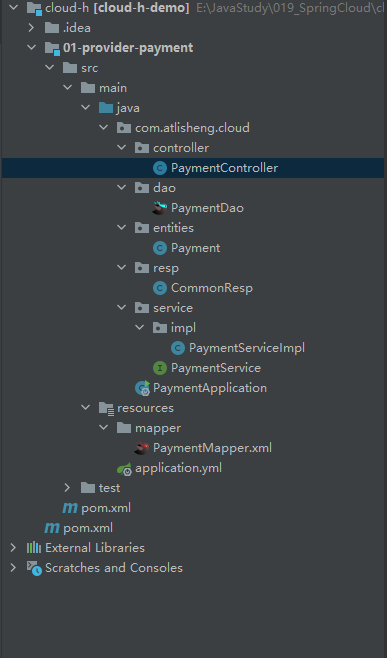
启动类
xxxxxxxxxxpublic class PaymentApplication {public static void main(String[] args) {SpringApplication.run(PaymentApplication.class,args);}}application.yml
xxxxxxxxxxserver:port: 8001spring:application:name: service-paymentdatasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/cloud_h_demo?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8&useSSL=falsepassword: Haworthia0715username: rootmybatis:mapper-locations: classpath:mapper/*.xml#所有entities所在的包type-aliases-package: com.atlisheng.cloud.entitiesentity
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 主实体:对应数据库中的payment表* 实现Serializable接口在分布式部署中可能用的上* @创建日期 2023/10/20* @since 1.0.0*/public class Payment implements Serializable {/***主键,使用Long对应数据库表中的BIGINT*/private Long id;/****/private String serial;}dao
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 原则上各种增删改查的方法都要写上* @创建日期 2023/10/20* @since 1.0.0*/public interface PaymentDao {public int create(Payment payment);public Payment getPaymentById(("id") Long id);}mapper.xml
xxxxxxxxxx<!--指定映射哪个Dao接口--><mapper namespace="com.atlisheng.cloud.dao.PaymentDao"><!--id对应映射的方法,parameterType="Payment"指定参数封装的entity实体类或者基本数据类型useGeneratedKeys="true" Mybatis 配置文件 useGeneratedKeys 参数只针对 insert 语句生效,默认为 false。当设置为true 时,表示如果插入的表以自增列为主键,则允许 JDBC 支持自动生成主键,并可将自动生成的主键返回给实体类的对应属性。keyProperty="id"指定主键值赋值给对象的哪个属性,此处表示将主键值赋值给插值Payment对象的id属性--><insert id="create" parameterType="Payment" useGeneratedKeys="true" keyProperty="id">insert into payment(serial) values (#{serial});</insert><!--column:数据库字段名,property映射属性名,jdbcType:字段数据类型--><resultMap id="BaseResultMap" type="com.atlisheng.cloud.entities.Payment"><id column="id" property="id" jdbcType="BIGINT"/><id column="serial" property="serial" jdbcType="VARCHAR"/></resultMap><select id="getPaymentById" parameterType="Long" resultMap="BaseResultMap">select * from payment where id=#{id};</select></mapper>service
【接口】
xxxxxxxxxxpublic interface PaymentService {public int create(Payment payment);public Payment getPaymentById(("id") Long id);}【实现类】
xxxxxxxxxxpublic class PaymentServiceImpl implements PaymentService {/***Resource注解是java自带的,@Autowire是Spring自带的,使用@Resource也能实现自动注入* 由于@Mapper注解不是Spring自带的,使用Autowire注解Spring会认为不能注入从而标红,但是实际运行没有问题,* 在Dao上用@Component注解使用@Autowire就不会显示异常*/private PaymentDao paymentDao;public int create(Payment payment){return paymentDao.create(payment);}public Payment getPaymentById(("id") Long id){return paymentDao.getPaymentById(id);}}通用响应类
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 通用返回类* @创建日期 2023/10/20* @since 1.0.0*/public class CommonResp<T> {//实际上响应码用枚举更加符合规范private Integer code;private String message;private T data;/*** @param code* @param message* @return* @描述 有参构造,还可以设置方法返回this达到链式变成的效果* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public CommonResp(Integer code,String message){this(code,message,null);}}前端控制器
xxxxxxxxxx//用于日志打印,自动注入log对象public class PaymentController {private PaymentService paymentService;("/payment/create")public CommonResp create(Payment payment){int result=paymentService.create(payment);log.info("插入结果:"+result);return result>0?new CommonResp(200,"数据插入成功",result):new CommonResp(505,"插入数据库失败");}("/payment/get/{id}")public CommonResp getPaymentById( Long id){Payment payment = paymentService.getPaymentById(id);log.info("查询结果:"+payment);return payment!=null?new CommonResp(200,"查询成功",payment):new CommonResp(505,"没有对应ID的记录"+id);}}
测试
分布式相关的配置需要注释掉,因为配置文件中确实部分配置,启动会报错
测试插入记录和查询记录功能正常
DevTools热部署
代码改动以后自动生效,不需要再手动重启项目,热部署除了
devtools还可以使用jrebel
引入热部署
第一步:引入devtools组件jar包
xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency>第二步:开启项目自动构建和编译
第三步:快捷键
shift+ctrl+alt+/打开Maintenance菜单的Registry,勾选下列两个选项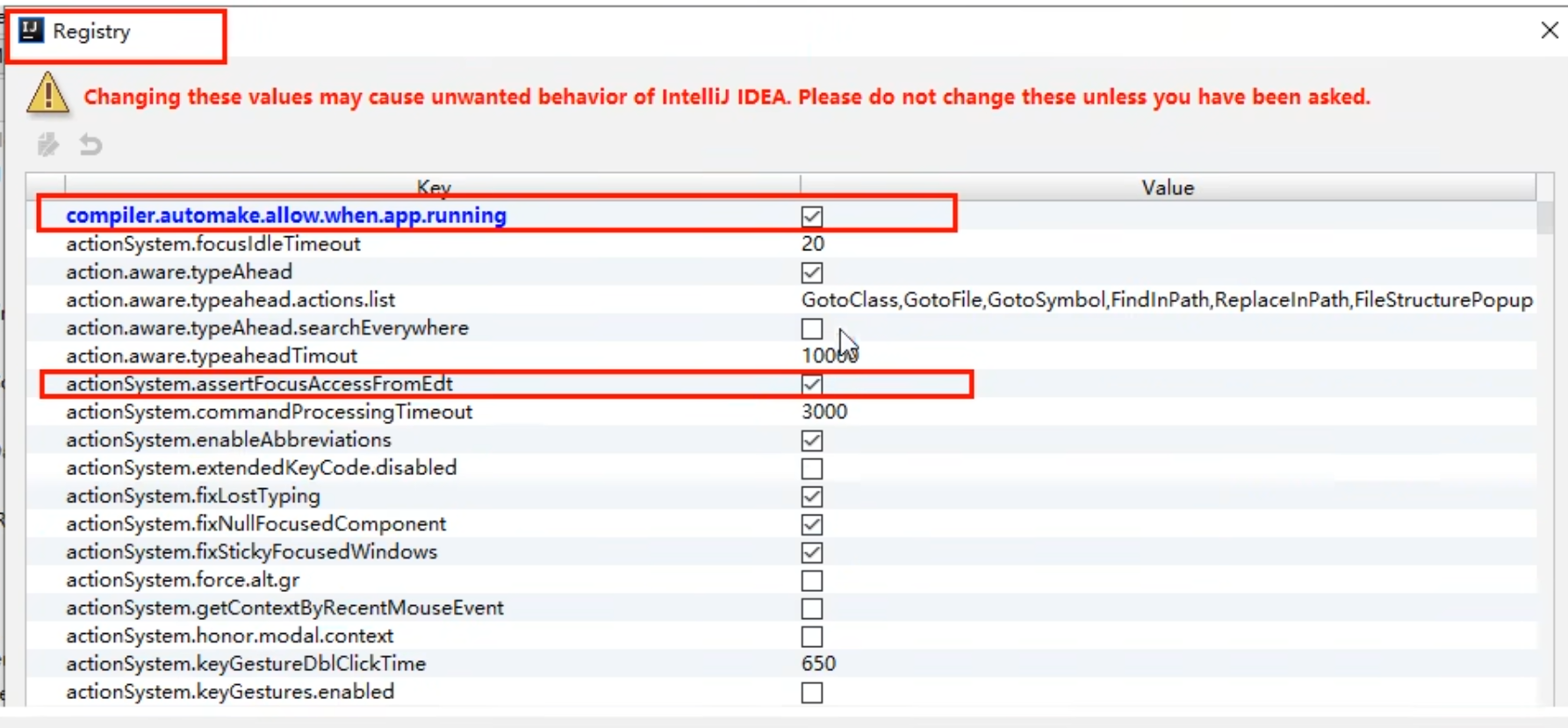
第四步:重启IDEA
效果:更新完不会立即重启,更新完再次发送请求时会立即重启再执行请求【这个老杜讲过,假热部署】
这个配置只允许在开发阶段,生产环境这个功能必须关闭
创建第二个微服务
02-consumer-order
创模块--写pom--写yml--启动类--业务类
逻辑是订单服务对支付服务进行调用
项目结构
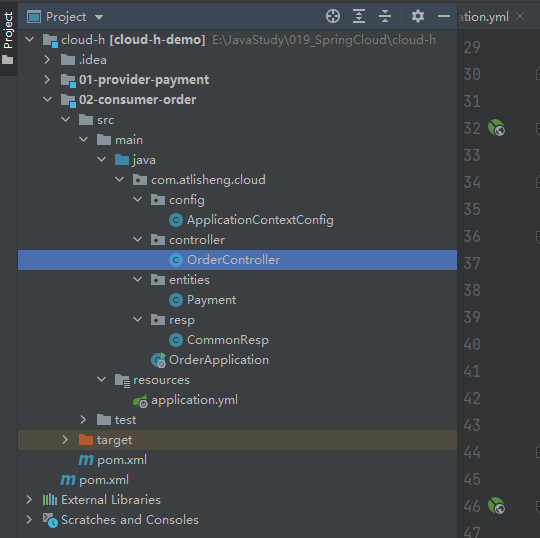
pom.xml
xxxxxxxxxx<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>cloud-h-demo</artifactId><groupId>com.atlisheng</groupId><version>1.0-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><!--继承了父工程子模块就不用写ga坐标了--><artifactId>02-consumer-order</artifactId><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!--包含了sleuth+zipkin--><!--<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId></dependency>--><!--<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies></project>application.yml
xxxxxxxxxxserverport80 #用户支付下订单的模块用户不应该关心输入哪个端口进行访问,浏览器网页服务的默认端口都是80,只需要输入网址,不需要输入:80,提升用户体验config
【ApplicationContextConfig】
xxxxxxxxxxpublic class ApplicationContextConfig {/*** @return {@link RestTemplate }* @描述 注入RestTemplate对象* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public RestTemplate getRestTemplate(){return new RestTemplate();}}controller
【OrderController】
xxxxxxxxxxpublic class OrderController {public static final String PAYMENT_URL="http://localhost:8001";private RestTemplate restTemplate;/*** @param payment* @return {@link CommonResp }<{@link Payment }>* @描述 RestTemplate发送post请求对其他服务进行调用,参数以对象的形式传入* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/create")public CommonResp<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL+"/payment/create",payment,CommonResp.class);}/*** @param id* @return {@link CommonResp }<{@link Payment }>* @描述 RestTemplate发送Get请求对其他服务进行调用,参数直接拼接在url尾部* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/get/{id}")public CommonResp<Payment> getPayment( Long id){return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id,CommonResp.class);}}entities
【Payment】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 主实体:对应数据库中的payment表* 实现Serializable接口在分布式部署中可能用的上* @创建日期 2023/10/20* @since 1.0.0*/public class Payment implements Serializable {/***主键,使用Long对应数据库表中的BIGINT*/private Long id;/****/private String serial;}resp
【CommonResp】
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 通用返回类* @创建日期 2023/10/20* @since 1.0.0*/public class CommonResp<T> {private Integer code;private String message;private T data;/*** @param code* @param message* @return* @描述 有参构造,还可以设置方法返回this达到链式变成的效果* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public CommonResp(Integer code, String message){this(code,message,null);}}
整合公共类、第三方接口、工具类等公共服务可以放在common模块下供各个服务调用
该模块不对外提供接口,供各服务类调用
常见整合的服务组件:dev-tool、lombok、hutool-all【糊涂工具包,处理时间日期格式】
把公共类如entity【本人更倾向于vo、bo类】、工具类移动到该模块下,在其他模块中对该类进行引用
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.1.0</version></dependency></dependencies>
common模块创建之后要被其他模块使用需要用maven的
mvn clean install先安装部署到本地仓库,再去各个子模块下的pom文件中引入
RestTemplate
RestTemplate是Spring提供的用于访问Rest服务的客户端模板工具集,是一种简单边界的访问restful服务模板类,对HttpClient进行了封装,提供多种便捷访问远程Http服务的方法【类似于JDBCTemplate和redisTemplate】
RestTemplate的官方文档:https://docs.spring.io/spring-framework/docs/5.2.2.RELEASE/javadoc-api/org/springframework/web/client/RestTemplate.html
RestTemplate的使用
使用RestTemplate访问restful接口仅需三个参数
url:REST请求地址
requestMap:请求参数
ResponseBean.class:HTTP响应转换被转换成的对象类型
使用RestTemplate需要向容器中进行注入
xxxxxxxxxxpublic class ApplicationContextConfig {/*** @return {@link RestTemplate }* @描述 注入RestTemplate对象* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public RestTemplate getRestTemplate(){return new RestTemplate();}}RestTemplate的API
注意:只要调用端Order服务封装响应数据类和被调用端响应数据类的全限定类名和类结构相同,数据就会被自动传递封装成对应类型;经过测试名字不同,包名不同,结构相同一样能够封装完整数据
RestTemplate的post提交被调用方的对应参数必须使用@RequestBody注解:使用RestTemplate的post方式请求插入数据,如果被请求方法的参数没有@RequestBody注解修饰是无法获取到传递过去的请求参数的
RestTemplate还有很多方法,慢慢总结吧
xxxxxxxxxxpublic class OrderController {public static final String PAYMENT_URL="http://localhost:8001";private RestTemplate restTemplate;/*** @param payment* @return {@link CommonResp }<{@link Payment }>* @描述 01.RestTemplate发送post请求对其他服务进行调用,参数以对象的形式传入* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/create")public CommonResp<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL+"/payment/create",payment,CommonResp.class);}/*** @param id* @return {@link CommonResp }<{@link Payment }>* @描述 02.RestTemplate发送Get请求对其他服务进行调用,参数直接拼接在url尾部* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/get/{id}")public CommonResp<Payment> getPayment( Long id){return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id,CommonResp.class);}}RestTemplate的post提交
使用RestTemplate的post方式由服务发送的请求被调用方的参数必须有@RequestBody注解参数才能被获取封装,否则获取不到参数,数据库插入null,但是服务器不报错
注意,即便调用方是Get请求只要能封装成Payment对象,也不影响调用方对RestTemplate的Post请求参数的接收,就是完全可以调用方接收get请求的参数,然后封装数据单独发送post请求给被调用方
【调用方】
xxxxxxxxxx("/consumer/payment/create")public CommonResponse<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL+"/payment/create",payment, CommonResponse.class);}【被调用方】
xxxxxxxxxx("/payment/create")public CommonResp create( Payment payment){int result=paymentService.create(payment);log.info("插入结果:"+result);return result>0?new CommonResp(200,"数据插入成功",result):new CommonResp(505,"插入数据库失败");}【添加@RequestBody注解前后效果】
服务注册与发现
Eureka
重点:分布式CAP理论
Eureka虽然官网停止更新,但是大部分老项目还在使用,
Eureka简介
SpringCloud封装了Netflix公司开发的Eureka模块来实现服务治理,
服务注册与发现
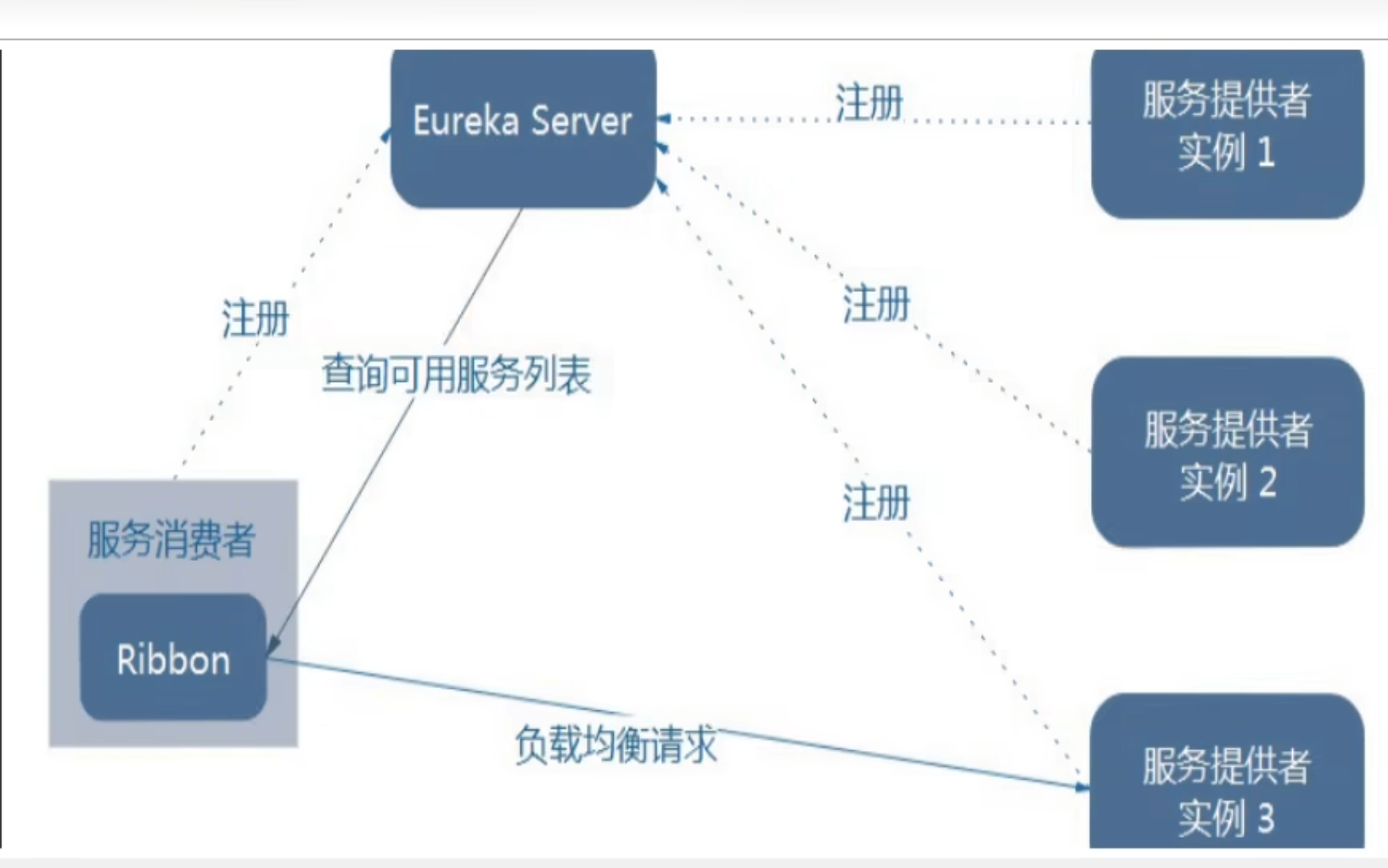
Eureka Server作为服务注册功能的服务器是服务注册中心,系统中的其他微服务使用Eureka的客户端连接到Eureka Server并维持心跳连接,系统的维护人员通过Eureka Server来监控系统中各个微服务是否正常工作
服务器启动时会把服务器信息,如服务通讯地址,服务器信息以别名的方式注册到注册中心,消费者以该别名去注册中心获取到实际的服务通讯地址,再实现本地RPC远程调用;
核心在于用注册中心管理服务与服务的依赖关系,任何RPC远程框架都会有一个用于存放服务接口地址相关的信息
服务调用者的访问对象可能是注册中心集群,也可能是服务提供者集群,避免单点故障造成系统挂掉;Dubbo的注册中心是Zookeeper
整个服务注册和服务发现的流程
服务提供者支付服务启动时将服务器信息【地址别名】注入Eureka服务器
消费者订单服务【调用者是不是可以不注册,只开发拉取服务提供者信息功能即可】使用服务别名去注册中心获取实际的RPC远程调用地址
消费者获取调用地址后,利用HttpClient技术实现远程调用
消费者获取服务地址后会将服务地址缓存在本地JVM内存中,每隔30秒更新一次服务调用地址
Eureka的两个组件
Eureka Server:提供服务注册服务
各微服务节点启动后会在Eureka Server中注册,其中的服务注册表会存储所有可用服务节点的信息,该信息可以在界面中直观看到
服务注册:将服务信息注册进注册中心
服务发现:从注册中心上获取服务信息
实质就是将服务信息以key【服务名】-value【调用地址】键值对的方式将服务信息进行存储
Eureka Client:通过注册中心访问
是一个用于简化Eureka Server交互的Java客户端,该客户端具备一个内置的、使用轮询负载算法的负载均衡器,应用启动阶段会以30s为周期向Eureka Server发送心跳,如果Eureka Server在多个心跳周期内【默认是90s】没有接收到某个节点的心跳,EurekaServer会自动将该服务节点从服务注册中心中将该节点移除
Eureka单机构建
构建Eureka单个服务器作为订单模块和支付模块的注册中心
构建步骤:
module--pom--yml--启动类--业务类
服务结构
pom.xml
需要引入netflix-eureka-server依赖,这玩意儿单指Eureka Server,client貌似是在各个微服务中安装的
xxxxxxxxxx<dependencies><!--eureka-server:Eureka服务器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>${project.version}</version></dependency><!--boot web actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--actuator用於图形监控,swagger和豪猪哥都要用到这个--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--一般通用配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId></dependency></dependencies>application.yml
xxxxxxxxxxserverport7001eurekainstancehostnamelocalhost #eureka服务端的实例名称,会用于其他服务对Eureka Server的访问,用于指定Eureka服务器的ipclient#register-with-eureka为false表示不想注册中心注册自己,默认就是falseregister-with-eurekafalse#fetch-registry为false表示自己端就是注册中心,职责是维护服务实例,不需要去检索查询调用服务fetch-registryfalseservice-url#设置与Eureka Server交互的地址,查询服务和注册服务都需要该地址defaultZonehttp//$eureka.instance.hostname$server.port/eureka/启动类
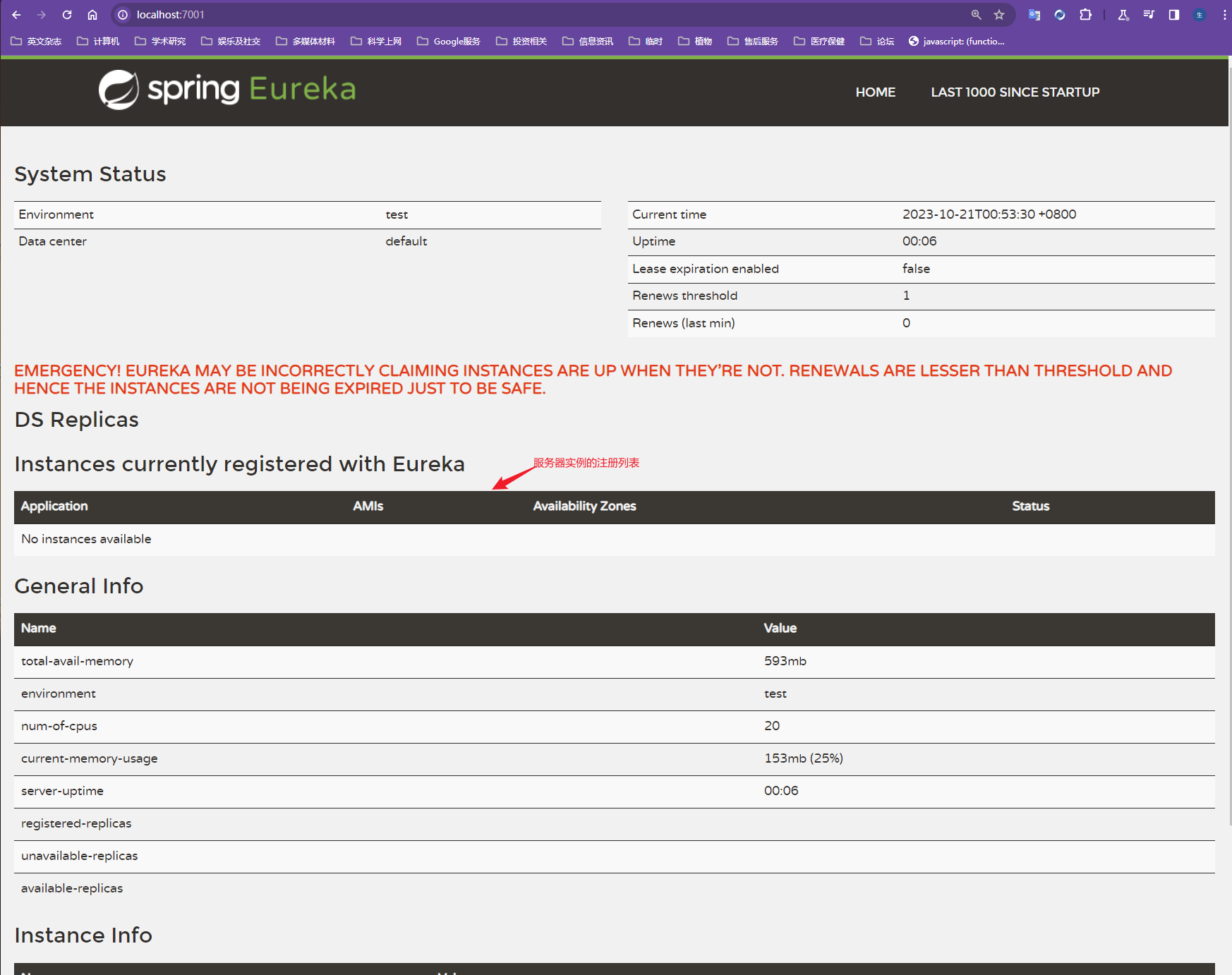
xxxxxxxxxx//使用@EnableEurekaServer注解标注该启动类为服务注册中心,不需要写其他的业务代码,Eureka会自动执行相关组件管理服务public class EurekaApplication {public static void main(String[] args){SpringApplication.run(EurekaApplication.class,args);}}前端页面
DS Replicas指的是在该Eureka服务器上注册的其他Eureka服务器
将微服务配置到Eureka单机服务器中
在微服务中引入Eureka Client的依赖
xxxxxxxxxx<!--老版本使用spring-cloud-starter-eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-eureka</artifactId></dependency><!--H版使用netflix-eureka-client--><!--eureka-server:Eureka服务器--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency>在每个微服务配置类中添加对Eureka的配置
Eureka的配置太多,客户端和服务端都要用户创建和配置,是否抓取和注册都要在每个服务器中注册,不好统一管理且配置麻烦,导致Eureka被Nacos替代,而且调用服务的代码全部写了一大坨在控制器方法中,脱离了封装的初衷
xxxxxxxxxx#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-urldefaultZonehttp//localhost7001/eureka在每个微服务启动类上使用@EnableEurekaClient注解
xxxxxxxxxxpublic class OrderApplication {public static void main(String[] args){SpringApplication.run(OrderApplication.class,args);}}xxxxxxxxxxpublic class PaymentApplication {public static void main(String[] args) {SpringApplication.run(PaymentApplication.class,args);}}
Eureka Server的访问地址中出现对应的微服务列表,即配置成功
Eureka集群构建
没有服务集群的高可用一定会带来单点故障的问题【nginx和redis中讲过】
微服务RPC远程服务调用最核心的是高可用,单机Eureka爆炸整个服务系统都会不可用
解决高可用问题的办法就是搭建Euraka注册中心集群,实现负载均衡和故障容错
一般三个服务中心就顶天了
Eureka集群架构的重点是Eureka Server集群对外暴露为Eureka服务器整体,内部相互注册【在本机上记录其他Eureka服务器信息】,服务集群对外暴露服务名,不需要指定特定的ip和端口,通过集群服务名和RestTemplate的@LoadBanlanced实现服务调用和默认轮询的负载均衡策略
构建原理
对外统一被称作Eureka,内部机器相互注册【本台机器一定要有Eureka集群中其他机器的服务器信息】,对外暴露组成一个整体
构建步骤
参考7001Eureka Server再创建一个7002Eureka Server
修改映射配置:在c:\windows\System32\drivers\etc\hosts文件中添加配置映射到hosts文件中,方便区分
原因是单机情况下localhost对应一台,集群情况下,用一台机器模拟修改映射能更加方便区分【?不改可以吗】,多台Eureka服务器相应配置多台,改了之后使用localhost不使用映射同样可以访问
xxxxxxxxxx127.0.0.1 eureka7001.com127.0.0.1 eureka7002.com修改两个Eureka Server的yml文件配置,达到相互注册的效果
单机版写法:地址查询和注册服务依赖的地址填写的自身
集群版写法:hostname更改为在windows中映射配置的名字,在defaultZone属性添加其他Eureka服务器地址,超过三台通过逗号分隔配置
xxxxxxxxxxserverport7001eurekainstancehostnameeureka7001.com #eureka服务端的实例名称,会用于其他服务对Eureka Server的访问,用于指定Eureka服务器的ipclient#register-with-eureka为false表示不想注册中心注册自己,默认就是falseregister-with-eurekafalse#fetch-registry为false表示自己端就是注册中心,职责是维护服务实例,不需要去检索查询调用服务fetch-registryfalseservice-url#设置与Eureka Server交互的地址,查询服务和注册服务都需要该地址,单机Eureka交互地址指向自己#defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/#Eureka集群交互地址指向集群中的其他兄弟defaultZonehttp//eureka7002.com7002/eureka/#超过三台Eureka服务器直接通过逗号分隔其他Eureka服务器地址#defaultZone: http://eureka7002.com::${server.port}/eureka/,http://eureka7003.com::${server.port}/eureka/xxxxxxxxxxserverport7002eurekainstancehostnameeureka7002.com #eureka服务端的实例名称,会用于其他服务对Eureka Server的访问,用于指定Eureka服务器的ipclient#register-with-eureka为false表示不想注册中心注册自己,默认就是falseregister-with-eurekafalse#fetch-registry为false表示自己端就是注册中心,职责是维护服务实例,不需要去检索查询调用服务fetch-registryfalseservice-url#设置与Eureka Server交互的地址,查询服务和注册服务都需要该地址#defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/defaultZonehttp//eureka7001.com7001/eureka/启动Eureka服务器集群并测试
注意关闭梯子,有梯子只能通过localhost进行访问,无法通过别名映射访问
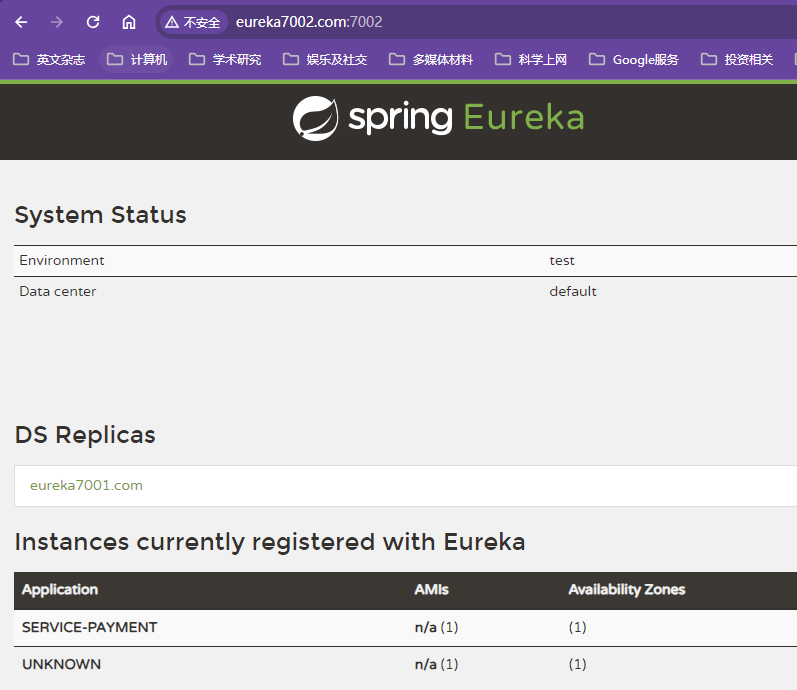
将微服务配置到Eureka集群中
在每个微服务中引入netflix-eureka-client依赖
修改微服务配置文件的defaultZone查询服务地址,注册地址为全体Eureka服务器,用逗号进行分隔
只需要修改defaultZone: http://eureka7001.com:7001/eureka,http://eureka7002.com:7002/eureka
xxxxxxxxxxserverport80 #用户支付下订单的模块用户不应该关心输入哪个端口进行访问,浏览器网页服务的默认端口都是80,只需要输入网址,不需要输入:80,提升用户体验#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-url#defaultZone: http://localhost:7001/eureka#集群版defaultZonehttp//eureka7001.com7001/eureka,http//eureka7002.com7002/eurekaxxxxxxxxxxserverport8001springapplicationnameservice-paymentdatasourcetypecom.alibaba.druid.pool.DruidDataSourcedriver-class-namecom.mysql.cj.jdbc.Driverurljdbcmysql//localhost3306/cloud_h_demo?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8&useSSL=falsepasswordHaworthia0715usernamerootmybatismapper-locationsclasspathmapper/*.xml#所有entities所在的包type-aliases-packagecom.atlisheng.cloud.entities#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-url#集群版defaultZonehttp//eureka7001.com7001/eureka,http//eureka7002.com7002/eureka在每个微服务启动类上使用@EnableEurekaClient注解
不写这个注解也能显示在Eureka服务列表中,经过测试
测试
项目启动时,先启动Eureka集群,再启动服务提供者provider,最后启动消费者consumer
测试服务调用没问题
效果
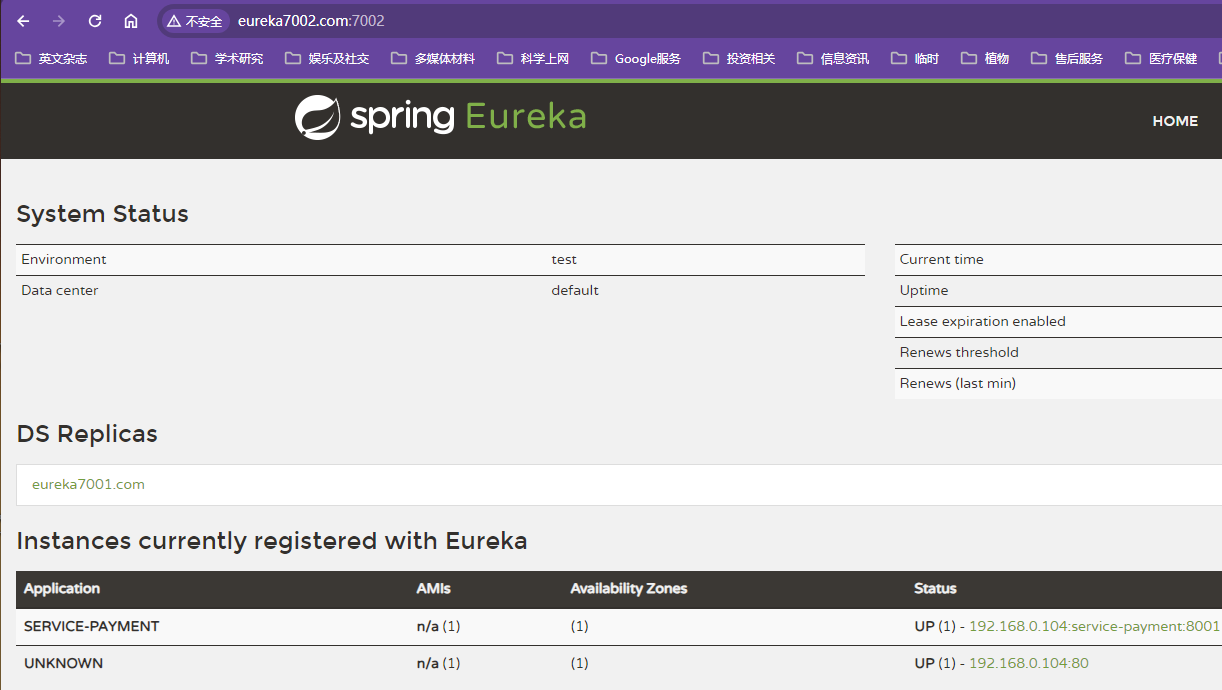
Eureka负载均衡
创建06-provider-payment组成支付服务集群测试Eureka负载均衡:Eureka默认的负载均衡策略就是轮询
当访问指定端口号服务器不走Eureka,访问对应的服务器;
如果使用调用者走Eureka对服务进行调用【注意要将调用服务的url的ip:port【http://localhost:8001】部分统一改成服务名称【http://service-payment】,即服务集群的url不能写死到端口,会导致只有固定端口的服务进行工作,无法达到负载均衡的效果】,服务对被调用者暴露为微服务名,同时必须在RestTemplate注入类上添加@LoadBalanced注解赋予RestTemplate负载均衡的能力,此时配置微服务名的服务集群调用才能生效
Ribbon和Eureka整合后消费者可以直接调用服务而不用关心地址和端口号,且整合了负载均衡的功能【默认轮询】
关键:
服务集群的url认服务名不认ip:端口,把ip和端口写死只能访问单个服务,必须写成http://服务名的形式是负载均衡的前提之一
必须在RestTemplate的注入方法上添加@LoadBalanced注解开启默认负载均衡策略
配置消费者调用服务的url
xxxxxxxxxx//public static final String PAYMENT_URL="http://localhost:8001";public static final String PAYMENT_URL="http://server-payment";private RestTemplate restTemplate;/*** @param payment* @return {@link CommonResp }<{@link Payment }>* @描述 RestTemplate发送post请求对其他服务进行调用,参数以对象的形式传入* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/create")public CommonResp<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL+"/payment/create",payment, CommonResp.class);}配置消费者的RestTemplate的@LoadBalanced注解开启默认负载均衡策略
这里用到的就是Ribbon的负载均衡功能,默认的策略就是轮询
xxxxxxxxxxpublic class ApplicationContextConfig {/*** @return {@link RestTemplate }* @描述 注入RestTemplate对象* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public RestTemplate getRestTemplate(){return new RestTemplate();}}测试
通过
http://localhost/consumer/payment/get/3在不同服务器同一个方法交替输出对应端口号信息展示出对应的轮询负载均衡策略
Actuator微服务信息完善
Actuator可以完善微服务信息,包括主机名称,访问信息IP提示等,可以不配置,配置以后看着更舒服
spring-boot-starter-web和spring-boot-starter-actuator是标配,一般一起进行导入,使用actuator对ip,端口等信息进行完善
Eureka的服务列表的status字段会显示主机名:集群服务名,使用Actuator设置去掉主机名【并配置自定义服务名称】
在微服务配置文件中添加属性eureka.instance.instance-id=自定义主机服务名字【一般都设置为服务名称:端口,ip信息在鼠标悬停浮动展示】
xxxxxxxxxx#eureka配置信息eurekainstance#actuator设置服务列表Status服务名instance-idorder80服务器布置多了以后需要关注机器编号、服务端口、服务类型
在微服务配置文件中添加属性eureka.instance.prefer-ip-address=true,实现鼠标悬停服务器展示ip和端口的效果
xxxxxxxxxx#eureka配置信息eurekainstance#actuator设置服务列表Status服务鼠标悬停浏览器左下角显示ip和端口prefer-ip-addresstrue
服务信息主动访问
通过DiscoveryClient对象可以主动获取并在程序中使用微服务主动注册在注册中心的服务信息,DiscoveryClient对象不要用@Autowire注解和@quelifier注解注入,只能使用@Resource进行注入,否则会报空指针
留意一下服务发现是什么概念,DiscoveryClient对服务注册信息访问时通过服务发现实现的
设置方式:
使用DiscoveryClient对象需要对应导入 org.springframework.cloud.client.discovery.DiscoveryClient包,不要导入网飞的那个包
在访问各个微服务信息的服务中的启动类上添加@EnableDiscoveryClient注解,在服务中调用以下方法获取所有微服务信息
注意@EnableEurekaClient几乎不咋用了,但是@EnableDiscoveryClient除了服务发现还有很多其他功能
discoveryClient.getServices():获取微服务列表的所有服务集群名称,返回字符串list集合discoveryClient.getInstances(String serviceName):通过服务集群的名字获取一个服务集群的服务实例列表,返回ServiceInstance类型的List集合serviceInstance.getServiceId():获取所属服务集群名称serviceInstance.getInstanceId():获取单个服务实例自定义名称serviceInstance.getHost():获取微服务所在主机ipserviceInstance.getPort():获取微服务所在端口serviceInstance.getUri():获取微服务访问Uri【协议://ip:端口】serviceInstance.getScheme():不知道Scheme是什么serviceInstance.getClass():获取单个微服务实例的数据封装类型【貌似是动态代理类】
xxxxxxxxxx("/payment/services")public Object getServices(){List<String> services = discoveryClient.getServices();for (String service:services) {List<ServiceInstance> instances = discoveryClient.getInstances(service);String serviceList=new String();for (ServiceInstance instance:instances) {serviceList=serviceList+instance.getServiceId()+"\t"+instance.getInstanceId()+"\t"+instance.getHost()+"\t"+instance.getPort()+"\t"+instance.getUri()+"\t"+instance.getScheme()+"\t"+instance.getMetadata()+"\t"+instance.getClass();}log.info("serviceName:"+service+"|serviceList:"+serviceList);}return this.discoveryClient;}【log.info输出信息】
xxxxxxxxxx2023-10-23 18:09:53.434 INFO 13376 --- [nio-8003-exec-6] c.a.cloud.controller.PaymentController :serviceName:service-payment|serviceList:SERVICE-PAYMENTpayment8002192.168.0.1048003http://192.168.0.104:8003null{management.port=8003}class org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient$EurekaServiceInstanceSERVICE-PAYMENTpayment8001192.168.0.1048001http://192.168.0.104:8001null{management.port=8001}class org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient$EurekaServiceInstance2023-10-23 18:09:53.434 INFO 13376 --- [nio-8003-exec-6] c.a.cloud.controller.PaymentController :serviceName:service-order|serviceList:SERVICE-ORDERorder80192.168.0.10480http://192.168.0.104:80null{management.port=80}class org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient$EurekaServiceInstancediscoveryClient所具备的所有信息
实际应该更加丰富,只是这里调用了toString方法,把属性处理成了服务名;【实际有很多东西,debug看都看不懂】
order是表示排序的,不用管
xxxxxxxxxx{"services": ["service-payment","service-order"],"order": 0}
Eureka自我保护
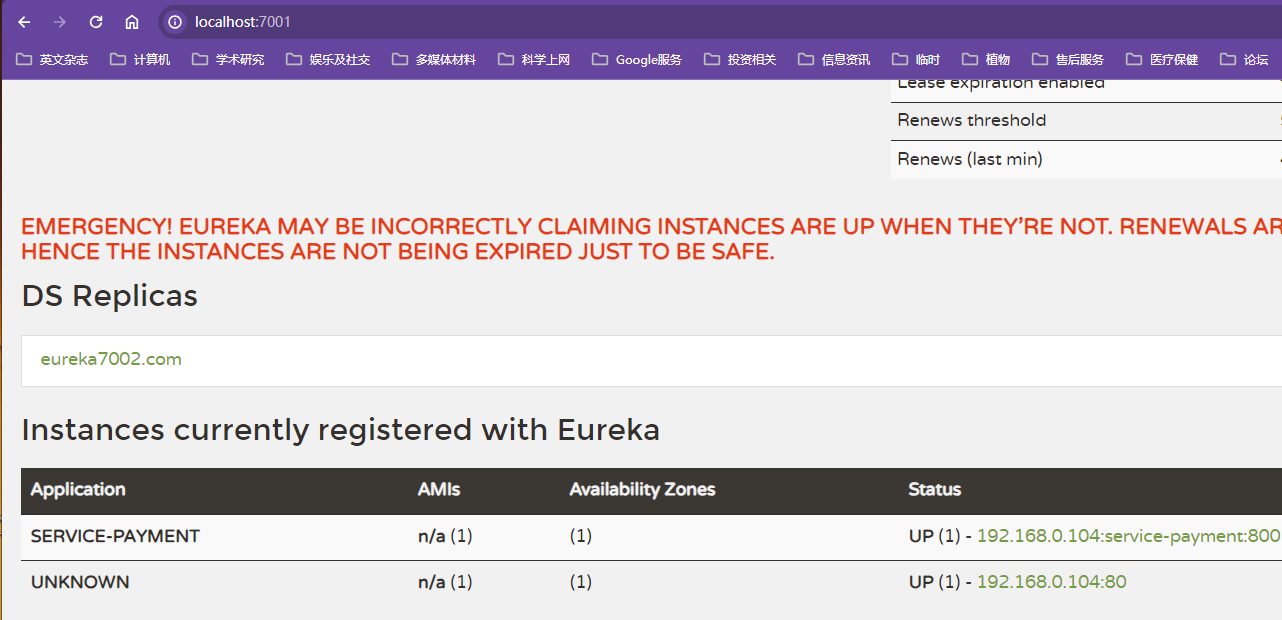
Eureka界面出现EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.说明Eureka进入了保护模式
保护模式主要用于一组客户端和Eureka Server建存在网络分区场景下的保护【某时刻一个微服务可能因为网络延迟等原因监测不到微服务实例的心跳包,Eureka不会立刻清理,依旧会对该微服务的信息进行保存,如果能恢复过来就继续正常使用,是一种高可用的设计思想,属于分布式CAP理论中的AP分支,这里是不是AP理论有异议】,进入保护模式后Eureka Server会尝试保护服务注册表中的信息,不再删除服务注册表中的数据,即不会注销任何微服务;
Eureka自我保护是为了避免EurekaClient运行正常但是与Eureka Server网络不同情况下Eureka服务器立即将Eureka Client剔除
EurekaServer默认在90s内没有接收到微服务实例的心跳,就会注销该实例,但是如果网络分区发生故障【延迟、卡顿、拥挤】,但是此时微服务本身是健康的,此时不应该注销该微服务,
Eureka用自我保护模式来解决该问题,当Eureka短时间失去过多客户端时会认为可能发生了网络分区故障,相关节点会进入自我保护模式,涉及思想就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例,目的就是为了高可用,同时也是Eureka集群更加健壮、稳定
Eureka默认是开始自我保护的,可以设置禁止自我保护机制
即实现只要90s检测不到心跳包,就立刻注销对应微服务
第一步:在Eureka Server的配置文件中设置eureka.server.enable-self-preservation=false【输入属性名看提示能发现默认是开启的】
关了以后Eureka界面会提示安全模式已经被关闭
第二步:在Eureka Server的配置文件中设置eureka.server.eviction-interval-timer-in-ms=2000,默认是90s 【设置注销服务时间间隔设置成2s】
【Eureka服务端设置】
xxxxxxxxxxeurekaserver#关闭Eureka服务端自我保护机制enable-self-preservationfalse#Eureka服务端在收到最后一次心跳后的等待时间上限,单位为毫秒(默认是90s),超时将剔除服务eviction-interval-timer-in-ms2000第三步:
eureka.client.instance.lease-renewal-interval-in-seconds=1设置Eureka Client向服务端发送心跳包的时间间隔为1s,默认是30s【单位为秒】第四步:
eureka.client.instance.lease-expiration-duration-in-seconds=2设置Eureka客户端在收到最后一次心跳后等待时间上限,单位为秒【Eureka客户端即微服务中的设置】
讲的不清楚啊,就讲了要这么配,但是配来干什么就得猜,尚硅谷的课都是这个毛病
xxxxxxxxxx#eureka配置信息eurekainstance#Eureka客户端向服务端发送心跳的时间间隔lease-renewal-interval-in-seconds1#Eureka服务端在收到最后一次心跳后的等待时间上限,单位为秒(默认是90s),超时将剔除服务lease-expiration-duration-in-seconds2
测试:配置了以上心跳时间、最后一次心跳等待上限和关闭保护模式后的测试效果
客户端心跳包时间间隔1s,等待上限2s,开启两个服务,服务列表正常显示
关闭客户端服务,Eureka服务端的服务列表立刻删除了对应客户端
将客户端发送心跳的时间设置成3s,Eureka等待时间上限设置成2s,测试一下
经过测试,心跳包发送间隔略大于等待上限时间,服务仍然能够正常显示,且第三方服务能通过Eureka对该服务进行调用
Zookeeper替换Eureka
创建模块07
Eureka停更说明
Eureka2.0以后停止了更新,使用Eureka2.x导致的风险自己负责,Eureka1.0作为网飞服务发现系统仍然是一个活跃的工程
部分企业老项目是Zookeeper+Dubbo,想要最小代价切换Dubbo到SpringCloud,就需要使用到SpringCloud整合Zookeeper替代Eureka,可以实现最小代价更换项目架构
SpringCloud整合Zookeeper替代Eureka
Zookeeper是一个分布式协调工具,可以实现注册中心的功能,原本是Dubbo的注册中心
本次Zookeeper3.4.9,装载Linux系统上,记得开放防火墙远程通讯端口【学Zookeeper时留意一下linux系统ping通windows系统时的windows系统的ip如何获取】
这里暂时只开放了2181端口
使用
ipconfig命令查出windows系统的ip地址
使用
ifconfig命令查看linux系统的ip地址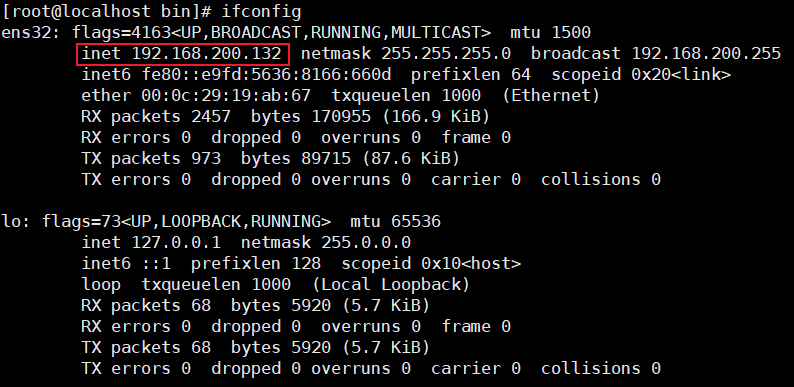
使用ping命令测试windows和linux是否能够ping通
在目标微服务的pom文件中添加spring-cloud-starter-zookeeper-discovery依赖
引入了Zookeeper,Eureka的依赖必须注释或者排除掉,否则项目无法启动
Zookeeper依赖的版本必须和Zookeeper集群中的版本对应
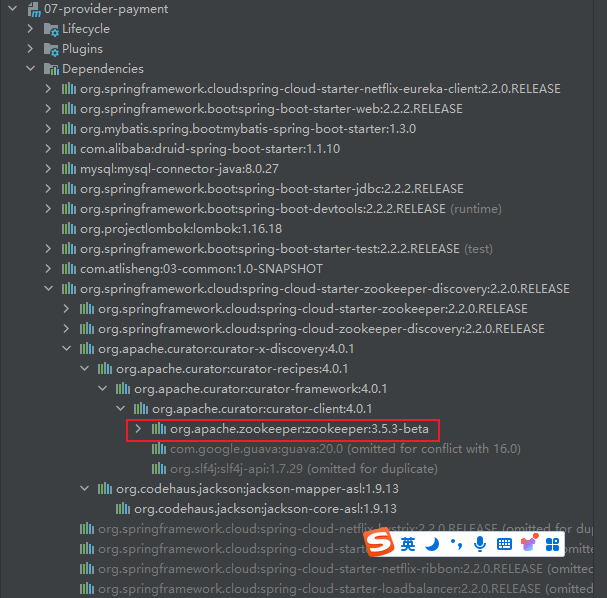
xxxxxxxxxx<dependencies><!--eureka-client--><!--使用ZookeeperEureka需要排除掉,因为没有配置--><!--<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>--><!--spring-boot--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><!--mysql-connector-java--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--jdbc--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>${project.version}</version></dependency><!--springBoot整合Zookeeper客户端--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zookeeper-discovery</artifactId><!--排除掉上述jar包中的Zookeeper3.5.3--><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency><!--引入本机安装的Zookeeper3.5.7版本--><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency></dependencies>启动类
zookeeper服务端和客户端均运行在linux系统中,使用consul或者Zookeeper作为注册中心时微服务向注册中心进行注册启动类上均使用@EnableDiscoveryClient注解
而Eureka的服务器启动类上标注@EnableEurekaServer,客户端微服务启动类上标注@EnableEurekaClient
xxxxxxxxxx//该注解用于向使用consul或者Zookeeper作为注册中心时微服务向注册中心进行注册public class PaymentApplication {public static void main(String[] args){SpringApplication.run(PaymentApplication.class,args);}}配置文件application.yml
xxxxxxxxxx#注册到Zookeeper服务器中的支付服务的服务器端口号serverport8004#数据元springdatasourcetypecom.alibaba.druid.pool.DruidDataSourcedriver-class-namecom.mysql.cj.jdbc.Driverurljdbcmysql//localhost3306/cloud_h_demo?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=truepasswordHaworthia0715usernameroot#服务别名--注册Zookeeper服务注册中心列表的名称applicationnamecloud-provider-paymentcloudzookeeper#一个Zookeeper的ip+端口号connect-string192.168.200.1322181controller
就整合Zookeeper来说,这个没啥意义,只是证明能够正常访问
xxxxxxxxxxpublic class PaymentController {("${server.port}")private String serverPort;("/payment/zk")public String paymentRegistryByZk(){log.info("slf4j是否正常");return "Registry with zookeeper:"+serverPort+"\t"+ UUID.randomUUID().toString();}}Zookeeper的服务器注册信息
xxxxxxxxxx#服务启动前,只有一个Zookeeper节点[zk: localhost:2181(CONNECTED) 1] ls /[zookeeper]#显示Zookeeper节点下的信息[zk: localhost:2181(CONNECTED) 3] ls /zookeeper[config, quota]#服务启动后在Zookeeper中出现服务列表[zk: localhost:2181(CONNECTED) 9] ls /[services, zookeeper]#列表下展示的是在注册中心注册的服务名[zk: localhost:2181(CONNECTED) 10] ls /services[cloud-provider-payment]#585ddd0b-7d30-4225-afda-758f05b75c8f是Zookeeper自己生成的uuid[zk: localhost:2181(CONNECTED) 11] ls /services/cloud-provider-payment[585ddd0b-7d30-4225-afda-758f05b75c8f][zk: localhost:2181(CONNECTED) 12] ls /services/cloud-provider-payment/585ddd0b-7d30-4225-afda-758f05b75c8f[]#获取Zookeeper中被注册服务的注册信息[zk: localhost:2181(CONNECTED) 13] get /services/cloud-provider-payment/585ddd0b-7d30-4225-afda-758f05b75c8f{"name":"cloud-provider-payment","id":"585ddd0b-7d30-4225-afda-758f05b75c8f","address":"192.168.0.106","port":8004,"sslPort":null,"payload":{"@class":"org.springframework.cloud.zookeeper.discovery.ZookeeperInstance","id":"application-1","name":"cloud-provider-payment","metadata":{}},"registrationTimeUTC":1698197224917,"serviceType":"DYNAMIC","uriSpec":{"parts":[{"value":"scheme","variable":true},{"value":"://","variable":false},{"value":"address","variable":true},{"value":":","variable":false},{"value":"port","variable":true}]}}服务注册信息【json字符串】
使用网站https://tool.lu/json可以转换json字符串为json工具
xxxxxxxxxx{"name": "cloud-provider-payment","id": "585ddd0b-7d30-4225-afda-758f05b75c8f","address": "192.168.0.106","port": 8004,"sslPort": null,"payload": {"@class": "org.springframework.cloud.zookeeper.discovery.ZookeeperInstance","id": "application-1","name": "cloud-provider-payment","metadata": {}},"registrationTimeUTC": 1698197224917,"serviceType": "DYNAMIC","uriSpec": {"parts": [{"value": "scheme","variable": true},{"value": "://","variable": false},{"value": "address","variable": true},{"value": ":","variable": false},{"value": "port","variable": true}]}}
zookeeper的节点
Zookeeper的节点分为临时节点、带序号的临时节点、持久节点、带序号的持久节点
服务器注册在Zookeeper上的节点是临时节点,只要服务器挂了,Zookeeper接收不到来自服务器的心跳,出了默认时间就直接删除服务器的注册信息,不像Eureka一样默认有自我保护机制;重新启动服务器以后向Zookeeper注册,此时Zookeeper中的对应uuid和之前的已经不一样了
消费者服务注册到Zookeeper并通过Zookeeper调用支付模块
Zookeeper区分服务名大小写,这里的演示代码中用的集群服务名的方式设置支付模块的url,如果是Zookeeper集群只需要在配置文件中将Zookeeper的地址写成集群方式,和Eureka集群一样用逗号进行分隔
创建模块08作为注册Zookeeper的消费者模块
pom.xml
zookeeper的依赖版本要和linux上的Zookeeper版本严格对应
xxxxxxxxxx<dependencies><!--spring-boot--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--数据库相关配置--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><!--mysql-connector-java--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!--jdbc--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!--开发工具热部署--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><!--日志,getter和setter--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>${project.version}</version></dependency><!--springBoot整合Zookeeper客户端--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zookeeper-discovery</artifactId><!--排除掉上述jar包中的Zookeeper3.5.3--><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency><!--引入本机安装的Zookeeper3.5.7版本--><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency></dependencies>application.yml
xxxxxxxxxx#注册到Zookeeper服务器中的支付服务的服务器端口号serverport80#数据元springdatasourcetypecom.alibaba.druid.pool.DruidDataSourcedriver-class-namecom.mysql.cj.jdbc.Driverurljdbcmysql//localhost3306/cloud_h_demo?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=truepasswordHaworthia0715usernameroot#服务别名--注册Zookeeper服务注册中心列表的名称applicationnamecloud-consumer-ordercloudzookeeper#一个Zookeeper的ip+端口号connect-string192.168.200.1322181启动类
xxxxxxxxxxpublic class OrderApplication {public static void main(String[] args){SpringApplication.run(OrderApplication.class,args);}}配置类
没学Ribbon以前还是使用RestTemplate进行服务调用【封装了HttpClient】
xxxxxxxxxxpublic class ApplicationContextConfig {/*** @return {@link RestTemplate }* @描述 注入RestTemplate对象* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public RestTemplate getRestTemplate(){return new RestTemplate();}}controller
xxxxxxxxxxpublic class OrderController {//Zookeeper的服务名严格区分大小写,Eureka不区分public static final String PAYMENT_URL="http://cloud-provider-payment";private RestTemplate restTemplate;/*** @return {@link String }* @描述 consumer注册到Zookeeper中,通过Zookeeper调用payment服务返回结果* @author Earl* @version 1.0.0* @创建日期 2023/10/25* @since 1.0.0*/("/consumer/payment/zk")public String paymentInvokeByZk(){String result=restTemplate.getForObject(PAYMENT_URL+"/payment/zk",String.class);return result;}}测试效果

Consul
Consul官网:https://www.consul.io/intro/index.html,页面写的不错,可以参考
Consul是一套开源分布式服务发现和配置管理系统,由HashiCorp公司用Go语言开发,提供微服务系统中的服务治理、配置中心、控制总线等功能,这些功能可以单独使用,也可以组合使用,是一种完整的服务网格解决方案【没有Nacos,基本上就是Eureka的接班人,Zookeeper可以用,但是用的少】
优点:基于raft协议,简洁,支持健康检查、支持HTTP和DNS协议、支持跨数据中心的WAN集群,提供图形界面,支持跨平台【linux、windows、Mac】
Consul特性
服务注册与发现【主要功能】
提供HTTP和DNS两种发现方式
健康检查
支持多方式HTTP、TCP、Docker、Shell脚本定制化
K-V键值对存储
key-value键值对数据存储方式
安全服务交互
多数据中心
可视化的Web界面
Consul安装
下载地址:https://www.consul.io/downloads.html,下载完解压只有一个consul.exe文件,当前目录下双击运行,也可以在cmd窗口下使用命令
consul agent -dev使用开发者模式启动官网安装说明:https://learn.hashicorp.com/consul/getting-started/install.html
consul --version能查看版本,课程用的1.6.1
可以通过http://localhost:8500访问consul的首页
https://www.consul.io/downloads.html
i386:Intel80386,通常作为32位微dao处理器的统称,认为是32位的就完事了
AMD64:又称x86-64,一种64位元电脑处理器架构,认为是64位的就完事了
访问下载界面,选择对应版本,下载解压,cmd窗口使用开发者模式启动
浏览器输入网址访问
效果
Consul单击构建
创建09模块
pom.xml
xxxxxxxxxx<dependencies><!--SpringCloud consul server--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId></dependency><!--springboot的Web场景启动器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--Actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--通常使用的jar包--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8005Springapplicationnameconsul-provider-payment#consul的注冊中心地址cloudconsul#主机iphostlocalhost#consul端口port8500discovery#服务列表的名字需要自己设置,不会自动取应用名称service-name$spring.application.name启动类
xxxxxxxxxxpublic class PaymentApplication {public static void main(String[] args){SpringApplication.run(PaymentApplication.class,args);}}控制器方法
xxxxxxxxxxpublic class PaymentController {("${server.port}")private String serverPort;("/payment/zk")public String paymentRegistryByZk(){return "Registry with zookeeper:"+serverPort+"\t"+ UUID.randomUUID().toString();}}测试效果
按相同的流程搭建消费者
通过consul进行服务调用
三种注册中心异同
| 组件名 | 语言 | CAP | 服务健康检查 | 对外暴露接口 | SpringCloud集成 |
|---|---|---|---|---|---|
| Eureka | Java | AP | 支持 | HTTP | 已集成 |
| Zookeeper | Java | CP | 支持 | 客户端 | 已集成 |
| Consul | Go | CP | 支持 | HTTP/DNS | 已集成 |
Zookeeper没有用户界面,只有一个Linux客户端,Zookeeper出来的时间比较早,在springcloud之前,对于新技术的支持不是很好
CAP理论
C代表Consistency【数据的强一致性】、A代表Availability【可用性】、P代表Partition tolerance【分区容错性】,CAP理论关注粒度是数据,而不是整体系统设计的策略
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,根据CAP理论将NoSQL数据库分成满足CA原则、满足CP原则和满足AP原则的三大类
CA-单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大
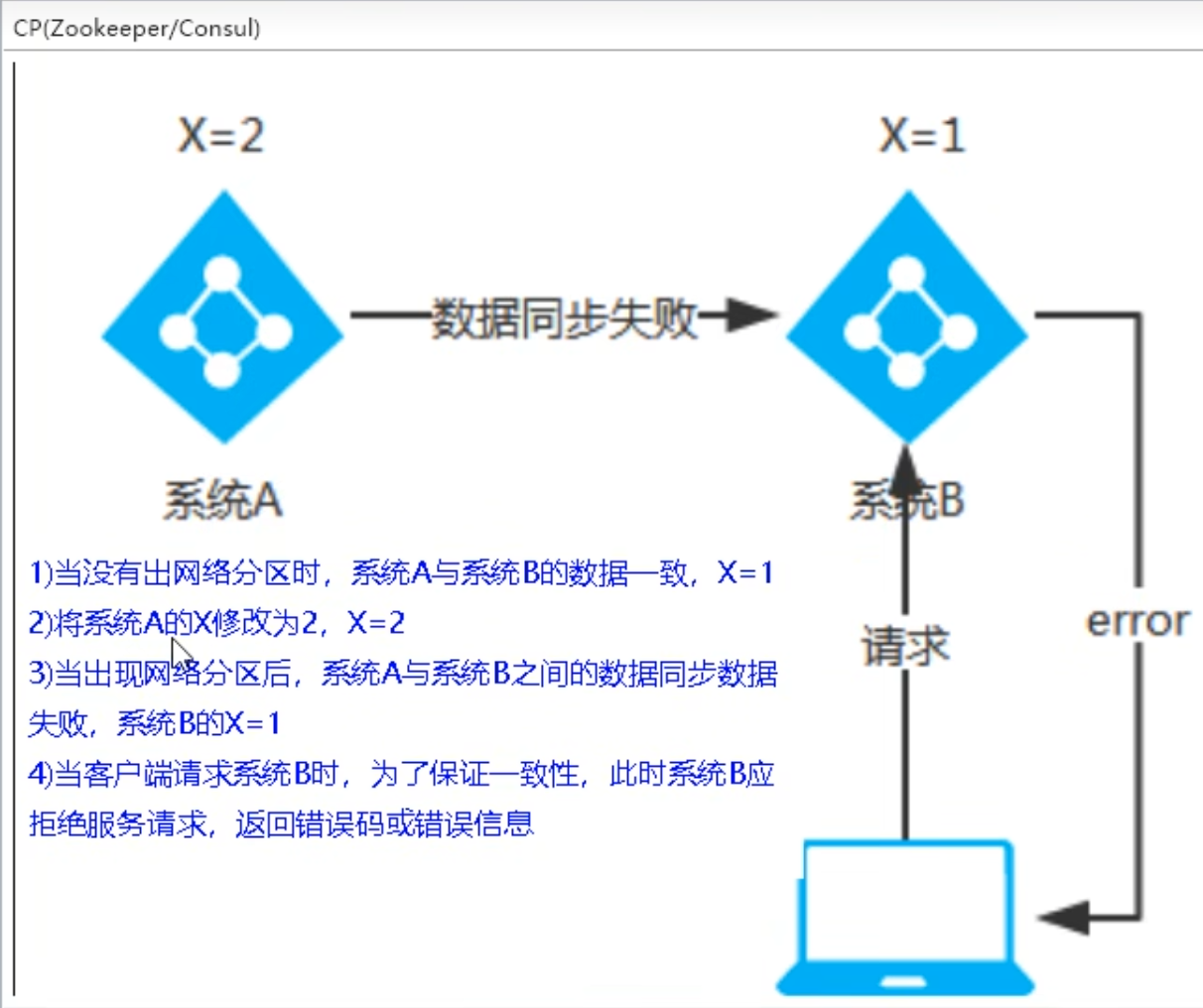
CP-满足一致性,分区容忍性的系统,通常性能不是特别高,当网络分区出现后,为了保证一致性,必须拒接请求,否则无法保证一致性【就是数据还是旧的,这个数据可能拿来产生新的数据,一错到底,此时就要牺牲系统可用性,优先保证数据的一致性】
AP-满足可用性,分区容错性的系统,通常对一致性的要求低一些,当网络分区出现后,为了保证可用性,数据同步失败的系统可以返回旧的值,违背一致性C的要求,保证系统的可用性和分区容错性
【经典CAP图】
找个博客看一下,这里讲的很模糊,尚硅谷就是这样,点到为止
不同的应用场景对系统的要求不同,但是P分区容错性是必须的,比如双十一京东、淘宝要求的是高可用性,对部分不相关的数据的一致性允许出错【评论数、点赞数】,比如发现数据不一致不能直接挂服务器,必须维持系统的高可用,不能因为部分数据不一致就导致系统不能使用【后续再根据base理论,柔性事务补充来进行数据的恢复】
【满足AP要求的系统结构】
Eureka的自我保护机制,更强调AP,保证系统的高可用,偶尔宕机找不到了,不会立刻删除【但是为啥不能网络断了立刻删除,网络好了再重新注册呢,这不是也不影响使用吗?难道影响别的系统运行?反正讲的不清不楚,感觉从结构图上分析,是多个服务对同一个数据进行更改,由于网络问题,某个服务状态是正常的,可以进行数据增删改查,但是数据没有同步,如数据修改过程中其他服务器不知道,数据库数据还没更改其他服务器就拿出来操作了,这种情况下网络通畅的服务器使用错误的数据进行进一步计算,得到错误的运算结果,累计下去可能数据无法恢复】
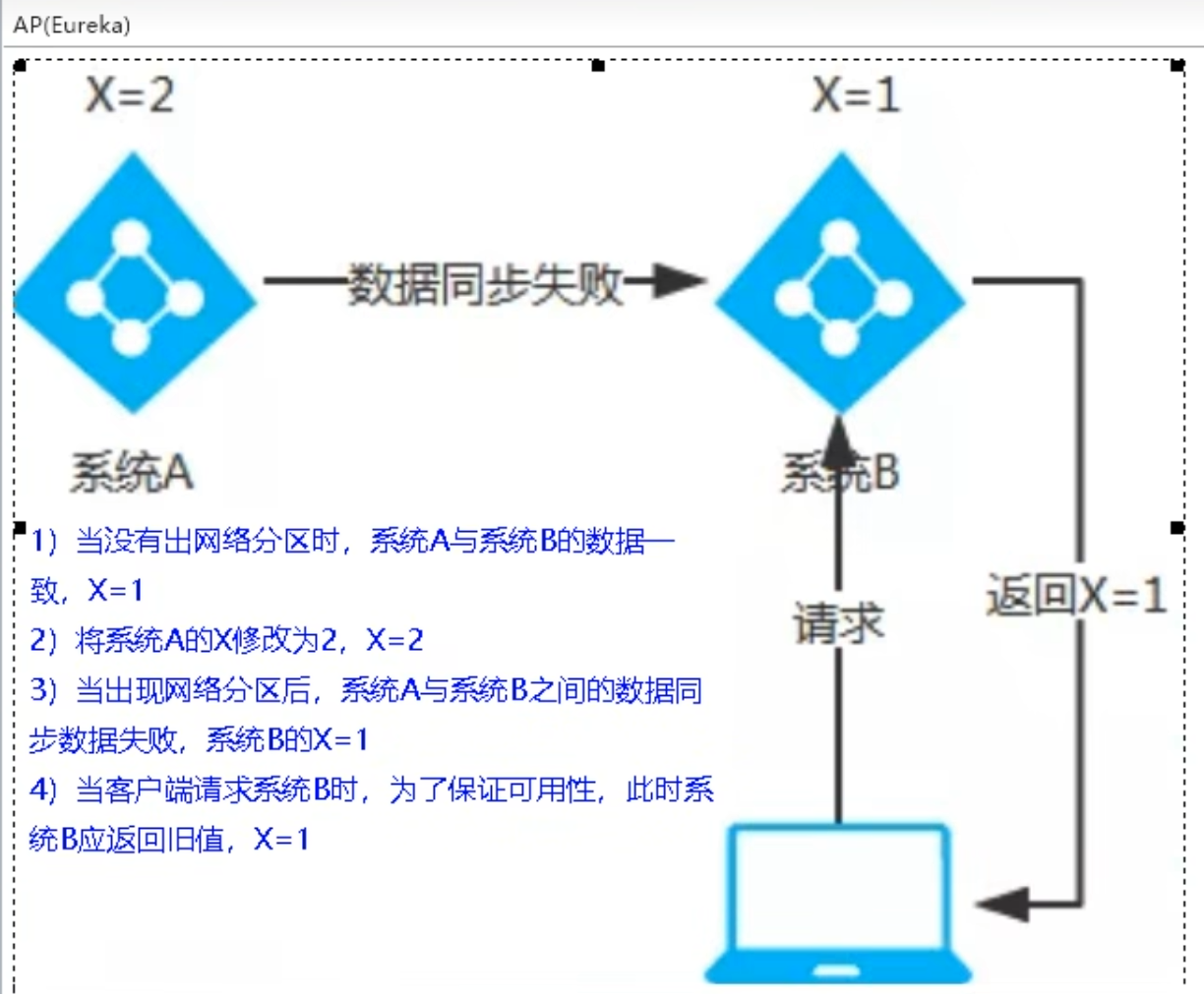
【CP架构结构图】
Consul和Zookeeper都是服务心跳默认时间内接收不到,直接注销服务,这种特性使得服务器之间通信必须正常,单个服务不能用没更新的旧数据进行操作
负载均衡
Ribbon
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡工具,是安装在微服务应用端的工具,Ribbon是NetFlix的开源项目,功能是提供客户端的软件负载均衡算法和服务调用,Ribbon客户端提供一系列完善的配置项如连接超时、重试等,在配置文件找那个罗列出所有参与负载均衡Load Balancer的所有机器,Ribbon会自动帮助基于某种规则【简单轮询、随机连接等】去连接这些机器,用户可以很方便的使用Ribbon实现自定义的负载均衡算法
Ribbon中的ribbon-core、eureka、HttpClient目前还在大规模使用,SpringCloud一直想用LoadBalancer替换掉ribbon,但是目前还做不到,趋势是LoadBalancer
Ribbon官网资料:https://github.com/Netflix/ribbon/wiki/Getting-Started
LB负载均衡
将用户请求平摊到多个服务器上,达到系统的高可用HA【high avaliable高可用】
常见的负载均衡软件有Nginx、LVS、硬件有F5
Nginx和Ribbon做负载均衡的区别
Nginx是服务器的负载均衡,客户端的所有请求都会交给nginx,由nginx实现转发请求,负载均衡是由Nginx服务端实现的【就是把Nginx当成大门,所有的请求都在nginx完成负载均衡,医院大门就把大夫决定好了】,集中式负载均衡
Ribbon是本地负载均衡,在调用微服务接口的时候,在注册中心上获取注册信息服务列表后缓存到JVM本地,实际在本地实现RPC远程服务调用技术【就是请求先去服务集群,在集群中实现负载均衡,去到对应的科室才决定好治病的大夫】,
集中式负载均衡:在服务的消费方和提供方之间使用独立的负载均衡设施【可以是硬件F5,也可以是软件如nginx】,由该设施通过某种策略把请求转发给具体的服务提供方,nginx就是
进程内负载均衡:将逻辑集成到消费方,消费方从服务注册中心获知哪些地址可用,自己通过负载均衡逻辑选择合适的服务器,Ribbon就属于进程内负载均衡,只是一个类库,继承于消费方进程,消费方通过Ribbon来获取服务提供方的地址
Ribbon就是负载均衡+RestTemplate服务调用
spring-cloud-starter-netflix-eureka-client已经整合了Ribbon
因为client中整合了ribbon,所以可以实现负载均衡,默认是轮询查询
eureka-client整合ribbon的证明
单独引入ribbon也是引入spring-cloud-starter-netflix-ribbon
RestTemplate
相关方法:
getForObject方法
返回对象为响应体中数据转换成的对象,基本可以理解为json
联想springmvc里的返回值处理中@Responsebody和ResponseEntity,一个是直接把数据返回响应体中,一个是完整的响应报文(包含响应体和响应头)
getForEntity方法
返回对象为ResponseEntity对象,包含响应中的一些重要信息,如响应头、响应状态码、响应体等
postForObject方法
和get方法的区别是get方法一般用于获取数据,post方法一般用于添加修改数据
postForEntity方法
区别同上一个
方法代码
【getForObject】
xxxxxxxxxxpublic static final String PAYMENT_URL="http://service-payment";private RestTemplate restTemplate;/*** @param payment* @return {@link CommonResp }<{@link Payment }>* @描述 RestTemplate发送post请求对其他服务进行调用,参数以对象的形式传入* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/create")public CommonResp<Payment> create(Payment payment){return restTemplate.postForObject(PAYMENT_URL+"/payment/create",payment, CommonResp.class);}/*** @param id* @return {@link CommonResp }<{@link Payment }>* @描述 RestTemplate发送Get请求对其他服务进行调用,参数直接拼接在url尾部* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/("/consumer/payment/get/{id}")public CommonResp<Payment> getPayment( Long id){return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id, CommonResp.class);}【getForEntity】
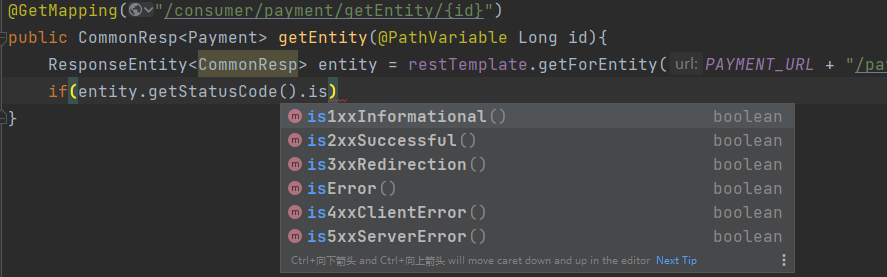
xxxxxxxxxx/*** @param id* @return {@link CommonResp }<{@link Payment }>* @描述 只需要json串用Object,需要更详细的信息就需要Entity,现在json串使用量比较大* @author Earl* @version 1.0.0* @创建日期 2023/10/26* @since 1.0.0*/("/consumer/payment/getEntity/{id}")public CommonResp<Payment> getEntity( Long id){ResponseEntity<CommonResp> entity = restTemplate.getForEntity(PAYMENT_URL + "/payment/get/" + id, CommonResp.class);if(entity.getStatusCode().is2xxSuccessful()){log.info(entity.toString());return entity.getBody();}else{return new CommonResp<>(444,"服务调用异常");}}【响应的状态判断】
Ribbon负载均衡策略
负载均衡策略所在的包
ribbon-loadbalancer模块下的IRule接口对负载均衡策略进行了定义
出厂默认的轮询规则有七种,默认的就是轮询
负载均衡面试点:
有没有替换过负载均衡方式
假设不够用了有没有自己手写一个负载均衡策略
【对应的实现类】
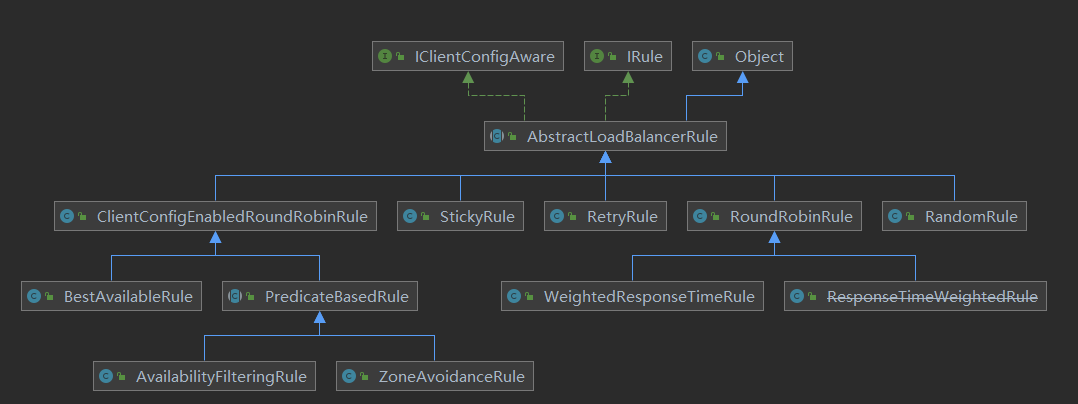
RoundRobinRule就是轮询策略
RadomRule是随机策略
RetryRule是重试策略
先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内进行重试,获取可用的服务
WeightedResponseTimeRule
对RoundRobinRule的扩展,响应速度越快的实例选择权重越多大,越容易被选择
BestAvailableRule
会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
AvailabilityFilteringRule
先过滤掉故障实例,再选择并发较小的实例
ZoneAvoidanceRule
默认规则,复合判断server所在区域的性能和server的可用性选择服务器
Ribbon负载均衡规则替换
在消费者中配置自定义负载均衡配置类,官方文档给出明确警告,该自定义配置类不能放在@ComponentScan所扫描的当前包以及子包下,否则自定义的配置类会被其他所有的Ribbon客户端所共享,达不到特殊化定制的目的【SpringBoot应用默认是启动类所在的包】
在02项目项目下创建与启动类不同的包lbrule,在该包下创建配置类并使用@Bean注解注入IRule组件,返回该接口的子对象
xxxxxxxxxxpackage com.atlisheng.lbrule;//不在包扫描范围内,在包扫描范围内,所有的ribbon都会使用自定义的负载均衡规则import com.netflix.loadbalancer.IRule;import com.netflix.loadbalancer.RandomRule;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;/*** @author Earl* @version 1.0.0* @描述 自定义规则* @创建日期 2023/10/26* @since 1.0.0*/public class CustomizationRule {/*** @return {@link IRule }* @描述 将负载均衡配置为轮询* @author Earl* @version 1.0.0* @创建日期 2023/10/26* @since 1.0.0*/public IRule loadBalanceRule(){return new RandomRule();}}启动类
在启动类上配置自定义负载均衡调用的服务集群并指定自定义负载均衡规则类型,把@RibbonClient注解注释掉,就算把自定义负载均衡配置类注入到IoC容器中也不会起作用,注释了就是默认的轮询
并且注意此时RestTemplate是加了@LoadBalanced注解开启负载均衡的
xxxxxxxxxx//在服务调用客户端通过调用服务和指定配置类配置ribbon负载均衡规则(name="service-payment",configuration = CustomizationRule.class)public class OrderApplication {public static void main(String[] args){SpringApplication.run(OrderApplication.class,args);}}
Ribbon负载均衡轮询算法
轮询
rest接口第几次请求数%服务器集群总数量=实际调用服务器位置下标,每次服务重启后【重启其中任意一台】rest接口从1计数开始
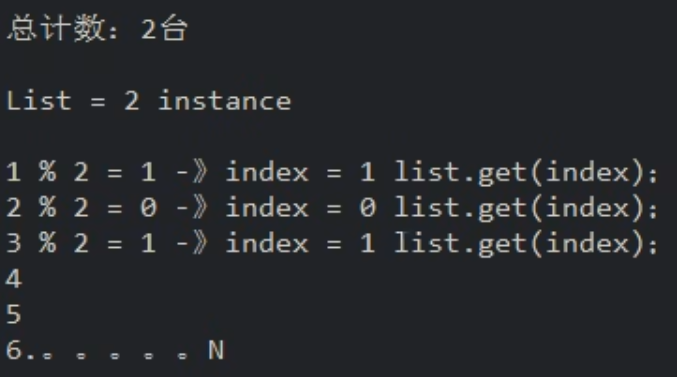
服务调用方通过discoveryClient.getInstances("服务集群名")获取服务器集群数量,再按照轮询算法计算出index取出对应服务器的ip和端口号进行访问
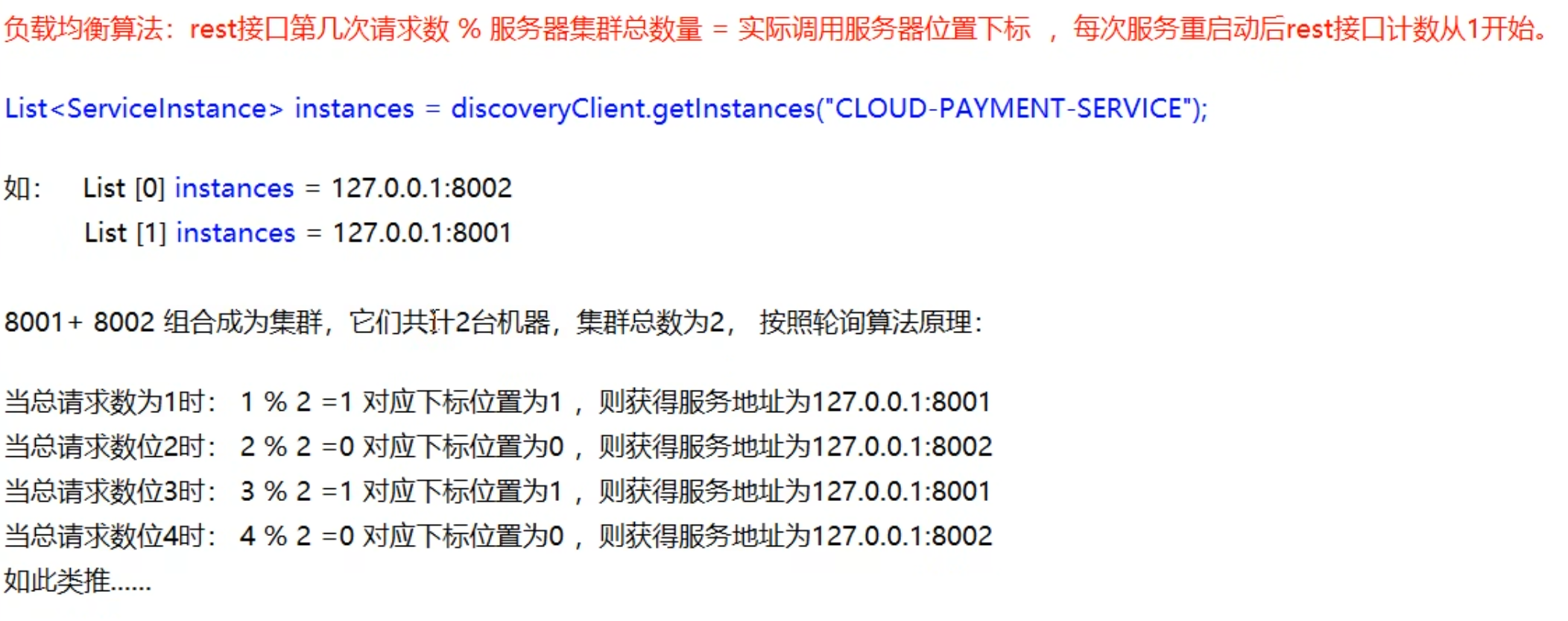
轮询算法源码
源码
xxxxxxxxxx/*** Copyright 2013 Netflix, Inc.** Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file except in compliance with the License.* You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.**/package com.netflix.loadbalancer;import com.netflix.client.config.IClientConfig;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.List;import java.util.concurrent.atomic.AtomicInteger;/*** The most well known and basic load balancing strategy, i.e. Round Robin Rule.** @author stonse* @author Nikos Michalakis <nikos@netflix.com>**/public class RoundRobinRule extends AbstractLoadBalancerRule {private AtomicInteger nextServerCyclicCounter;//原子整形类【?AQS】private static final boolean AVAILABLE_ONLY_SERVERS = true;private static final boolean ALL_SERVERS = false;private static Logger log = LoggerFactory.getLogger(RoundRobinRule.class);public RoundRobinRule() {nextServerCyclicCounter = new AtomicInteger(0);}public RoundRobinRule(ILoadBalancer lb) {this();setLoadBalancer(lb);}public Server choose(ILoadBalancer lb, Object key) {if (lb == null) {log.warn("no load balancer");return null;}Server server = null;//准备server接收选出来的服务器实例int count = 0;while (server == null && count++ < 10) {//这一段看完JUC再说List<Server> reachableServers = lb.getReachableServers();//获取在线的服务器列表,这个和下面有什么区别,所有在线服务吗?List<Server> allServers = lb.getAllServers();//获取集群中所有的服务器列表int upCount = reachableServers.size();int serverCount = allServers.size();if ((upCount == 0) || (serverCount == 0)) {log.warn("No up servers available from load balancer: " + lb);return null;}int nextServerIndex = incrementAndGetModulo(serverCount);//获取轮询的下一台服务器的索引,传参是集群中所有服务器的数量server = allServers.get(nextServerIndex);if (server == null) {/* Transient. */Thread.yield();continue;}if (server.isAlive() && (server.isReadyToServe())) {return (server);}// Next.server = null;}if (count >= 10) {log.warn("No available alive servers after 10 tries from load balancer: "+ lb);}return server;}/*** Inspired by the implementation of {@link AtomicInteger#incrementAndGet()}.** @param modulo The modulo to bound the value of the counter.* @return The next value.*/private int incrementAndGetModulo(int modulo) {for (;;) {int current = nextServerCyclicCounter.get();//原子类初始值是0int next = (current + 1) % modulo;if (nextServerCyclicCounter.compareAndSet(current, next))//JUC中的CAS+自旋锁,cas是比较和交换return next;}}public Server choose(Object key) {return choose(getLoadBalancer(), key);}public void initWithNiwsConfig(IClientConfig clientConfig) {}}
手写轮询算法
【基于CAS+自旋锁】
//TODO
服务调用
OpenFeign
官网:https://cloud.spring.io/spring-cloud-static/Hoxton.SR1/reference/htmlsingle/#spring-cloud-openfeign
Feign是一个声明式WebService客户端,使用方法是定义一个服务接口然后在上面添加注解,实际是通过接口以动态代理的方式实现的,Feign支持可拔插式的编码器和解码器,SpringCloud对Feign进行了风状态,使其支持SpringMVC标准注解和HttpMessageConverters,Feign可以和Eureka以及Ribbon组合使用以支持负载均衡
Feign主要作为服务调用组合在Eureka和Ribbon中共同组成服务注册、负载均衡与服务调用
OpenFeign的源码:https://github.com/spring-cloud/spring-cloud-openfeign
Feign的作用
Feign可以使编写Java Http客户端更简介,使用Ribbon+RestTemplate利用RestTemplate对http请求进行封装处理,会形成一套模板化的调用方法,但实际开发过程中,对服务的调用可能会在好几个客户端的多处地方使用,通常针对每个微服务自行封装一些客户端类来包装这些自定义服务调用,Feign进一步封装。用类似于Mapper接口上添加@Mapper注解的方式实现用户自定义对服务调用方法的定义并用注解的方式对进行配置,通过动态代理的方式实现服务调用者对服务方法调用的定制化开发,相比于原来的RestTemplate,一处服务调用的代码可以复用,且可以通过方法调用的方式实现服务调用【01:我的理解:对一个服务的调用可能存在于多个消费者的多处地方,如果用RestTemplate每次都要写一遍代码,很不方便;就在消费者单独封装出对服务调用的类出来,Feign更进一步,以接口定义的方式定义对生产者的方法调用做了定义,通过动态代理的方式实现在消费者中对生产者服务的定制化调用】
Feign集成了Ribbon,使用Feign可以自然实现负载均衡,重复的依赖会被省略,且负载均衡默认就是开启的

Feign和OpenFeign的区别
Feign就已经实现内置Ribbon,使用Feign的注解定义服务调用接口调用注册中心的服务,还自带了调用方的负载均衡【使用Feign引入的依赖是
spring-cloud-starter-feign】OpenFeign在SpringCloud支持Feign的基础上支持SpringMVC的注解,如@RequestMapping等,OpenFeign的@FeignClient可以解析SpringCloudMVC的@RequestMapping注解下的接口【?解析请求路径,找到对应的控制器方法吗?】,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务,微服务调用接口+注解【使用OpenFeign引入的依赖是
spring-cloud-starter-openfeign】微服务调用接口:提供方和调用方匹配的方法
注解:@FeignClient,用在消费侧
OpenFeign的使用流程
服务提供方心跳设置发送心跳间隔大于心跳等待上限,虽然eureka显示一切正常,但是该服务无法提供服务,展示的效果是服务列表有,但是无法负载均衡
eureka集群没有相互注册【即eureka服务器存在还是以单击版形式启动的服务器】,也无法实现负载均衡
创建模块11
pom.xml
xxxxxxxxxx<dependencies><!--openFeign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--eureka client--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--devtools--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--test--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport80eurekaclientservice-urldefaultZonehttp//eureka7001.com7001/eureka,http//eureka7002.com7002/eureka启动类
使用OpenFeign进行服务调用要在启动类上使用@EnableFeignClient注解激活
xxxxxxxxxx//激活Feign消费端对服务的调用,OpenFeign默认是开启负载均衡的,默认使用的是Ribbon的轮询负载均衡,如果没有配置负载均衡是不会生效的//1. 服务提供方心跳设置发送心跳间隔大于心跳等待上限,虽然eureka显示一切正常,但是该服务无法提供服务,展示的效果是服务列表有,但是无法负载均衡//2. eureka集群没有相互注册【即eureka服务器存在还是以单击版形式启动的服务器】,也无法实现负载均衡public class OrderApplication {public static void main(String[] args){SpringApplication.run(OrderApplication.class,args);}}服务调用接口
这里能调到和方法名无关,只和路径有关!!!
习惯放在client包下
服务调用方法必须用@PathVariable("id")指定参数名,否则项目无法启动
xxxxxxxxxx("service-payment")public interface PaymentServiceClient {/*** @param id* @return {@link CommonResp }* @描述 参数必须要用@PathVariable("id")指定参数名,否则项目无法启动* @author Earl* @version 1.0.0* @创建日期 2023/10/28* @since 1.0.0*/("/payment/get/{id}")public CommonResp getPaymentById(("id") Long id);}控制器
@Autowired和@Resource两个注解都可以用来注入服务调用接口
xxxxxxxxxxpublic class PaymentController {//两个注解都能使用//@ResourcePaymentServiceClient paymentServiceClient;("/consumer/payment/get/{id}")public CommonResp order( Long id){return paymentServiceClient.getPaymentById(id);}}
OpenFeign超时控制
服务提供者处理业务逻辑需要3秒,服务提供者认为这是正常健康的;但是消费者默认只愿意等2秒,此时就会产生超时调用报错,此时需要更改
演示服务调用响应超时的情况
故意在服务提供方01模块写暂停程序
tsleep可以快速弹出暂停线程的try...catch代码块xxxxxxxxxx/*** @return {@link String }* @描述 模拟服务响应时间大于Feign调用默认超时时长* @author Earl* @version 1.0.0* @创建日期 2023/10/28* @since 1.0.0*/("/payment/feign/timeout")public String paymentFeignTimeout(){try{TimeUnit.SECONDS.sleep(3);}catch (InterruptedException e){e.printStackTrace();}return serverPort;}
消费者调用服务代码
服务调用接口
xxxxxxxxxx/*** @return {@link String }* @描述 调用服务模拟服务端响应超时* @author Earl* @version 1.0.0* @创建日期 2023/10/28* @since 1.0.0*/("/payment/feign/timeout")public String paymentFeignTimeout();控制器方法
xxxxxxxxxx/*** @return {@link String }* @描述 openFeign-ribbon客户端一般默认等待时间为1s钟* @author Earl* @version 1.0.0* @创建日期 2023/10/28* @since 1.0.0*/("/consumer/payment/feign/timeout")public String paymentFeignTimeout(){return paymentServiceClient.paymentFeignTimeout();}
自测服务提供方响应正常
等待3s返回结果
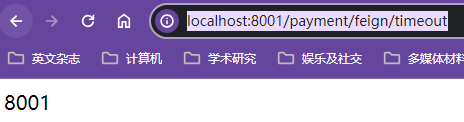
默认超时时长1s情况下的超时测试
等待差不多1s,报错read time out就是读取超时的意思,Feign默认超时时间就是1s,超时Feign客户端就会报错
为了避免这种情况,需要设置Feign客户端的超时时间,超时控制有ribbon在yml文件中的属性值进行控制,为什么使用ribbon的参数进行控制,在02模块中只是使用ribbon设置负载均衡策略,但是发送请求还是单独使用的RestTemplate

在消费者的yml配置文件中设置ribbon属性来设置超时时间
xxxxxxxxxx#设置feign客户端超时时间(OpenFeign默认支持ribbon,为什么使用ribbon的参数进行控制,在02模块中只是使用ribbon设置负载均衡策略,但是发送请求还是单独使用的RestTemplate)ribbon#建立连接所用时间,适用于网络状况正常的情况下,两端连接所用的时间ReadTimeout5000#指的是建立连接后从服务端读取到可用资源所用的时间ConnectTimeout5000设置feign客户端后的超时时间后的服务调用测试
转圈3s后展示返回结果
OpenFeign日志
可以通过配置OpenFeign的日志级别,了解Feign中Http请求的细节,就是对Feign接口的调用情况进行监控和输出
Feign的日志级别
NONE:默认的,不显示任何日志
BASIC:仅记录请求方法、URL、响应状态码以及执行时间
HEADERS:除了BASIC中定义的信息外,还有请求和响应的头信息
FULL:除了HEADERS中定义的信息外,还有请求和响应的正文以及元数据
配置步骤
添加配置类
xxxxxxxxxxpublic class FeignConfig {Logger.Level feignLoggerLevel(){//开启feign的详细日志,显示请求和响应的头信息,正文以及元数据return Logger.Level.FULL;}}在配置文件开启feign的日志功能
xxxxxxxxxxlogginglevel#feign日志以debug几倍监控服务调用接口PaymentServiceClient,这个是spring日志的debug级别监控PaymentServiceClient接口的full级别的信息com.atlisheng.cloud.client.PaymentServiceClientdebug测试结果
xxxxxxxxxx2023-10-29 02:52:58.840 DEBUG 20236 --- [p-nio-80-exec-4] c.a.cloud.client.PaymentServiceClient : [PaymentServiceClient#paymentFeignTimeout] #以下重复部分都省略---> GET http://service-payment/payment/feign/timeout HTTP/1.1---> END HTTP (0-byte body)<--- HTTP/1.1 200 (3015ms)connection: keep-alivecontent-length: 4content-type: text/plain;charset=UTF-8date: Sat, 28 Oct 2023 18:53:01 GMTkeep-alive: timeout=608001<--- END HTTP (4-byte body)
Hystrix服务降级
Hystrix熔断器,虽然停止更新进入维护,但是设计理念非常优秀【被动修复bugs,不接受合并请求,不再发布新版本】
服务降级、服务熔断、服务限流、服务隔离都是后面框架抄作业的蓝图;国外和官网都推荐resilience4j,但是国内都在用sentinel
分布式系统面临的问题
高内聚、低耦合
服务分开了,耦合度降低
但是服务之间的调用链路可能会变得很长,某个服务出问题,可能会导致相关的服务都出问题
一个服务可能需要调用数十个服务,某些服务在一些时候将不可避免的失败,比如网络卡顿超时、程序出错、机房断电
服务血崩
多个微服务间相互调用,服务A调用服务B和服务C,服务B和服务C又调用其他的微服务,这个过程叫做"扇出",假设服务A扇出的链路上某个微服务的调用响应his见过长或者不可用,对微服务A的调用就会占用越来越多的资源,进而引起系统崩溃,就是"雪崩效应",即一个模块下的某个实例失败后,这个模块还能接收流量,这个有问题的模块还能调用其他模块,就会发生级联故障【即血崩?这句话没懂】
对于高流量应用,单一的后端依赖可能会导致所有服务器上的资源几秒钟内饱和,这些应用程序还可能导致服务之间的延迟增加、备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障;
因此需要对故障和延迟进行隔离和管理,便于单个依赖关系的失败不能导致整个应用程序或者系统的崩溃
Hystrix
hystrix是用于处理分布式系统的延迟和容错的开源库,保证分布式系统中一个依赖因为超时、异常等原因出现问题的情况下,不会导致整体服务失败,避免级联故障,提升分布式系统的弹性
断路器是一种开关装置,当服务单元故障后,断路器的故障监控向调用方返回一个符合预期可处理的备选响应【fallback】,而不是长时间等待或者抛出调用方无法处理的异常以保证服务调用方的线程不会被长时间、不必要地占用【在Hystrix演示中详细体会】,从而避免故障在分布式系统中的蔓延乃至血崩
功能
服务降级
服务熔断
接近实时的监控
通过HystrixDashboard实现服务的监控
Hystrix概念
服务降级fallback
目标服务器不可用了,没有返回结果,需要给一个兜底解决办法,不要耗死在当前服务器,把服务器资源占满
向调用方返回一个符合预期、可处理的备选响应fallback,而非长时间等待或者抛出调用方无法处理的异常
比如不让客户端等待并向客户端返回一个友好的提示"服务器忙,请稍后尝试"
服务降级的情形
程序运行异常:数组下标越界、数学运算异常
超时
服务熔断触发
线程池/信号量打满
服务熔断break
达到最大服务访问后,直接拒绝访问,拉闸限电,熔断后调用服务降级的方法并返回友好提示,避免把服务器打死
这里貌似讲错了,似乎是通过服务降级实现服务熔断,再实现恢复服务调用链路
服务限流flowlimit
秒杀高并发等操作,所有请求排队,一秒处理N个,有序进行,严禁一窝蜂全部处理,避免服务器资源拉满
Hystrix案例
项目构建
创建12模块
pom.xml
xxxxxxxxxx<dependencies><!--hystrix--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency><!--eureka client--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--web--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--项目公共包,公共类和糊涂工具包--><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><!--devtools--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies>application.yml
xxxxxxxxxxserverport8006springapplicationnameservice-hystrix-payment#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-urldefaultZonehttp//eureka7001.com7001/eureka启动类
xxxxxxxxxxpublic class PaymentHystrixApplication {public static void main(String[] args){SpringApplication.run(PaymentHystrixApplication.class,args);}}service
xxxxxxxxxxpublic class PaymentServiceImpl implements PaymentService {/*** @param id* @return {@link String }* @描述 正常访问肯定ok的方法* @author Earl* @version 1.0.0* @创建日期 2023/10/29* @since 1.0.0*/public String paymentInfoOk(Integer id) {return "线程池:"+Thread.currentThread().getName()+"paymentInfoOk,id:"+id;}/*** @param id* @return {@link String }* @描述 访问一定会报错并导致服务降级的方法* @author Earl* @version 1.0.0* @创建日期 2023/10/29* @since 1.0.0*/public String paymentInfoTimeout(Integer id) {int sleepTime=3;try{TimeUnit.SECONDS.sleep(sleepTime);}catch (InterruptedException e){e.printStackTrace();}return "线程池:"+Thread.currentThread().getName()+",paymentInfoTimeout,id:"+id+",超时"+sleepTime+"秒钟";}}controller
xxxxxxxxxxpublic class PaymentController {private PaymentService paymentService;("${server.port}")private String serverPort;("/payment/hystrix/ok/{id}")public String paymentInfoOk(Integer id) {String result = paymentService.paymentInfoOk(id);log.info("*****result:"+result+serverPort);return result;}/*** @param id* @return {@link String }* @描述 独立访问payment,并没有通过feign调用,此时正常等待3秒,并不会出现超时的情况* @author Earl* @version 1.0.0* @创建日期 2023/10/29* @since 1.0.0*/("/payment/hystrix/timeout/{id}")public String paymentInfoTimeout(Integer id) {String result = paymentService.paymentInfoTimeout(id);log.info("*****result:"+result+serverPort);return result;}}
测试
启动eureka7001,启动012模块
分别访问成功的方法和超时的方法观察响应区别
独立访问12模块,不存在openfeign的服务调用,不存在响应超时的问题,等待持续时间后响应结果到浏览器;响应成功方法是瞬间响应
JMeter高并发压测
多线程访问
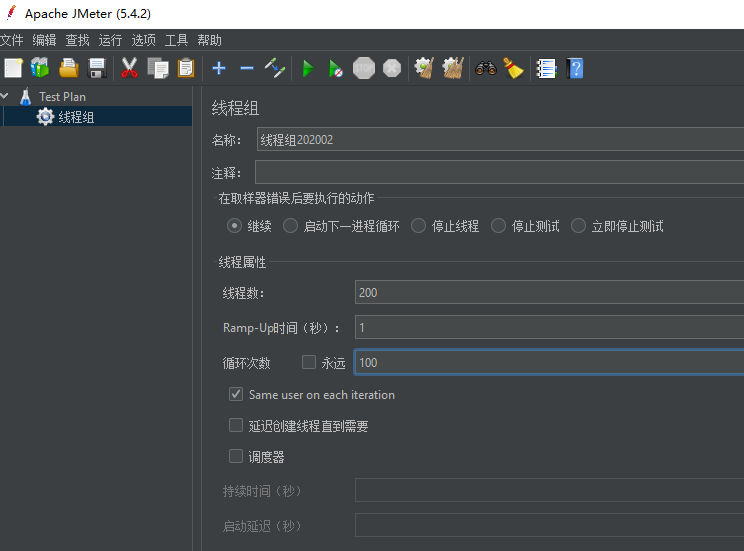
开启JMeter,20000个并发压死8006端口,20000个请求都去访问paymentInfoTimeout
jmeter并发测试设置
每秒并发200线程,循环100s,要保存线程组,并设置请求类型才能执行
【设置请求类型】
【请求参数设置】
测试结果
两万个并发打到微服务,同一个微服务下的方法都会陷入延迟,例如瞬时方法此时请求也开始转圈等待响应
我寻思着不就是默认线程数占满了,ok方法的请求在等待线程呗,如果存在线程不能释放或者超时的情况才会导致正常请求出问题吧
原因就是SpringBoot默认集成tomcat,使用tomcat容器的线程池,默认是10个线程,线程被高并发线程占满,导致其他能瞬时完成的请求会进行等待,服务调用超时,甚至整个被调用的服务直接被拖死【?把电脑硬件资源占满?】
增加消费者13模块对payment超时服务的高并发调用
hystrix消费侧服务侧都可以添加,一般放在消费端
pom.xml
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport80springapplicationnameservice-hystrix-order#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-urldefaultZonehttp//eureka7001.com7001/eureka服务调用接口
xxxxxxxxxx("service-hystrix-payment")public interface PaymentHystrixClient {("/payment/hystrix/ok/{id}")public String paymentInfoOk( ("id") Integer id);("/payment/hystrix/timeout/{id}")public String paymentInfoTimeout( ("id") Integer id);}控制器方法
xxxxxxxxxxpublic class OrderHystrixController {private PaymentHystrixClient paymentHystrixClient;("/consumer/payment/hystrix/ok/{id}")public String paymentInfoOk( ("id") Integer id){return paymentHystrixClient.paymentInfoOk(id);}("/consumer/payment/hystrix/timeout/{id}")public String paymentInfoTimeout( ("id") Integer id){return paymentHystrixClient.paymentInfoTimeout(id);}}测试效果
实际这里想实现的效果是在8006高并发20000并发量持续占用线程池的情况下,实现OpenFeign调用瞬时任务超过OpenFeign调用默认超时1s报错,但是由于复杂任务时间只有3s,很难出现等待空闲线程超过1s的情况,不容易产生报错,实际效果和正常直接调用8006的瞬时方法效果一样
注意这里设置了默认超时时长为5s
把参数设置成每秒钟400并发量,一共40000的并发量,每个请求处理4s,并发是直接访问8006端口,不是80端口调用的【总处理时长为40000*4/10=16000s】
但是实际上20min就跑完了,而且总的请求数量累加【成员变量】小于40000,因为没有加锁,所以存在同时对成员变量操作的情况,Ques:所有的请求是否都处理了,是否存在丢请求的情况
效果:瞬时方法被卡的好几秒钟才能响应,经常会出现响应超时报错,偶尔出现能响应成功的情况,即大部分响应时间超过5s,偶尔响应时间在5s内
【响应失败的情况】
【响应成功的情况】
模拟现实的情况就是
一个服务被瞬时的高并发量冲爆,本身的服务访问就会等待很长时间,此时其他服务对其扇出,原服务器冲击够大【瞬时并发量足够高、平均处理时间够长】的情况下必然会发生请求等待时间长的问题,要么响应时间慢,要么直接响应超时报错,本质上还是线程池保护了计算机资源不会被耗尽死机,并发请求抢占线程池中的线程,导致请求的等待时间长,对服务器中的所有方法请求处理时间都会变长
Idea:针对处理时长不同的方法设置不同组的线程是否可行?
Hystrix方案
着眼解决的问题:
被调用的服务器自己因为各种原因执行超时,调用者不能一直卡死等待
服务器出错宕机或者程序运行出错【服务器挂了访问出错要走备用处理方案】
【调用的服务超时或者机器挂了,调用方不能一直卡死等待,不是有响应超时报错吗,必须有服务降级】
服务器因为线程数紧张导致的超时问题,服务端运行正常,但是响应慢,调用方等不到而自己超时自己处理降级【不能直接给用户展示白页,让用户超时不要等待并用友好界面提示,客户也知道此时访问没用不会继续再点击】
服务降级
个人理解,当一个服务超时或者异常的情况下执行备选操作
服务自身进行服务降级:设置服务自身调用超时时间的峰值,峰值内服务正常运行,超过了该时间执行兜底方法作为服务降级fallback进行处理
服务降级的场景
程序运行异常
超时
服务熔断触发服务降级
线程池/信号两打满导致服务降级
服务提供方的超时兜底方法
这个意义上的服务降级既可以在服务调用端,也可以在服务提供端
@HystrixCommand注解【官网演示使用的是继承HystrixCommand这个类实现的,我们在对应需要兜底的方法上使用@HystrixCommand注解实现】,并在fallbackMethod属性指明对当前方法兜底的方法名
一旦调用服务方法失败并抛出错误信息后,会自动调用@HystrixCommand注解中标注好的fallbackMethod方法
在commandProperties属性中用@HystrixProperty注解的name属性和value属性指定兜底方法的调用条件
设置方法自身调用的超时时间峰值:
execution.isolation.thread.timeoutInMilliseconds单位:毫秒,其他降级的情况暂时没讲
xxxxxxxxxx/*** @param id* @return {@link String }* @描述 访问一定会报错并导致服务降级的方法* @author Earl* @version 1.0.0* @创建日期 2023/10/29* @since 1.0.0*/(fallbackMethod="paymentInfoTimeoutHandler",commandProperties = {//execution.isolation.thread.timeoutInMilliseconds是设置目标方法的调用超时时间,单位是毫秒(name="execution.isolation.thread.timeoutInMilliseconds",value = "3000")})public String paymentInfoTimeout(Integer id) {int sleepTime=4;try{TimeUnit.SECONDS.sleep(sleepTime);}catch (InterruptedException e){e.printStackTrace();}return "线程池:"+Thread.currentThread().getName()+",paymentInfoTimeout,id:"+id+",超时"+sleepTime+"秒钟";}/*** @param id* @return {@link String }* @描述 这个方法的返回结果就会作为原方法的返回结果* @author Earl* @version 1.0.0* @创建日期 2023/10/30* @since 1.0.0*/public String paymentInfoTimeoutHandler(Integer id){return "支付服务调用方法超时兜底,参数id会由原方法自动传递进来:"+id;}在启动类上添加@EnableCircuitBreaker注解启动服务降级功能
xxxxxxxxxxpublic class PaymentHystrixApplication {public static void main(String[] args){SpringApplication.run(PaymentHystrixApplication.class,args);}}服务执行方法降级效果演示
有意思的是,这个线程和开始处理原始方法的线程不同,原来的是http-nio-8006-exec-101,执行兜底方法以后是HystrixTimer-1,即执行兜底方法的线程和原来的线程间存在隔离
最怕系统调用随着请求越多,越来越慢,越来越慢,最终CPU和内存打满,整个系统崩溃

注意原方法发生任何异常都会执行兜底方法,比如运算除0异常
注意这个线程池的命名也是单独的,既不是超时的命名方式,也不是原生tomcat默认的方式
而且后端控制台也没有显示异常信息,这个拍错不是就麻烦了

服务调用方的超时问题
就是调用端不愿意继续等服务端的响应了此时也需要服务降级保护,避免超时异常信息直接返回给用户,或者执行备选操作
这个意义上的服务降级都放在服务调用端
注意:配置的热部署对java代码的改动感知明显,但是对@HystrixCommand内属性的修改不明显,一般对该注解的属性更改后重启微服务
感觉讲的有问题,效果和写法都和服务端是一样的,那我为啥还单独声明出来呢,配置文件的配置也只是针对@FeignClent注解中的fallback属性
在服务调用端的配置文件中开启feign对hystrix的功能支持
可以直接在@FeignClent注解中的fallback属性指定回调的类,注意这里讲错了,不能添加这个注解,添加了这个注解怎么弄都会调用该服务调用端的兜底方法,必须注释掉,经过测试注释掉就正常,没注释就永远调用兜底方法,课程根本没有演示服务调用成功的情况
ok,再次反转:
controller中超时时间配置不生效原因: 关键在于feign:hystrix:enabled: true的作用,官网解释“Feign将使用断路器包装所有方法”,也就是将@FeignClient标记的那个service接口下所有的方法进行了hystrix包装(类似于在这些方法上加了一个@HystrixCommand),这些方法会应用一个默认的超时时间为1s,所以你的service方法也有一个1s的超时时间,service1s就会报异常,controller立马进入备用方法,controller上那个3秒那超时时间就没有效果了。 改变这个默认超时时间方法: hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 3000 然后ribbon的超时时间也需加上 ribbon: ReadTimeout: 5000 ConnectTimeout: 5000
配置文件这里的 timeoutInMilliseconds 并不是覆盖注解中的设置,而是两者取较低值, 同时也会算上 ribbon: ReadTimeout 的值,也就是三者取最低值。
xxxxxxxxxxserverport80springapplicationnameservice-hystrix-order#eureka配置信息eurekaclient#将当前服务注册到EurekaServer中register-with-eurekatrue#从EurekaServer抓取已有注册信息,默认为true,单节点无所谓,集群必须设置为true配合ribbon使用负载均衡fetch-registrytrueservice-urldefaultZonehttp//eureka7001.com7001/eurekaribbonReadTimeout5000ConnectTimeout5000#开启客户调用端的feign对hystrix功能的支持feignhystrixenabledtrue#使用feign.hystrix.enabled=true,会导致@FeignClient标注下的所有方法都进行hystrix包装,会应用默认的超时时间1s,#如果其他地方的时间超过1s,过了1s立刻就会抛异常,立即进入兜底方法,这也是一直调用兜底方法的原因#这个时间和ribbon的设置时间无关,改变这个默认时间需要以下配置,这个默认时间大于具体方法配置的时间,就采纳对应方法的超时时间hystrixcommanddefaultexecutionisolationthreadtimeoutInMilliseconds3000在启动类上添加@EnableHystrix注解开启服务降级功能
@EnableHystrix继承了@EnableCricuitBreaker,在服务端启动类上可以把@EnableCricuitBreaker改成@EnableHystrix,也能起到同样的效果
在调用的方法上用同样的方式@HystrixCommand注解设置兜底方法
如果超时就不等那边响应,直接去执行兜底方法,就是和第一个服务降级情况是完全一样的,添加了那个属性反而会出问题
如果本方法出现异常一样会执行兜底方法
xxxxxxxxxxpublic class OrderHystrixController {private PaymentHystrixClient paymentHystrixClient;("/consumer/payment/hystrix/ok/{id}")public String paymentInfoOk( ("id") Integer id){return paymentHystrixClient.paymentInfoOk(id);}("/consumer/payment/hystrix/timeout/{id}")(fallbackMethod = "paymentInfoTimeoutHandler",commandProperties = {(name="execution.isolation.thread.timeoutInMilliseconds",value = "1500")})public String paymentInfoTimeout( ("id") Integer id){int age=10/0;return paymentHystrixClient.paymentInfoTimeout(id);}public String paymentInfoTimeoutHandler( ("id") Integer id){return "支付服务器噶了,完全没响应,老弟半小时后再来吧或者自己运行出错";}}
这种服务降级存在的问题
每个业务都对应各自的服务降级,业务处理和处理异常服务降级的代码揉到一块耦合度极高,代码膨胀
解决办法代码膨胀和高耦合,弄一个全局通用的兜底方法,让大多数方法服务降级都走该兜底方法;特殊方法的兜底方法单独定制
全局服务降级
第一是大量服务调用方法的服务降级采用全局服务降级,部分服务采用定制化服务降级;第二是对服务调用接口做统一的服务降级,一方面避免对服务调用的服务降级与业务代码耦合,另一方面作为没有指定服务降级的服务调用在遇到服务器宕机情况下的服务降级处理【遵循先指定,再全局,最后服务调用的服务降级策略】
经过测试,有指定服务降级任何异常和服务调用异常【宕机】都会执行指定服务降级;如果配置了全局服务降级同理都会去执行全局服务降级;两种服务降级都没有指定的情况下,服务器宕机后才会自动去执行服务调用的服务降级
操作步骤
在业务类上用@DefaultProperties注解的defaultFallback指定方法名
该类中没有特别用@HystrixCommand指明就用统一全局的兜底方法,除了个别重要的核心业务定制兜底方法,其他普通业务都通过@DefaultProperties统一进行服务降级,通用和独享各自分开,避免代码膨胀,减少代码量【注意:使用全局服务降级的方法还是要加@HystrixCommand注解,只是fallbackMethod不指明具体的服务降级方法;没有@HystrixCommand注解表示没有服务降级的事,该等待等待,该抛异常抛异常】
xxxxxxxxxx(defaultFallback = "orderGlobalFallback")public class OrderHystrixController {...定义全局服务降级方法
xxxxxxxxxx/*** @return {@link String }* @描述 全局的服务降级fallback* @author Earl* @version 1.0.0* @创建日期 2023/10/30* @since 1.0.0*/public String orderGlobalFallback(){return "全局服务降级及异常处理信息,请稍后再尝试";}
避免服务降级和业务代码耦合度高的设计
常见需要降级的场景:运行时异常、处理超时异常、服务调用过程中服务器宕机
这里的思路其实就是把服务调用的服务降级限制在服务调用接口的规范中,让应用单独去处理自身执行过程中的服务降级
用处理宕机异常做演示
这个配置可以解决没有做服务降级的服务调用在服务器宕机的情况下执行全局的服务调用异常服务降级,理解成就是对于没有做服务降级的服务调用方法,万一遇到服务宕机的情况没有服务降级可用,这时候可以直接执行服务调用的服务降级,避免服务器突然宕机导致的服务调用方挂起耗死服务器并执行兜底方法
整合所有的服务降级,先走指定服务降级、没有指定服务降级走全局服务降级,【指定服务降级和服务调用的降级不会冲突吗?全局服务降级不会和服务调用的降级冲突吗】
创建一个服务调用接口的实现类统一对服务调用的服务降级进行处理,需要用组件的方式注入IoC容器
xxxxxxxxxxpublic class PaymentHystrixFallback implements PaymentHystrixClient {public String paymentInfoOk(Integer id) {return "ok方法服务调用服务降级";}public String paymentInfoTimeout(Integer id) {return "timeout方法服务调用服务降级";}}添加配置文件配置项
就是feign.hystrix.enabled=true要打开
xxxxxxxxxx#开启客户调用端的feign对hystrix功能的支持feignhystrixenabledtrue@FeignClient注解添加fallback属性为实现类
xxxxxxxxxx(name="service-hystrix-payment",fallback = PaymentHystrixFallback.class)public interface PaymentHystrixClient {("/payment/hystrix/ok/{id}")public String paymentInfoOk( ("id") Integer id);("/payment/hystrix/timeout/{id}")public String paymentInfoTimeout( ("id") Integer id);}测试
启动eureka、payment8006和order服务
通过order访问payment的ok方法
把payment服务关了,模拟宕机
再次访问ok方法进入服务调用的fallback
实现当服务器宕机,服务调用端能自己调用提示,不会让服务调用端在服务不可用时挂起耗死服务器且能获取提示信息
通过order访问payment的timeout方法【关闭了payment服务器】
此时有运行时异常响应指定服务降级,
目标服务器宕机执行的也是指定服务降级
经过测试,有指定服务降级任何异常和服务调用异常【宕机】都会执行指定服务降级;如果配置了全局服务降级同理都会去执行全局服务降级;两种服务降级都没有指定的情况下,服务器宕机后才会自动去执行服务调用的服务降级
服务熔断
熔断机制是应对血崩效应的一种微服务链路保护机制,当扇出链路的某个微服务出错不可用或者响应时间太长时会进行服务降级,熔断该节点的微服务调用,快速返回错误信息,当检测到该节点微服务调用响应正常后,恢复调用链路,熔断机制基于Hystrix自动监控微服务间调用的状况,失败调用到达一定阈值【缺省情况下是5s内20次调用失败】,就会启动熔断机制,熔断机制的注解是@HystrixCommand
当达到最大服务访问后直接拒绝访问,调用服务降级的方法禁止服务访问并返回友好提示,请求量下去以后恢复调用链路【相当于电池电量满了直接断电,发现电池电量下去以后再自动恢复供电】
熔断也可以看做一种服务降级,和服务降级的区别是服务降级每次都会先调用原服务方法,调用失败才会执行服务降级方法;服务熔断状态会直接调用服务降级方法
相关论文:https://martinfowler.com/bliki/CircuitBreaker.html【martin Fowler:分布式架构的提出者,连接是他的博客】
服务熔断的简单原理
原理图
设置服务器并发上限,超过该上限,服务自动熔断,熔断后发现某时刻开始并发量下去了,开启半开状态,开放部分请求对服务的访问,如果这些服务都能正常访问和响应【不存在超时响应】,再完全开放所有请求对服务的访问
三种状态:闭合、断开、半开
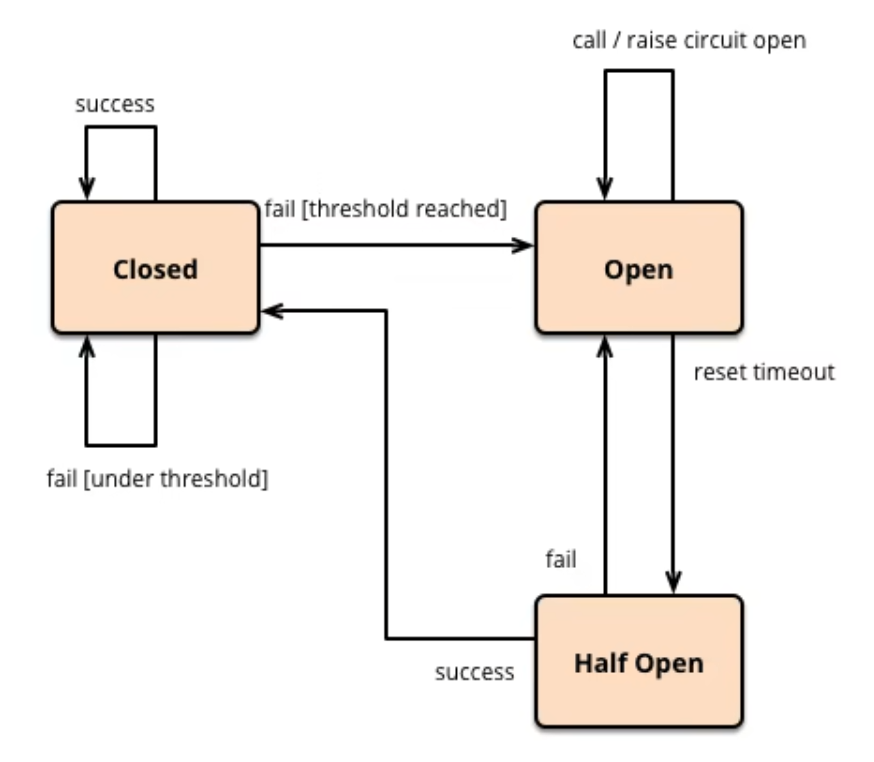
熔断案例演示
修改12模块基础上实现
Hystrix的博文:【整理】互联网服务端技术体系:熔断机制的设计及Hystrix实现解析 - 琴水玉 - 博客园 (cnblogs.com)
service方法
xxxxxxxxxx(fallbackMethod = "paymentCircuitBreakerFallback",commandProperties = {//这些属性可以去HystrixCommandProperties类里面看,没配置准备了默认值,配置了就注入用户配置的//是否开启断路器(name="circuitBreaker.enabled",value="true"),//时间窗口期内的请求次数阈值,默认是20个,超过该阈值断路器工作,threshold是阈值的意思(name="circuitBreaker.requestVolumeThreshold",value="10"),//熔断时间窗口期,单位毫秒,这里表示10s钟,意思是熔断多少秒后开始尝试恢复,默认为5s,在这个窗口期内尝试单个请求是否正常,如果请求失败,则断路器维持断开状态,请求成功再讲断路器置于close状态,// 即正常放行请求,这里暂时理解成窗口期和熔断多长时间后尝试恢复的时间长度是一样的,但是是两个不同的时间段,//查看博文了解到,hystrix用于统计的时间窗口默认是10s,对应一个十个桶的滑动窗口,每个桶负责记录1秒内的成功量、失败量、超时量和拒绝量;拒绝量指信息号/线程池资源检查中被拒绝的请求数量,计算// 10s内即一个滑动窗口的数据需要将十个桶的数据相加,多个桶是放在AtomicReferenceArray<Bucket>中维护的,为了让窗口滑动起来,数组大小默认是11,确定的1s内只有一个桶的数据被更新,其他桶的数据没有变化,// 这个时间和sleepWindowInMilliseconds不同,sleepWindowInMilliseconds确实是熔断后多长时间再尝试恢复//博文地址:https://www.cnblogs.com/frankcui/p/14461258.html(name="circuitBreaker.sleepWindowInMilliseconds",value="10000"),//失败率达到多少后跳闸,默认是50%,这里是失败率达到百分之六十,即一段时间内请求调用服务降级的百分比超过60%,就直接熔断,这里的统计要看// 源码才行,如果这个失败率取默认的前10s,但是前十秒都没有请求,突然来一个失败的服务降级如果只是简单的考虑十秒内失败率,那么失败率100%,// 就会直接导致熔断,但是事实上这种情况没有发生(name="circuitBreaker.errorThresholdPercentage",value="60")})public String paymentCircuitBreaker(("id") Integer id){if(id<0){throw new RuntimeException("id不能为负数!!!");}//糊涂包下的IdUtil工具类,相当于UUID.RandomUUID().toString().replace('_',"");,获取随机UUID并去掉下划线//Hutool是一个Java工具包类库,对文件,流,加密解密,转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类//官网:hutool.cn,涉及内容包括日期工具、HTTP客户端、类型转换、配置文件工具、日志工具、JDBC工具类String serialNumber = IdUtil.simpleUUID();return Thread.currentThread().getName()+"\t"+"正常调用,流水号:"+serialNumber+",id:"+id;}public String paymentCircuitBreakerFallback(("id") Integer id){return "id不能为负数,请稍后再试,id:"+id;}controller
xxxxxxxxxx//====服务熔断("/payment/hystrix/break/{id}")public String paymentCircuitBreaker(("id") Integer id){String result = paymentService.paymentCircuitBreaker(id);log.info("result:"+result);return result;}测试
启动eureka7001和payment12模块
测试通过id为正为负判断抛异常的方式来服务降级和正常运行
【正常运行结果】

【服务降级】
连续多次发送id为负的请求多次服务降级达到当前向前10s默认窗口时间内失败率60%以上实现服务熔断
测试服务熔断期间id为正的请求也发生服务降级,一段时间后【从熔断到正常默认是5s,这里可能为了效果明显设置成10s,但是由于不知道何时发生的熔断,所以时间肯定小于10s】id为正能够正常访问
注意,服务熔断后一切方法都去执行服务降级,短时间内不再执行正常服务
详细说明
circuitBreaker.requestVolumeThreshold:默认当前时间往前十秒内【这个的术语叫做快照时间窗,即统计数据的时间范围】的最大请求次数阈值【这个叫请求总数阈值,是快照时间窗内的熔断触发请求次数阈值,如果请求次数不超过该阈值,即使所有的请求都超时或者其他原因失败,熔断器都不会打开?那还有失败率什么事,没超全部失败都不熔断,超了直接熔断?这里理解成超过请求阈值才考虑请求失败率,经过测试,这个阈值到了以后不会直接触发熔断,而是满足这个阈值才会去检验熔断器的熔断条件,比如服务降级的比例,前面的说法超过阈值直接熔断的说法是错误的】,超过就熔断,默认是20个这个10s是用一个size为11的环形数组,每个元素是一个桶,一共10个桶,多出来一位让滑动窗口滑动起来,桶中的数据包括这一秒内的成功量、失败量、超时量和拒绝量,每秒只更新一个桶,其他桶的数据不变
circuitBreaker.sleepWindowInMilliseconds:熔断发生多长时间后尝试恢复正常服务调用,默认是5scircuitBreaker.errorThresholdPercentage:默认当前时间往前十秒内的服务降级百分比阈值,超过就熔断,默认是50%【这个叫错误百分比阈值:当请求总数在快照时间窗超过阈值,触发对请求数据的统计,如果这些调用中的失败率达到阈值,断路器才会熔断,否则是不会熔断的】这里的逻辑不清楚,要看源码,如果简单的理解会导致十秒内只有一个请求且服务降级了会马上进入服务熔断
服务熔断参数汇总
服务熔断的参数都在HystrixCommandProperties类中
查一下hystrix内部设置时钟一般为MTTR【平均故障处理时间】,当打开时长达到所设时钟进入半熔断状态
参数 描述 默认值 circuitBreaker.enabled 确定断路器是否用于跟踪运行状况和短路请求(如果跳闸)。 默认值为true circuitBreaker.requestVolumeThreshold 熔断触发的最小个数/10s 默认值:20 circuitBreaker.sleepWindowInMilliseconds 熔断多少秒后去尝试请求 默认值:5000 circuitBreaker.errorThresholdPercentage 失败率达到多少百分比后熔断 默认值:50【主要根据依赖重要性进行调整】 circuitBreaker.forceOpen 属性如果为真,强制断路器进入打开(跳闸)状态,其中它将拒绝所有请求 默认值为false,此属性优先于circuitBreaker.forceClosed circuitBreaker.forceClosed 属性如果为真,强制断路器进入打开(跳闸)状态,其中它将拒绝所有请求 默认值为false,如果是强依赖,应该设置为true, circuitBreaker. forceOpen属性优先,因此如果forceOpen设置为true,此属性不执行任何操作。
总结
熔断打开:相当于熔断器打开,内部设置时钟一般为MTTR【平均故障处理时间】,当打开时长达到所设时钟则进入半熔断状态
这里MTTR就是说打开熔断后到达了窗口期的时间后尝试恢复一次
熔断关闭:相当于熔断器关闭,服务正常调用
熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断【这个讲的很水,都不知道是哪一段时间】
官网流程图
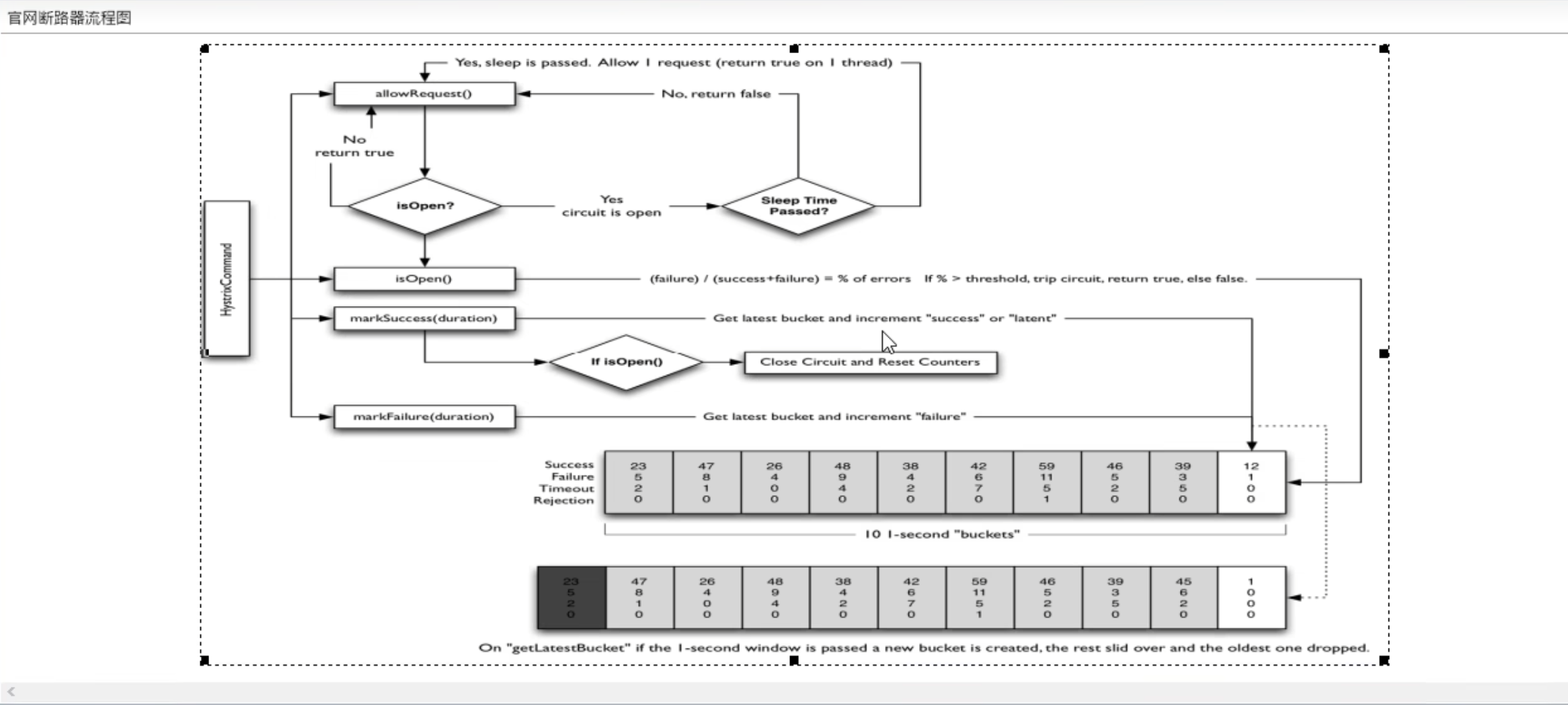
断路器开启的条件
在同时满足请求总量达到请求阈值,服务降级的比例达到阈值,熔断器才会熔断,熔断器开启期间,所有请求都会服务降级,熔断时间窗口期过去后,熔断器处于半开状态,会让其中一个请求走正常流程,如果成功,熔断器关闭,服务恢复正常;如果失败,贼熔断继续开启,并重新计算熔断时间窗口期并再次进行尝试
设计思想
通过熔断器,实现自动发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果
主逻辑恢复:断路器打开,对主逻辑熔断后,hystrix启动一个休眠时间窗,这个时间窗内降级逻辑成为临时的主逻辑,休眠时间窗到期后,熔断器进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,断路器闭合服务恢复正常,主逻辑恢复;如果本次请求依然出问题,断路器继续进入打开状态,休眠时间床重新计时
Hystrix的其他配置【花活】
xxxxxxxxxx//========================All(fallbackMethod = "str_fallbackMethod",groupKey = "strGroupCommand",commandKey = "strCommand",threadPoolKey = "strThreadPool",commandProperties = {// 设置隔离策略,THREAD 表示线程池 SEMAPHORE:信号池隔离(name = "execution.isolation.strategy", value = "THREAD"),// 当隔离策略选择信号池隔离的时候,用来设置信号池的大小(最大并发数)(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),// 配置命令执行的超时时间(name = "execution.isolation.thread.timeoutinMilliseconds", value = "10"),// 是否启用超时时间(name = "execution.timeout.enabled", value = "true"),// 执行超时的时候是否中断(name = "execution.isolation.thread.interruptOnTimeout", value = "true"),// 执行被取消的时候是否中断(name = "execution.isolation.thread.interruptOnCancel", value = "true"),// 允许回调方法执行的最大并发数(name = "fallback.isolation.semaphore.maxConcurrentRequests", value = "10"),// 服务降级是否启用,是否执行回调函数(name = "fallback.enabled", value = "true"),// 是否启用断路器(name = "circuitBreaker.enabled", value = "true"),// 该属性用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为 20 的时候,// 如果滚动时间窗(默认10秒)内仅收到了19个请求, 即使这19个请求都失败了,断路器也不会打开。(name = "circuitBreaker.requestVolumeThreshold", value = "20"),// 该属性用来设置在滚动时间窗中,表示在滚动时间窗中,在请求数量超过// circuitBreaker.requestVolumeThreshold 的情况下,如果错误请求数的百分比超过50,// 就把断路器设置为 "打开" 状态,否则就设置为 "关闭" 状态。(name = "circuitBreaker.errorThresholdPercentage", value = "50"),// 该属性用来设置当断路器打开之后的休眠时间窗。 休眠时间窗结束之后,// 会将断路器置为 "半开" 状态,尝试熔断的请求命令,如果依然失败就将断路器继续设置为 "打开" 状态,// 如果成功就设置为 "关闭" 状态。(name = "circuitBreaker.sleepWindowinMilliseconds", value = "5000"),// 断路器强制打开(name = "circuitBreaker.forceOpen", value = "false"),// 断路器强制关闭(name = "circuitBreaker.forceClosed", value = "false"),// 滚动时间窗设置,该时间用于断路器判断健康度时需要收集信息的持续时间(name = "metrics.rollingStats.timeinMilliseconds", value = "10000"),// 该属性用来设置滚动时间窗统计指标信息时划分"桶"的数量,断路器在收集指标信息的时候会根据// 设置的时间窗长度拆分成多个 "桶" 来累计各度量值,每个"桶"记录了一段时间内的采集指标。// 比如 10 秒内拆分成 10 个"桶"收集这样,所以 timeinMilliseconds 必须能被 numBuckets 整除。否则会抛异常(name = "metrics.rollingStats.numBuckets", value = "10"),// 该属性用来设置对命令执行的延迟是否使用百分位数来跟踪和计算。如果设置为 false, 那么所有的概要统计都将返回 -1。(name = "metrics.rollingPercentile.enabled", value = "false"),// 该属性用来设置百分位统计的滚动窗口的持续时间,单位为毫秒。(name = "metrics.rollingPercentile.timeInMilliseconds", value = "60000"),// 该属性用来设置百分位统计滚动窗口中使用 “ 桶 ”的数量。(name = "metrics.rollingPercentile.numBuckets", value = "60000"),// 该属性用来设置在执行过程中每个 “桶” 中保留的最大执行次数。如果在滚动时间窗内发生超过该设定值的执行次数,// 就从最初的位置开始重写。例如,将该值设置为100, 滚动窗口为10秒,若在10秒内一个 “桶 ”中发生了500次执行,// 那么该 “桶” 中只保留 最后的100次执行的统计。另外,增加该值的大小将会增加内存量的消耗,并增加排序百分位数所需的计算时间。(name = "metrics.rollingPercentile.bucketSize", value = "100"),// 该属性用来设置采集影响断路器状态的健康快照(请求的成功、 错误百分比)的间隔等待时间。(name = "metrics.healthSnapshot.intervalinMilliseconds", value = "500"),// 是否开启请求缓存(name = "requestCache.enabled", value = "true"),// HystrixCommand的执行和事件是否打印日志到 HystrixRequestLog 中(name = "requestLog.enabled", value = "true"),},threadPoolProperties = {// 该参数用来设置执行命令线程池的核心线程数,该值也就是命令执行的最大并发量(name = "coreSize", value = "10"),// 该参数用来设置线程池的最大队列大小。当设置为 -1 时,线程池将使用 SynchronousQueue 实现的队列,// 否则将使用 LinkedBlockingQueue 实现的队列。(name = "maxQueueSize", value = "-1"),// 该参数用来为队列设置拒绝阈值。 通过该参数, 即使队列没有达到最大值也能拒绝请求。// 该参数主要是对 LinkedBlockingQueue 队列的补充,因为 LinkedBlockingQueue// 队列不能动态修改它的对象大小,而通过该属性就可以调整拒绝请求的队列大小了。(name = "queueSizeRejectionThreshold", value = "5"),})public String strConsumer() {return "hello 2020";}public String str_fallbackMethod(){return "*****fall back str_fallbackMethod";}
服务限流
放在sentinel里面讲,因为Hystrix已经停更进维,只讲关键的
Hystrix工作流程
Hystrix工作流程
点击图片可以显示Hystrix的工作流程图
构造
HystrixCommand和HystrixObservableCommand的流程和作用差不多,只讲HystrixCommand,因为这个用的比较多
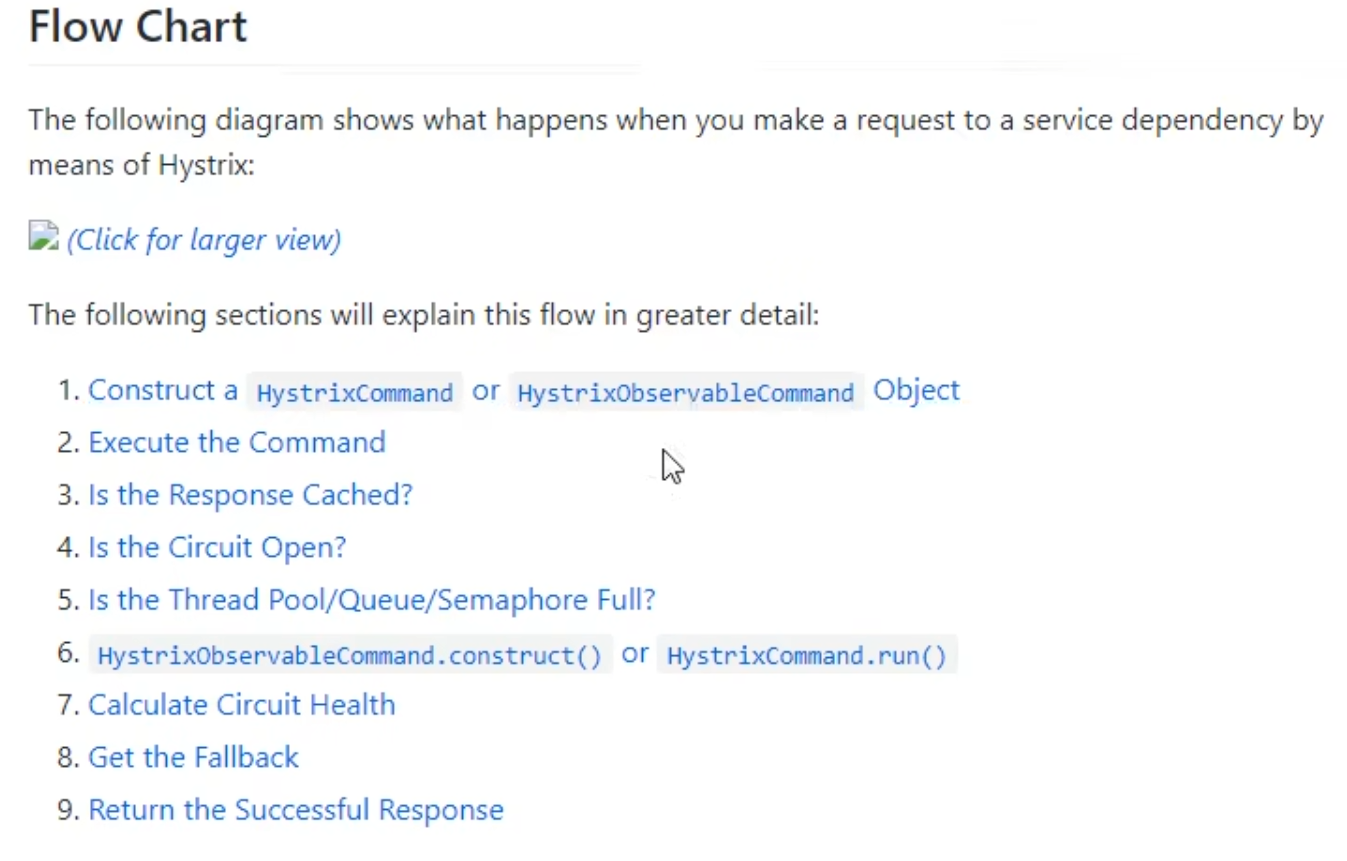
至上到下依次为构造HystrixCommand对象、执行命令、是否响应缓存、熔断是否开启、线程池\队列\信号量是否打满、执行构造方法和run方法、计算熔断器状况、获取服务降级、返回响应
Hystrix工作流程图
蓝色是调用路径、红色是返回路径、黄色的是中间步骤、竖线表示路径成功结束、×表示流程失败
流程大致意思:
在HystrixCommand和HystrixObservableCommand中选择一个作为流程的开始,绿色标记的节点对应上图的执行工作,
缓存命中会直接返回结果;
如果缓存没有,检查断路器是否熔断,如果熔断直接调用服务降级,
如果熔断器没有工作,检查线程池或其他资源是否有空余,如果资源没有结余,仍然调用服务降级;
如果线程池没有被打满,就会根据开始创建的对象选择对应的方法执行业务,HystrixCommand执行run方法返回Observable对象,执行过程中将信息【响应成功或者失败等信息返回给熔断器的数据统计器,根据过往统计数据决定断路器的状态】,
执行失败或者响应超过设置时间会去执行服务降级,
以上情况都没有发生机会返回Observable对象给预设两个对象的toObservable方法

出现服务降级的情况
熔断器处于熔断状态
线程池\队列\信号量打满
业务执行失败【抛出异常】
业务响应超时【超过配置的时间】
细节说明
流程节点 执行细节 1 创建 HystrixCommand(用在依赖的服务返回单个操作结果的时候) 或 HystrixObserableCommand(用在依赖的服务返回多个操作结果的时候) 对象。 2 命令执行。其中 HystrixComand 实现了下面前两种执行方式;而 HystrixObservableCommand 实现了后两种执行方式:execute():同步执行,从依赖的服务返回一个单一的结果对象, 或是在发生错误的时候抛出异常。queue():异步执行, 直接返回 一个Future对象, 其中包含了服务执行结束时要返回的单一结果对象。observe():返回 Observable 对象,它代表了操作的多个结果,它是一个 Hot Obserable(不论 "事件源" 是否有 "订阅者",都会在创建后对事件进行发布,所以对于 Hot Observable 的每一个 "订阅者" 都有可能是从 "事件源" 的中途开始的,并可能只是看到了整个操作的局部过程)。toObservable(): 同样会返回 Observable 对象,也代表了操作的多个结果,但它返回的是一个Cold Observable(没有 "订阅者" 的时候并不会发布事件,而是进行等待,直到有 "订阅者" 之后才发布事件,所以对于 Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程)。 3 若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以 Observable 对象的形式 返回。 4 检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到 fallback 处理逻辑(第 8 步);如果断路器是关闭的,检查是否有可用资源来执行命令(第 5 步)。 5 线程池/请求队列/信号量是否占满。如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满, 那么 Hystrix 也不会执行命令, 而是转接到 fallback 处理逻辑(第8步)。 6 Hystrix 会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。HystrixCommand.run() :返回一个单一的结果,或者抛出异常。HystrixObservableCommand.construct(): 返回一个Observable 对象来发射多个结果,或通过 onError 发送错误通知。 7 Hystrix会将 "成功"、"失败"、"拒绝"、"超时" 等信息报告给断路器, 而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行 "熔断/短路"。 8 当命令执行失败的时候, Hystrix 会进入 fallback 尝试回退处理, 我们通常也称该操作为 "服务降级"。而能够引起服务降级处理的情况有下面几种:第4步: 当前命令处于"熔断/短路"状态,断路器是打开的时候。第5步: 当前命令的线程池、 请求队列或 者信号量被占满的时候。第6步:HystrixObservableCommand.construct() 或 HystrixCommand.run() 抛出异常的时候。 9 当Hystrix命令执行成功之后, 它会将处理结果直接返回或是以Observable 的形式返回。
HystrixDashboard
服务监控仪表盘,就是豪猪哥的web监控画面
除了隔离依赖服务的调用以外,Hystrix还提供了准实时的调用监控(Hystrix Dashboard)
Hystrix会持续地记录所有通过Hystrix发起的请求的执行信息,并以统计报表和图形的形式展示给用户
包括每秒执行多少请求多少成功,多少失败等。
Netflix通过hystrix-metrics-event-stream项目实现了对以上指标的监控。Spring Cloud也提供了Hystrix Dashboard的整合,对监控内容转化成可视化界面。
这个需要自己搭建一个Dashboard监控界面,不方便,阿里巴巴的sentinel对这个进行了优化,直接给网站,登录网站就能看到
dashboard搭建
创建14模块
pom.xml
使用hystrix dashboard需要引入hystrix dashboard依赖和actuator依赖
xxxxxxxxxx<dependencies><!--hystrix的dashboard需要引入spring-cloud-starter-netflix-hystrix-dashboard依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId></dependency><!--hystrix的dashboard需要引入spring-boot-starter-actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8007启动类
启动类上添加@EnableHystrixDashboard注解添加Hystrix的Dashboard功能
xxxxxxxxxx//使用@EnableHystrixDashboard注解开启hystrix dashboard功能public class HystrixDashboardApplication {public static void main(String[] args){SpringApplication.run(HystrixDashboardApplication.class,args);}}所有服务提供微服务都需要配置监控依赖
且必须有spring-boot-starter-web依赖
xxxxxxxxxx<!--这个eureka的注册中心展示细节信息要用,Hystrix的Dashboard也要用--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>所有服务提供者都必须在启动类为服务监控配置下述内容,是SpringCloud本身的坑,因为springboot下的默认路径不是/hystrix.stream,需要在项目中自己配置ServletRegistrationBean对象设置UrlMappings和name属性【如果不配置该组件,点击monitor Stream后会报错Unable to connect to Command Metric Stream.和404】
且确保使用熔断器的注解已经被打开
xxxxxxxxxx//本服务启动后会自动注册进eureka服务中//对hystrixR熔断机制的支持public class MainAppHystrix8001{public static void main(String[] args){SpringApplication.run(MainAppHystrix8001.class,args);}/***此配置是为了服务监控而配置,与服务容错本身无关,springcloud升级后的坑*ServletRegistrationBean因为springboot的默认路径不是"/hystrix.stream",*只要在自己的项目里配置上下面的servlet就可以了*/public ServletRegistrationBean getServlet() {HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);registrationBean.setLoadOnStartup(1);registrationBean.addUrlMappings("/hystrix.stream");registrationBean.setName("HystrixMetricsStreamServlet");return registrationBean;}}图形化界面访问地址:http://localhost:9001/hystrix
通过在地址栏键入特定微服务接口http://localhost:目标微服务端口号/hystrix.stream并点击monitor Stream按钮的方式监控微服务的运行状态

测试
为了避免不必要的错误,先启动hystrix dashboard,再启动使用了hystrix熔断的服务,在此之前还必须先启动注册中心
在Dashboard输入访问微服务的信息并点击monitor Stream
【目标微服务信息】
这个路径不要写错了,写错了会导致找不到对应的监控页面显示

【监控页面】
要发送请求后才会显示数据,否则会显示loading
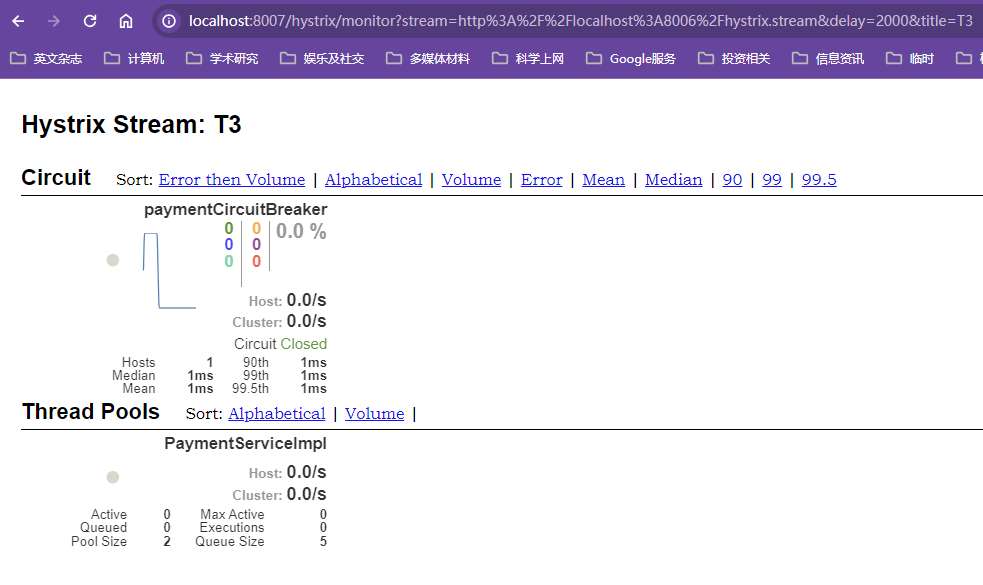
在整合了hystrix熔断器的服务上分别多次请求正常的方法和抛异常的方法进入服务降级触发hystrix熔断,查看hystrix dashboard页面的监控效果
【正常状态下的页面监控】
绿色是请求次数、Circuit closed意思是熔断器没有开启,服务没有被熔断
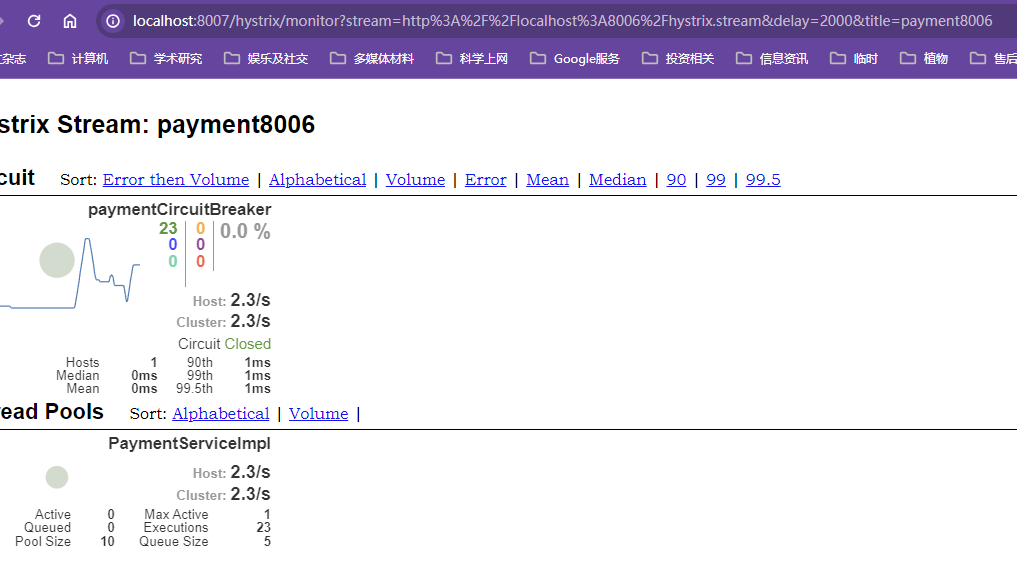
【熔断状态下的页面监控】
Circuit Open意思是熔断器开启,服务处于熔断状态
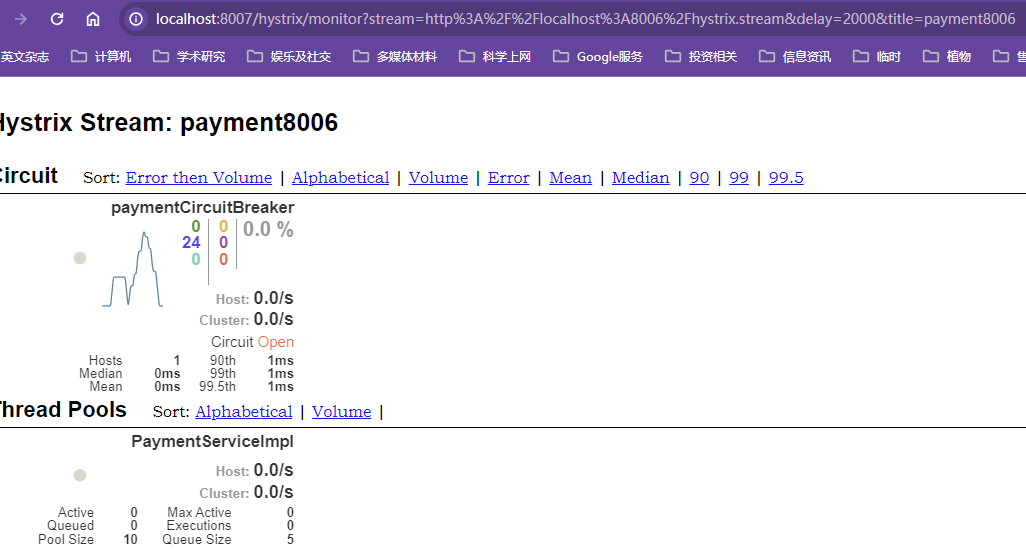
监控参数详解
七色一圈一线
七色
就是监控界面的图例
一圈
就是监控页面的实心圈,
颜色的变化代表了实例的健康程度,它的健康度从绿色<黄色<橙色<红色递减,越红表示越不健康
大小也会根据实例的请求流量发生变化,流量越大该实心圆就越大。所以通过该实心圆的展示,就可以在大量的实例中快速的发现故障实例和高压力实例。
一线
就是监控页面的曲线,记录2分钟内流量的相对变化,可以通过它来观察到流量的上升和下降趋势。
整图详解
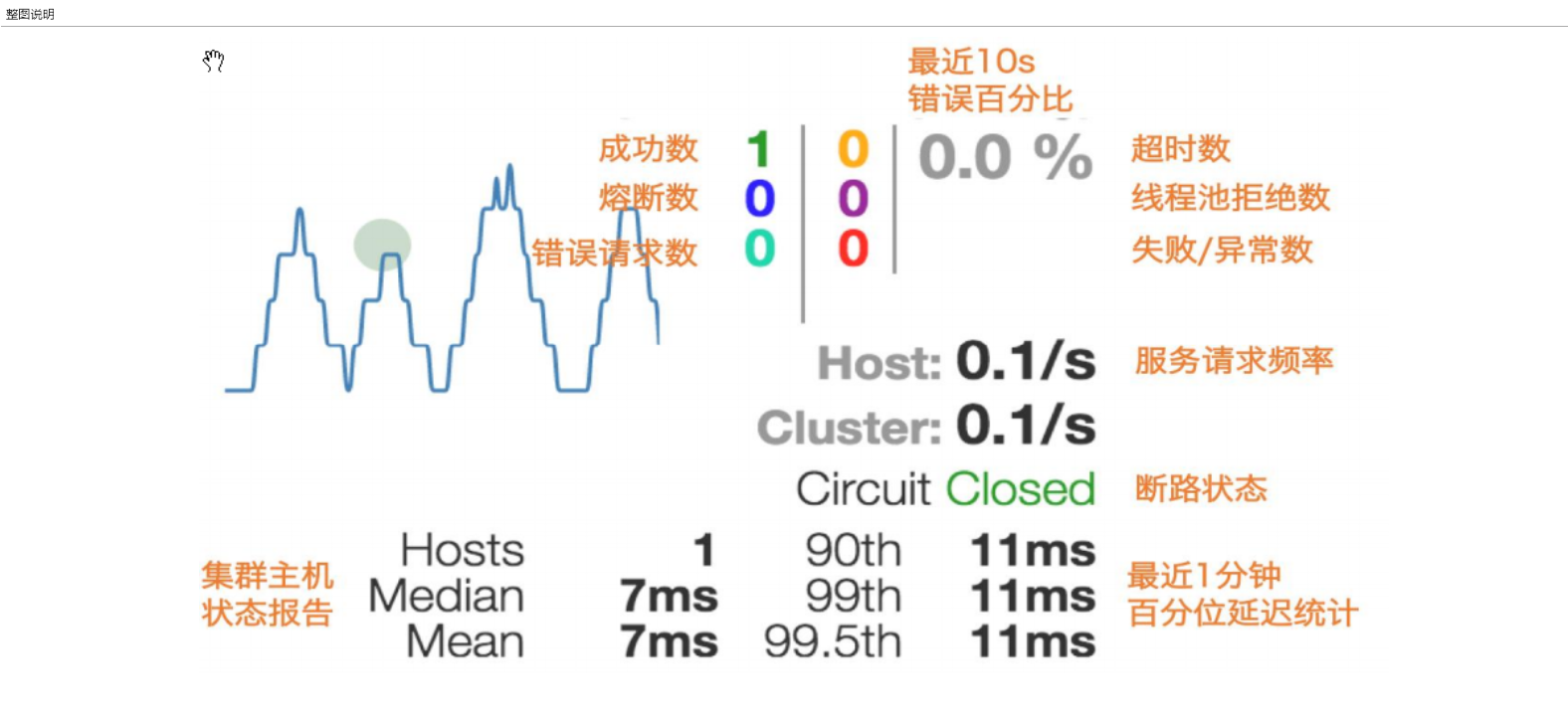
究极版
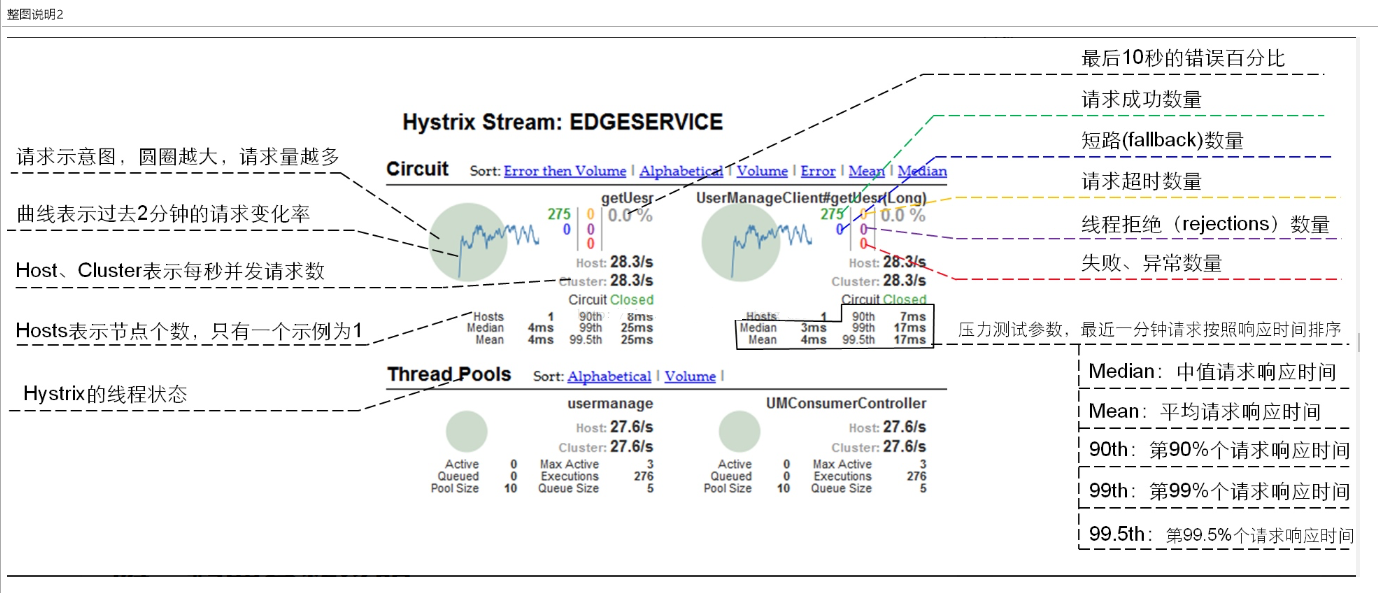
多个服务的监控页面
服务圈圈大,压力大,这个界面没测试过,不知道咋实现的,因为现在访问界面是通过访问单个微服务界面实现的
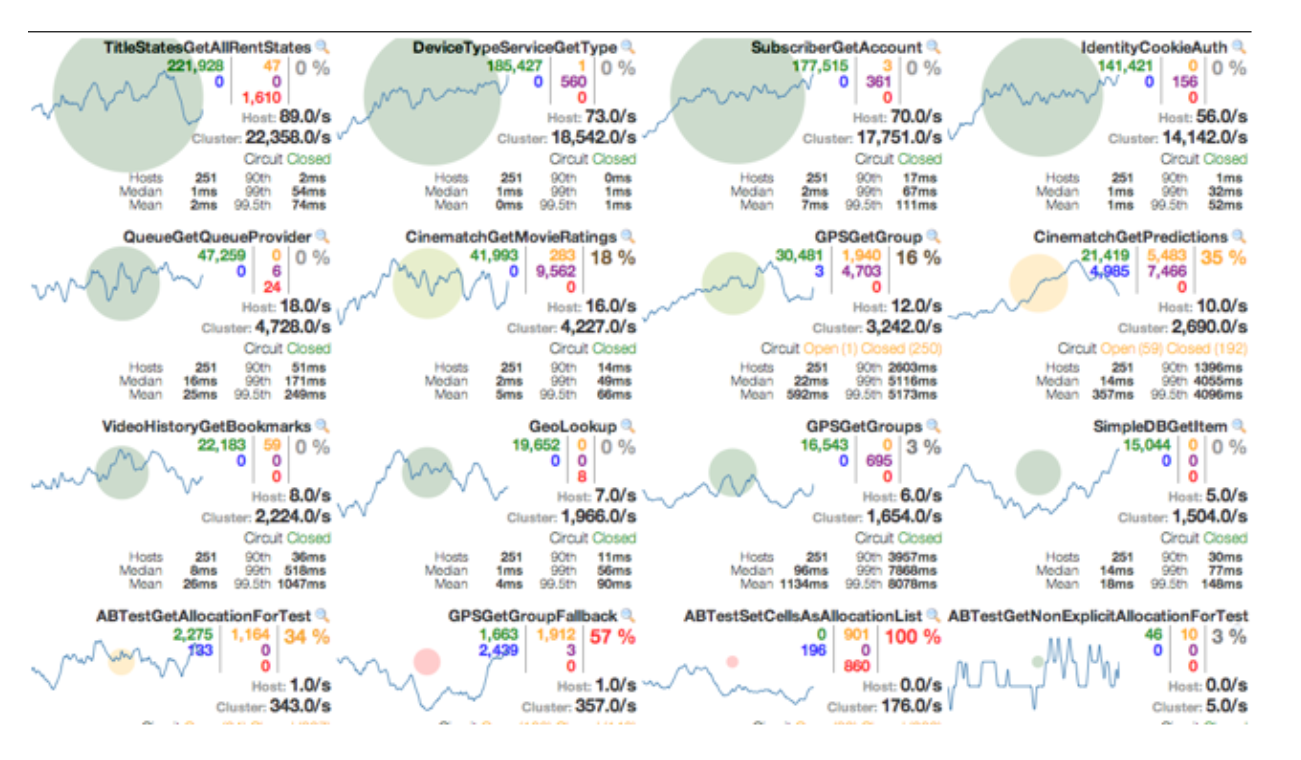
服务网关
几乎所有的微服务架构都有网关,挡在最前面进行日志、限流、权限、安全加固等等工作
类比医院的分诊台对诊断医生进行分配
服务网关以前是zuul,本来zuul打算升zuul2,但是zuul的开发人员跳槽了,zuul停止开发,同时对zuul2的设计出现较大分歧,基本噶了,spring就不等netflix公司了,自己研发一套Gateway作为新一代网关,现在大多用的也是Gateway,这里不讲Zuul,但是脑图有zuul的笔记,需要的时候再拿出来总结到这里,暂时这里只讲Gateway,Gateway也是zuul1.X的替代
Gateway用到了很多Spring5.0以后的新技术
zuul 1.X官网:https://github.com/Netflix/zuul/wiki【woc,zuul2已经发布了,NetFlix作为微服务架构的一代设计者,有传说;但是现在基本上,他的技术都在被替代,Ribbon、Feign、Eureka、Zuul】
Gateway官网:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/html/【Gateway的groupid是SpringCloud,构建于springboot2.x、webFlux、Project Reactor等技术】
Gateway
Gateway旨在提供一种简单有效的方式对API进行路由管理,并提供一些强大的过滤器功能【如熔断、限流、重试等】
在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,使用了Webflux中的reactor-netty响应式编程组件,底层使用了高性能的Reactor模式通信框架Netty,基于异步非阻塞模型开发的,因此在高并发和非阻塞式通信场景下很有优势。【看看老韩的netty】
SpringCloud Gateway的目标是提供统一的路由方式,基于Filter链的方式提供网关的基本功能【如安全、监控、指标、限流等】,网关总是挡在请求的最前面
Gateway的应用场景
反向代理
鉴权
流量控制
熔断
日志监控
一般企业微服务架构网关的位置
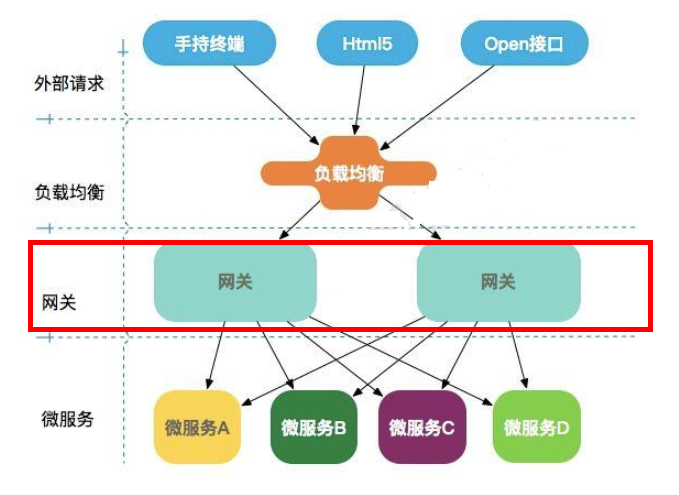
Gateway的特性
动态路由:能够匹配任何请求属性、可以对路由指定Predicate【断言<函数式编程讲过>】和Filter【过滤器】
集成了Hystrix断路器功能
集成了SpringCloud的服务发现功能
易于编写Predicate【断言】和Filter【过滤器】
请求限流功能
支持路径重写
Gateway与zuul的区别
zuul1.X基于阻塞I/O的API,基于Servlet2.5使用阻塞架构【SpringCloud中集成的Zuul版本,用的tomcat,使用传统的Servlet IO处理模型,servlet由servlet Container管理生命周期,container启动时构造servlet对象并调用servlet init()进行初始化;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。container关闭时调用servlet destory()销毁servlet;】,不支持任何长连接【如webSocket】,设计和Nginx很像,每次I/O操作都从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,差别是Nginx用C++实现,Zuul用java实现,JVM本身第一次加载较慢的原因让zuul的性能相对较差,现在玩的都是响应式异步非阻塞式的框架
【servlet的阻塞架构模型】
核心是一个请求对应一个线程,当并发量一大线程数飙升并由于上线文切换巨量消耗内存
缺点:
servlet是一个简单的网络IO模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,在并发不高的场景下这种模型是适用的。
但是一旦高并发(比如抽风用jemeter压),线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。
在一些简单业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势
spring实现了处理所有request请求的一个servlet(DispatcherServlet)并由该servlet阻塞式处理处理。所以Springcloud Zuul无法摆脱servlet模型的弊端
Zuul 2.X想基于Netty非阻塞和支持长连接,相较于zuul1.0在性能方面有较大提升,理念很好,但是出来的慢,被spring摘桃子了
SpringCloud Gateway借鉴了非阻塞API和支持WebSocket,
WebFlux【spring5的新特性,和使用Servlet的SpringMVC是齐名的非阻塞式异步框架】
传统的Web框架,比如说:struts2,springmvc等都是基于Servlet API与Servlet容器基础之上运行的。
Servlet3.1之后有了异步非阻塞的支持。而WebFlux是一个典型非阻塞异步的框架,它的核心是基于Reactor的相关API实现的。相对于传统的web框架来说,它可以运行在诸如Netty,Undertow及支持Servlet3.1的容器上。非阻塞式+函数式编程(Spring5必须让你使用java8)【使用Gateway就是要用servlet3的异步非阻塞特性】
Spring WebFlux 是 Spring 5.0 引入的新的响应式框架,区别于 Spring MVC,它不需要依赖Servlet API,它是完全异步非阻塞的,并且基于 Reactor 来实现响应式流规范。
Gateway的核心概念
Route【路由转发】
构建网关的基本模块、由ID和目标URL、一系列断言和过滤器组成,断言为true则匹配对应的路由
Predicate【断言】
java8的java.util.function.Predicate包【java8新特性有介绍】,开发者可以用断言匹配HTTP请求中的所有内容【例如请求头或者请求参数】
Filter【过滤】
Spring框架中GatewayFilter的实例,使用过滤器在请求被路由前后对请求进行修改【像拦截器】
比如添加附加条件判断,是学校学生可以进入,但是老是迟到在门口罚站半小时或者放学后写个检查
请求进入Gateway后的流程
Web请求通过一些匹配条件定位真正的服务节点,并在转发过程前后通过过滤链进行一些精细化的控制
Predicate就是匹配服务节点的预设条件
filter可以理解为无所不能的拦截器
Predicate+filter链+目标uri就组成了一个具体的路由
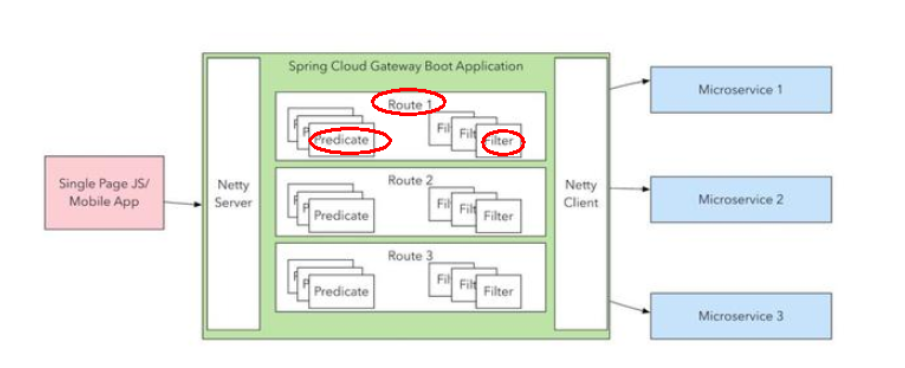
Gateway处理流程
核心逻辑就是路由转发+执行过滤器链
客户端【web请求发送端】向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping【GateWay处理器映射】 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。
Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,执行完由服务器返回给网关,网关再返回给客户端。 过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
Filter在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,
在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等有着非常重要的作用。
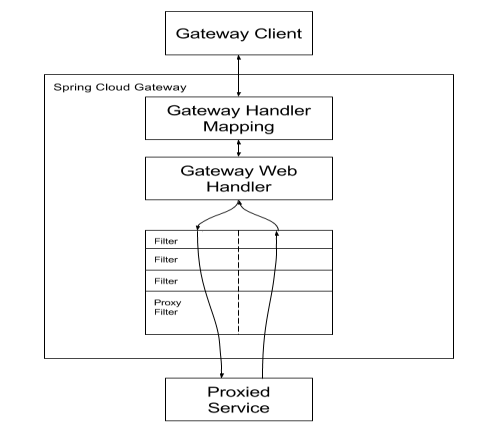
GateWay网关搭建
15模块,使用网关需要服务注册中心,web和webflux不能共存,GateWay中自带webflux,如果有web就会默认使用阻塞式servlet容器,不需要web和actuator
通过在GateWay网关中配置微服务的地址和相应的断言,就可以实现在不暴露端口和ip的情况下通过断言匹配路径对服务进行进行访问
搭建流程
pom.xml
只需要引入网关组件就能自动识别成一个网关
xxxxxxxxxx<dependencies><!--gateway网关依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--eureka-client注册中心客户端依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><!--一般基础配置类--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
配置网关相关的属性,可以对一个微服务设置多个路由使一些服务不可被访问,一些服务可以被访问
存在问题:
路径写死
网关中不能把ip和端口号写死,因为负载均衡很可能涉及到服务器的动态扩容【?确认一下微服务间的相互调用是否经过网关】
服务一般以集群的形式存在,不一定以ip和端口号的形式存在【在这个基础上还要考虑负载均衡】
以前的方式是服务端调用者order集成ribbon,在集群中按负载均衡规则分配指定的服务payment的ip和端口
xxxxxxxxxxserverport9001springapplicationnamecloud-gateway#可以写成多种匹配的断言方式,#cloud:# gateway:# routes:# - id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名# uri: http://localhost:8001 #匹配后提供服务的路由地址# predicates:# - Path=/payment/get/** # 断言,路径相匹配的进行路由# - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名# uri: http://localhost:8001 #匹配后提供服务的路由地址# predicates:# - Path=/payment/lb/** # 断言,路径相匹配的进行路由cloudgatewayroutesidpayment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名urihttp//localhost8006 #匹配后提供服务的路由地址predicatesPath=/payment/hystrix/** # 断言,路径相匹配的进行路由eurekainstancehostnamecloud-gateway-serviceclient#服务提供者provider注册进eureka服务列表内register-with-eurekatruefetch-registrytrueservice-urldefaultZonehttp//eureka7001.com7001/eureka启动类
xxxxxxxxxxpublic class GateWayApplication {public static void main(String[] args){SpringApplication.run(GateWayApplication.class,args);}}
测试
开启注册中心、网关服务、支付服务8006
添加网关前的访问地址为:
http://localhost:8006/payment/hystrix/timeout/1添加网关后的访问地址:
http://localhost:9001/payment/hystrix/timeout/1避免直接暴露微服务的ip和端口
测试效果

以配置类的方式对路由进行配置
使用配置类GatewayConfig.java对路由进行配置
案例:通过网关访问到外网的百度新闻网址【地址栏还是显示访问网关的地址】,关于网关的配置不写在yml中,写成配置类
配置类
在config包下创建配置类
以下几点很重要
build只需要返回的时候写一次,route方法表示向集合中添加元素
id随便写,只需要注入一个RouteLocator对象多次route即可,当然多注入几个也没问题
uri内不要带path中的路径,带上可以实现转发,但是页面内容是以重定向的方式展示的
链接地址更新可能使目标网站对老地址重定向,这种情况网关转发的效果也是重定向
xxxxxxxxxxpublic class GateWayConfig {/*** 配置了一个id为route-name的路由规则,* 当访问地址 http://localhost:9527/guonei时会自动转发到地址:http://news.baidu.com/guonei* 这里转发是到http://news.baidu.com/guonei,也应该显示网关地址,但是由于百度的协议换成https,会自动被重定向成https的网址,* @param builder* @return*/public RouteLocator customRouteLocator(RouteLocatorBuilder builder){RouteLocatorBuilder.Builder routes = builder.routes();//把第22行的build去掉。22行的route只是负责add进List里面的。 整这两个build容易把人弄糊涂。//routes.route("news_guonei", r -> r.path("/guonei").uri("http://news.baidu.com/guonei")).build();//routes.route("news_guonei", r -> r.path("/guonei").uri("http://news.baidu.com/guonei"));不写/guonei也可以,会自动在后面加,// 发现一样了就不会加,这里有问题如果uri加了该后缀会直接显示重定向// 既可以用多次route转发至外部链接,也可以注入多个RouteLocator// 如果转发过去的地址已经变更,如http://news.baidu.com/guonei变更为https://news.baidu.com/guonei,被目标服务器自身重定向,那么也将会显示重定向的效果//routes.route("news", r -> r.path("/guonei").uri("https://news.baidu.com.guonei"));routes.route("news", r -> r.path("/guonei").uri("http://news.baidu.com"));routes.route("gzw", r -> r.path("/index.html").uri("http://www.sasac.gov.cn"));routes.route("baidu", r -> r.path("/").uri("https://www.baidu.com"));return routes.build();}public RouteLocator customRouteLocator2(RouteLocatorBuilder builder){RouteLocatorBuilder.Builder routes = builder.routes();routes.route("news_guoji", r -> r.path("/guoji").uri("http://news.baidu.com/guoji"));return routes.build();}}【转发百度】
【转发成功但丢失样式】
【转发百度新闻】
【uri带路径导致的重定向效果】

【网址本身会被目标服务器重定向的效果】
动态路由
默认情况下,默认情况下Gateway会根据注册中心注册的服务列表,以注册中心上微服务名为路径创建动态路由进行转发,从而实现动态路由的功能【conusmer是走微服务内部调用,那个ribbon集成在消费者身上,这个是浏览器直接访问payment服务,直接通过网关实现负载均衡,意思就是通过网关动态路由的方式通过指定集群服务名,在网关实现负载均衡,默认也是轮询策略】
动态路由指网关利用微服务名从注册中心动态获取集群的ip和端口号,根据负载均衡策略动态生成路由指定要访问服务集群中的一个服务
动态路由实现
网关引入eureka-client实现注册中心服务信息拉取
xxxxxxxxxx<!--eureka-client注册中心客户端依赖,向注册中细腻注册,从注册中心拿服务集群数据,在网关实现负载均衡,这里面还是有ribbon--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency>网关配置文件配置配置开启动态路由,并设置uri为lb协议+集群服务名
重点两点:
更改spring.cloud.gateway.discovery.locator.enabled=true开启动态路由功能
xxxxxxxxxxserverport9001springapplicationnamecloud-gateway#可以写成多种匹配的断言方式,还可以更改直接把uri写成外网的,来直接转发到外部网址【但是我这儿显示的是重定向】#cloud:# gateway:# routes:# - id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名# uri: http://localhost:8001 #匹配后提供服务的路由地址,这个uri可以设置成负载均衡uri: lb://service-payment的形式,且可以多次设置# predicates:# - Path=/payment/get/** # 断言,路径相匹配的进行路由# - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名# uri: http://localhost:8001 #匹配后提供服务的路由地址# predicates:# - Path=/payment/lb/** # 断言,路径相匹配的进行路由cloudgateway#开启从注册中心动态创建路由的功能,利用微服务名进行路由,即网关从注册中心动态获取集群的ip和端口号,根据负载均衡策略动态生成路由指定要访问服务集群中的一个服务discoverylocatorenabledtrueroutesidpayment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名#uri: http://localhost:8006 #匹配后提供服务的路由地址urilb//service-payment #需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri的根据,uri告知网关该断言下的服务访问采用动态均衡,并告知网关服务集群的名字predicates#- Path=/payment/hystrix/** # 断言,路径相匹配的进行路由Path=/payment/** # 断言,匹配指定路径的去微服务集群中去匹配对应的所有/payment/**路径eurekainstancehostnamecloud-gateway-serviceclient#服务提供者provider注册进eureka服务列表内register-with-eurekatruefetch-registrytrueservice-urldefaultZonehttp//eureka7001.com7001/eureka
测试
启动服务注册中心eureka7001
启动服务集群payment8001和payment8003【这两基本是一样的,而且都使用eureka注册中心,其他的用的Zookeeper和consul】
启动网关9001
使用
http://localhost:9001/pament/get/1访问Gateway网关,查看响应是否默认的轮询负载均衡策略【响应结果】
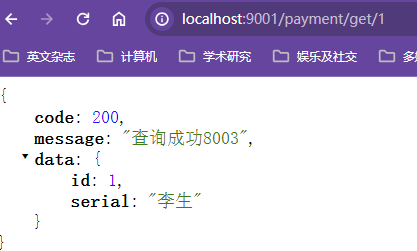
【响应结果】
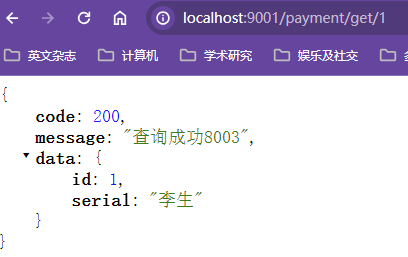
Gateway断言
断言就是为了使请求满足一组匹配规则,让请求过来找到对应的路由,对请求实现更精细化的处理
官方自带的RoutePredicateFactory有十一种之多
官方文档上的介绍
路由断言工厂引言的翻译
Spring Cloud Gateway将路由匹配作为Spring WebFlux HandlerMapping基础架构的一部分。Spring Cloud Gateway包括许多内置的Route Predicate工厂。所有这些Predicate都与HTTP请求的不同属性匹配。
Spring Cloud Gateway 创建 Route 对象时, 使用 RoutePredicateFactory 创建 Predicate 对象,Predicate 对象可以赋值给 Route。用户可以通过逻辑and声明将多种路由断言工厂组合在一起
借助这些断言工厂配置的断言条件可以实现各种各样的附加条件,比如某个请求只能在指定时间点之后才能生效,设置网站只能晚上访问
路由断言工厂的继承结构图
总的yml配置效果
xxxxxxxxxxserver port9001
spring application namecloud-gateway #可以写成多种匹配的断言方式,还可以更改直接把uri写成外网的,来直接转发到外部网址【但是我这儿显示的是重定向】 #cloud: # gateway: # routes: # - id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 # uri: http://localhost:8001 #匹配后提供服务的路由地址,这个uri可以设置成负载均衡uri: lb://service-payment的形式,且可以多次设置 # predicates: # - Path=/payment/get/** # 断言,路径相匹配的进行路由 # - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 # uri: http://localhost:8001 #匹配后提供服务的路由地址 # predicates: # - Path=/payment/lb/** # 断言,路径相匹配的进行路由 cloud gateway #开启从注册中心动态创建路由的功能,利用微服务名进行路由,即网关从注册中心动态获取集群的ip和端口号,根据负载均衡策略动态生成路由指定要访问服务集群中的一个服务 discovery locator enabledtrue routesidpayment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 #uri: http://localhost:8006 #匹配后提供服务的路由地址 urilb//service-payment #需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri的根据,uri告知网关该断言下的服务访问采用动态均衡,并告知网关服务集群的名字 predicates #- Path=/payment/hystrix/** # 断言,路径相匹配的进行路由 #- Path=/payment/** # 断言,匹配指定路径的去微服务集群中去匹配对应的所有/payment/**路径Path=/payment/get/segment,/payment/** # 断言,匹配指定路径的去微服务集群中去匹配对应的所有/payment/**路径 # 应用场景,要求什么时候上线,但是害怕来不及服务部署,我就提前部署上线,加上访问断言after要求在某个时间点后才能访问 #- After=2023-11-03T08:43:51.274+08:00[Asia/Shanghai] #断言,请求路径要匹配网关ip:port//payment/**,且时间要亚洲上海时间8:43分以后才能正常访问,现在时间7:48,还没到指定时间,此时无法访问该地址 #- Cookie=username,zzyy #断言,请求中必须含有名为username的cookie,且值为zzyy #- Header=X-Request-Id,\d+ #断言,请求头中必须有名为X-Request-Id的属性,且值必须为正整数 #- Host=**.picture.com,**.world.com #断言,请求头中的Host属性的属性值必须匹配列表中的一项,其中**表示任意 #- Method=GET #断言请求方式必须为getQuery=username,\d+ #断言,请求参数中必须有属性username,且对应的值必须是正整数才能路由
eureka instance hostnamecloud-gateway-service client#服务提供者provider注册进eureka服务列表内 register-with-eurekatrue fetch-registrytrue service-url defaultZonehttp//eureka7001.com7001/eureka
【时间维度】
After
在指定时间后配置的路径才能被访问,否则提示404
配置示例
主要是这个日期格式如何得到,可以使用java中的时间类型生成对应的时间格式
xxxxxxxxxxspring cloud gateway routesidafter_route urihttps//example.org predicatesAfter=2017-01-20T17:42:47.789-07:00America/Denver#这是美国时间该路由匹配 Jan 20, 2017 17:42 Mountain Time (Denver).后的任何请求
转换时间格式的java工具类
用java自带的类java.time.ZonedDateTime来生成Gateway需要的时间格式,这个只演示了当前时间,学一下这个类的api
ZonedDateTime.now()当前时间默认时区
ZonedDateTime.now(ZoneId.of("America/New_York"))当前时间指定时区
xxxxxxxxxxpublic class DateFormatUtil { public static void main(String[] args) { // java.time.ZonedDateTime可以生成Gateway默认时区的时间格式 // 2023-11-03T07:56:50.123+08:00[Asia/Shanghai] ZonedDateTime zbj = ZonedDateTime.now(); // 默认不声明情况下时区是Asia/Shanghai System.out.println(zbj); // 2023-11-02T19:56:50.124-04:00[America/New_York] ZonedDateTime zny = ZonedDateTime.now(ZoneId.of("America/New_York")); // 用指定时区获取当前时间 System.out.println(zny); }}配置文件配置组合断言
xxxxxxxxxxserver port9001
spring application namecloud-gateway #可以写成多种匹配的断言方式,还可以更改直接把uri写成外网的,来直接转发到外部网址【但是我这儿显示的是重定向】 #cloud: # gateway: # routes: # - id: payment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 # uri: http://localhost:8001 #匹配后提供服务的路由地址,这个uri可以设置成负载均衡uri: lb://service-payment的形式,且可以多次设置 # predicates: # - Path=/payment/get/** # 断言,路径相匹配的进行路由 # - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 # uri: http://localhost:8001 #匹配后提供服务的路由地址 # predicates: # - Path=/payment/lb/** # 断言,路径相匹配的进行路由 cloud gateway #开启从注册中心动态创建路由的功能,利用微服务名进行路由,即网关从注册中心动态获取集群的ip和端口号,根据负载均衡策略动态生成路由指定要访问服务集群中的一个服务 discovery locator enabledtrue routesidpayment_routh #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 #uri: http://localhost:8006 #匹配后提供服务的路由地址 urilb//service-payment #需要注意的是uri的协议为lb,表示启用Gateway的负载均衡功能。lb://serviceName是spring cloud gateway在微服务中自动为我们创建的负载均衡uri的根据,uri告知网关该断言下的服务访问采用动态均衡,并告知网关服务集群的名字 predicates #- Path=/payment/hystrix/** # 断言,路径相匹配的进行路由Path=/payment/** # 断言,匹配指定路径的去微服务集群中去匹配对应的所有/payment/**路径 # 应用场景,要求项目什么时候上线,但是害怕来不及服务部署,我就提前部署上线,加上访问断言after要求在某个时间点后才能访问After=2023-11-03T08:43:51.274+08:00Asia/Shanghai #断言,请求路径要匹配网关ip:port//payment/**,且时间要亚洲上海时间8:43分以后才能正常访问,现在时间7:48,还没到指定时间,此时无法访问该地址
eureka instance hostnamecloud-gateway-service client#服务提供者provider注册进eureka服务列表内 register-with-eurekatrue fetch-registrytrue service-url defaultZonehttp//eureka7001.com7001/eureka测试网关访问此前连接的效果
没有到访问时间,展示404
应用场景:
要求项目什么时候上线,但是害怕来不及服务部署,我就提前部署上线,加上访问断言after要求在某个时间点后才能访问
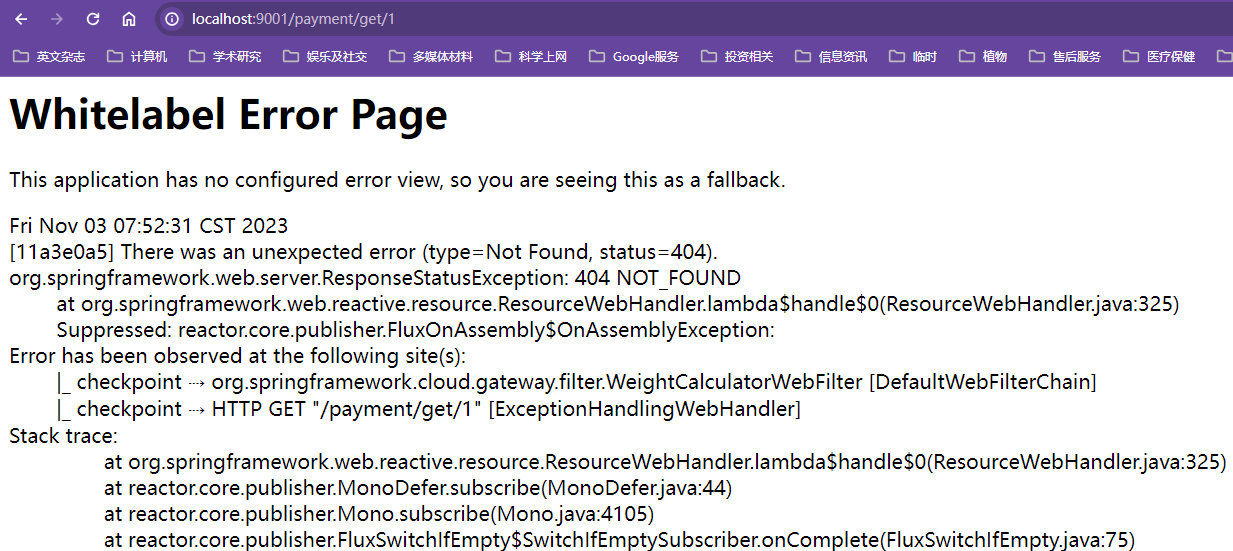
Before
在什么时间之前能够访问,断言设置方式同after
xxxxxxxxxxspring cloud gateway routesidbefore_route urihttps//example.org predicatesBefore=2017-01-20T17:42:47.789-07:00America/DenverBetween
在什么时间之间能够访问,断言设置方式同after,但是这里要设置开始时间【在前】和结束时间,两个时间用逗号隔开
限时活动
xxxxxxxxxxspring cloud gateway routesidbetween_route urihttps//example.org predicatesBetween=2017-01-20T17:42:47.789-07:00America/Denver, 2017-01-21T17:42:47.789-07:00America/Denver【cookie维度】
Cookie
获取预设置的Cookie name对应的value值和预设置的正则表达式匹配,如果匹配上则断言为true,没有匹配上就位false
配置示例
xxxxxxxxxxspring cloud gateway routesidcookie_route urihttps//example.org predicates #请求携带一个名为chocolate的cookie,且值满足正则表达式ch.pCookie=chocolate, ch.p使用curl发送请求做微服务测试
postman是图形化界面,curl就是postman图形化界面的命令底层,curl是windows系统自带的请求发送命令
curl测试环境可能返回中文乱码,生产环境不会带中文乱码,测试环境要解决中文乱码问题:
命令
curl http://localhost:9527/payment/lb什么都没写,就一个地址,相当于发送了一个get请求,没有带cookie
命令
curl http://localhost:9527/payment/lb --cookie "username=zzyy"发送get请求,设置cookie键值对username=zzyy
命令
curl http://localhost:9527/payment/lb -H "X-Request-Id:123"发送get请求,设置请求头中的属性
X-Request-Id:123命令
curl http://localhost:9527/payment/lb -H "Host:www.picture.com"发送get请求,设置请求头的Host属性为www.picture.com
命令
curl -X -POST http://localhost:9001/payment/get/1发送post请求
测试效果
断言设置
- Cookie=username, zzyy【不带cookie】

【带cookie】
Header
请求的请求头中必须带有指定属性名的属性,且属性值必须和正则表达式匹配

官网配置示例
This route matches if the request has a header named
X-Request-Idwhose value matches the\d+regular expression (that is, it has a value of one or more digits).xxxxxxxxxxspringcloudgatewayroutesidheader_routeurihttps//example.orgpredicatesHeader=X-Request-Id, \d+测试效果

Host
在请求头中设置Host属性对应值满足指定域名格式的请求,可以对网关和对应服务进行访问
官网配置示例
这个路由匹配请求的请求头中的Host属性的值为
www.somehost.org或beta.somehost.org或www.anotherhost.org的请求xxxxxxxxxxspringcloudgatewayroutesidhost_routeurihttps//example.orgpredicatesHost=**.somehost.org,**.anotherhost.org测试效果
实际配置
- Host=**.picture.com,**.world.com请求头中的Host属性的属性值必须匹配列表中的一项,其中**表示任意
Method
请求方式必须为指定的请求方式
官网配置示例
请求方式为get或者post都能匹配
xxxxxxxxxxspringcloudgatewayroutesidmethod_routeurihttps//example.orgpredicatesMethod=GET,POST测试效果
实际配置
- Method=GET
Path
当匹配路径包含指定部分可以匹配
官网示例
请求路径为
/red/1or/red/blueor/blue/green.可以进行匹配xxxxxxxxxxspringcloudgatewayroutesidhost_routeurihttps//example.orgpredicatesPath=/red/segment,/blue/segment测试效果
实际配置
- Path=/payment/get/{segment},/payment/**为了验证segment,测试的时候没有添加/payment/**,测试证明segment能够表示单层目录的任意字符,但不能表示多层目录,多层目录需要使用
**,且可以指定路径列表
Query
请求路径中必须带指定参数,且参数值必须满足正则匹配条件
官网示例
【示例1】
只写一个参数表示请求参数中必须含有参数名green
xxxxxxxxxxspringcloudgatewayroutesidquery_routeurihttps//example.orgpredicatesQuery=green【示例2】
写两个参数表名请求参数必须要有red,而且值必须匹配正则表达式gree.
xxxxxxxxxxspringcloudgatewayroutesidquery_routeurihttps//example.orgpredicatesQuery=red, gree.测试效果
实际配置
- Query=username,\d+请求参数中必须有属性username,且对应的值必须是正整数才能路由【经过测试,没有对应参数或者参数值不满足正则匹配都会报404】

GatewayFilter
是Gateway的过滤器实例,使用过滤器链可以针对请求在被路由【服务调用】前或者后对请求进行修改操作
路由过滤器可用于修改进入网关的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用
SpringCloud Gateway内置了多种路由过滤器,这些路由过滤器都由GatewayFilter的工厂类来产生
到死也没讲怎么控制路由过滤器是在请求前执行还是在请求后执行
路由过滤器
生命周期:
像Spring的潜质通知和后置通知
pre:业务逻辑之前
post:业务逻辑之后
种类:
GatewayFilter:单一的路由过滤器,必须指定某个路由
GlobalFilter:全局的路由过滤器,对所有路由生效
路由过滤器工厂
单一路由过滤器工厂的种类有31个,全局路由过滤器的种类有十多个
常用的GatewayFilter
这里只演示了一个AddRequestParameter【向请求的请求头中添加请求参数】,其他的让自己看官网尝试
给的一般也不好用,一般都进行自定义过滤器
在配置文件中添加配置属性
配置方式和断言类似
xxxxxxxxxxspringcloudgatewayroutesfiltersAddRequestParameter=X-Request-Id,1024 #AddRequestParameter会让过滤器工厂会在匹配的请求头加上一对请求头,名称为X-Request-Id值为1024,
用单一路由过滤器演示前置过滤器和后置过滤器
这里没讲,自己找的,
就是在chain.filter(exchange)前的是前置过滤,在chain.filter(exchange).then(Mono.fromRunnable(new Runnable() {})中实现类的run方法中的是后置过滤
还可以通过集成
AbstractGatewayFilterFactory<Object>并重写的apply方法注入没有交给spring管理的过滤器【前置过滤器(请求转发前触发)】
chain.filter(exchange)前执行的方法
xxxxxxxxxxpublic class GetRecordGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {private static final Logger LOGGER = LoggerFactory.getLogger(GetRecordGatewayFilterFactory.class);public GatewayFilter apply(Object config) {return new DDOSCheckGatewayFilter();}static class DDOSCheckGatewayFilter implements GatewayFilter, Ordered {public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {LoggerUtils.info(LOGGER, "请求转发前触发");return chain.filter(exchange);}public int getOrder() {return 0;}}}【后置过滤器(请求完成后触发)】
在then中的Mono.fromRunnable(Runnable的实现类)执行实现类中重写的run方法实现后置过滤器
xxxxxxxxxxpublic class GetRecordGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {private static final Logger LOGGER = LoggerFactory.getLogger(GetRecordGatewayFilterFactory.class);public GatewayFilter apply(Object config) {return new DDOSCheckGatewayFilter();}static class DDOSCheckGatewayFilter implements GatewayFilter, Ordered {public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {return chain.filter(exchange).then(Mono.fromRunnable(new Runnable() {public void run() {LoggerUtils.info(LOGGER, "请求完成后触发");}}));}public int getOrder() {return 0;}}}【前置 + 后置过滤器(请求完成后触发)】
就是上面两个规则的结合,甚至不需要写外面的类,直接把自定义类交给Spring容器管理即可,当然使用apply方法这种注入方式也是一种写法
xxxxxxxxxxpublic class GetRecordGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {private static final Logger LOGGER = LoggerFactory.getLogger(GetRecordGatewayFilterFactory.class);public GatewayFilter apply(Object config) {return new DDOSCheckGatewayFilter();}static class DDOSCheckGatewayFilter implements GatewayFilter, Ordered {public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 进入filter方法,执行chain.filter,都属于请求前阶段LoggerUtils.info(LOGGER, "转发请求前触发");return chain.filter(exchange).then(Mono.fromRunnable(new Runnable() {public void run() {LoggerUtils.info(LOGGER, "请求完成后触发");}}));}public int getOrder() {return 0;}}}
自定义过滤器
自定义全局过滤器
应用场景
全局日志
统一网关鉴权
过滤器构建
filter包下创建自定义类实现GlobalFilter, Ordered接口
filter中做业务处理,
exchange.getResponse().setComplete()是请求拦截并返回,chain.filter(exchange)是请求放行order是该过滤器的优先级,没有指定order会按照过滤器类名确定排序,看看javaWeb,这里没讲
并没有说明过滤器在请求执行前执行还是在请求后执行,讲的比较拉
xxxxxxxxxxpublic class LogGatewayFilter implements GlobalFilter, Ordered {/*** @param exchange 看做封装了请求、响应的参数* @param chain* @return {@link Mono }<{@link Void }> 这个就像springMVC中的ModelAndView* @描述 过滤器方法,判断请求是否带请求参数username,且参数值不能为null,否则认为是非法用户* @author Earl* @version 1.0.0* @创建日期 2023/11/03* @since 1.0.0*/public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {log.info("######LogGatewayFilter过滤器请求校验:"+new Date());String username = exchange.getRequest().getQueryParams().getFirst("username");if(username==null){log.error("=======非法用户名,用户名为null");//对应状态码是406,表示该请求不被服务器接受,前端页面显示网页无法正常运作,请与网站所有者联系exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);//将响应的状态设置为完成,让请求返回给客户端,服务器不受理return exchange.getResponse().setComplete();}//类似于javaweb中的过滤链放行return chain.filter(exchange);}/*** @return int* @描述 这个参数决定过滤器在过滤器链中的位置,数字越小优先级越高,最大的是21亿,最小是-21亿,* @author Earl* @version 1.0.0* @创建日期 2023/11/03* @since 1.0.0*/public int getOrder() {return 0;}}测试效果

配置中心
SpringCloud Config
官网:https://cloud.spring.io/spring-cloud-static/spring-cloud-config/2.2.1.RELEASE/reference/html/
配置中心和服务总线还在更新,配置中心和服务总线都要被nacos取代了
这个使用还是很广泛,一般有三种方案:
Config+Bus
Nacos
携程的阿波罗
应用场景
集群的配置文件过多,改一个就要全改,不方便
代码涉及到开发,测试,生产;不同的环境可能涉及到的配置项不同,一套配置文件不满足需求
构建一套集中式的,动态的配置管理设施,SpringCloud提供ConfigServer配置中心来解决这个问题,使用外部配置支持将配置文件同步到配置中心,本地Git库通过Git连接到github或者gitee等远程库,一般由运维工程师对配置文件一次修改,处处生效
除了git,SpringCloud也可以使用SVN【太老了】和本地文件存储配置文件,最推荐的哈市git,使用http/https的访问形式
SpringCloud分为服务端和客户端,
服务端称分布式配置中心,是一个独立的微服务应用,为客户端提供配置信息,加密解密信息的访问接口
客户端部署在微服务中,用来从配置中心管理获取相关配置内容,在服务启动的时候从配置中心获取和加载配置信息,配置服务器默认采用git来存储配置信息,有助于对环境配置进行版本管理,并通过git客户端工具来方便的管理和访问配置内容
配置中心的结构图
可以实现在github远程库修改配置内容,浏览器也能通过配置中心访问到远程库做出的修改
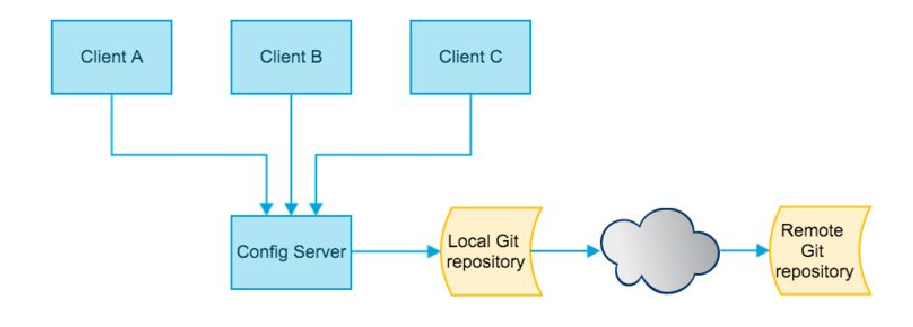
配置中心的作用
集中管理配置文件,运行期间只需要在配置中心动态调整配置,服务就会向配置中心统一拉取配置自己的信息,且配置发生变动时,服务不需要重启就能感知到配置文件的变化并应用新的配置
根据部署环境如dev/test/prod/beta【预发布环境】/release【灰度发布】动态化的配置更新
将配置信息以REST接口的形式暴露
Config服务端配置
创建一个github配置中心仓库
springcloud-config,选择SSH获取仓库链接git@github.com:Earl-Li/springcloud-config.git在本地硬盘新建一个git仓库并用git命令
git clone git@github.com:Earl-Li/springcloud-config.gitclone远程库直接新建文件夹,在该问价夹下调出git的bash窗口,先试用命令
git init初始化本地库,使用命令上述命令克隆远程仓库在本地库创建对应不同生产环境的三个文件,用git命令推送到远程库
【本地修改】

【远程推送】
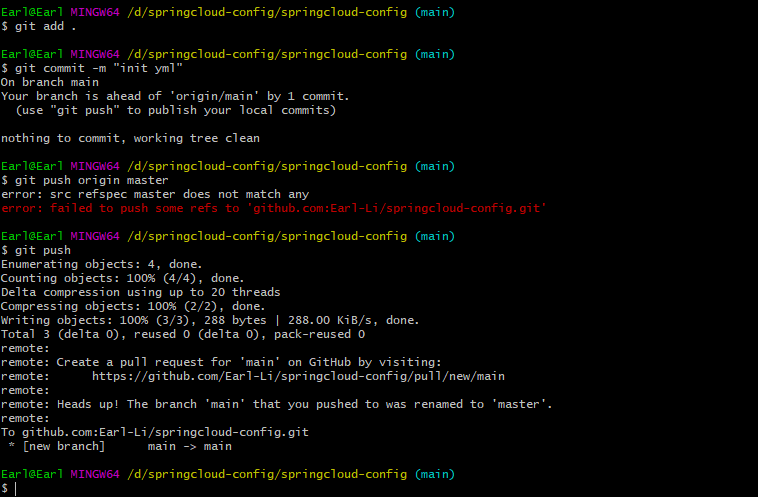
【远程库同步效果】
创建模块16作为配置中心
pom.xml
xxxxxxxxxx<dependencies><!--cloud配置中心服务端--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-config-server</artifactId></dependency><!--服务注册中心Eureka--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--springMVC的web应用--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--web应用配套--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--工具包--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
skip-ssl-validation: true没看出加不加的区别,很神奇这个东西,最开始注册中西启动老是报错,第一次加了这个以后连续启动几次都不报错,但是后来又无区别报错了
使用git协议的链接会报错auth fail,无法链接远程库,使用Https协议偶尔能成功,无论开不开梯子基本上都会报错,神奇的是同样的配置偶尔竟然能够成功,IDEA链接github的成功率很魔幻,基本启动不报错就能正常访问配置文件内容,启动报错基本都GG,也可能启动不报错,连接不到库报错,反正一堆问题
label属性是spring.cloud.config.label=main,这个属性没问题
公开库的访问不需要用户名和密码,私有库的访问需要用户名和密码
注意开着代理使用hosts更改的映射主机会报错502,使用host映射主机名必须关代理
报错也没关系,等久一点说不定就能成功,开梯子大多数时候能够实时更新配置更改,不开梯子大多数时候链接不了远程库,偶尔能成功【真神了】
总之很迷,搞了半天成不成全看运气,不知道gitee效果如何,讲的比我做的还水
用gitee,根本不存在任何问题,而且此时开梯子也不会有任何影响
xxxxxxxxxxserverport9002springapplicationnamecloud-config-center #注册进Eureka服务器的微服务名cloudconfigservergit#uri: git@github.com:Earl-Li/springcloud-config.git #GitHub上面的git仓库名字#https可以访问成功,注意在uri下面配置usrname和password,同时现在应该是访问main而不是master了,2022年GitHub也不支持sha-1了,#uri: https://github.com/Earl-Li/springcloud-config.git #GitHub上面的git仓库名字#uri: git@github.com:Earl-Li/springcloud-config.git #GitHub上面的git仓库名字urihttps//gitee.com/earl-Li/springcloud-config.git #GitHub上面的git仓库名字#远程库的搜索目录search-pathsspringcloud-config#私有库访问需要用户名和密码,公有库访问不需要账户名和密码,为了安全这里不展示用户和密码skip-ssl-validationtrue#default-label: devdefault-labelmain#远程库的读取分支labelmain#label: dev#服务注册到eureka地址eurekaclientservice-urldefaultZonehttp//localhost7001/eureka启动类
主要就是添加注解@EnableConfigServer标记该服务是一个服务注册中心
xxxxxxxxxx//标记该服务是一个服务注册中心public class ConfigCenterApplication {public static void main(String[] args){SpringApplication.run(ConfigCenterApplication.class,args);}}测试效果
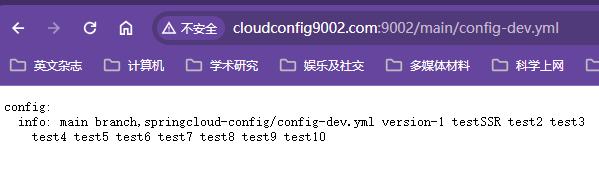
配置读取规则
直接用码云,秒开,没有任何问题,比github在拉取文件方面强多了,可恶的网络,特么的害我搞一上午
核心:优先以请求路径约定的分支读取配置文件,如果请求路径没有配置分支,则读取default-label规定的分支,如果配置文件没有配置default-label,就会使用远程库的默认分支;不会管配置文件中的spring.cloud.config.label属性的,怎么配置该属性都是访问default-label或者默认分支
注意所有的配置文件也要满足{application}-{profile}.yml这个命名格式
官网:https://cloud.spring.io/spring-cloud-static/spring-cloud-config/2.2.1.RELEASE/reference/html/
/{label}/{application}-{profile}.yml
label是git分支,application对应git远程库下的yml文件的"-"前的内容,约定是服务名,profile表示环境【dev、prod、test】,这里即便写了label,但是和配置中心配置文件配置的不一样,会自动以请求路径为主,不会管配置中心的配置
在浏览器通过对应格式的请求路径就能访问到远程库的配置文件内容
直接返回配置文件的内容,原样返回
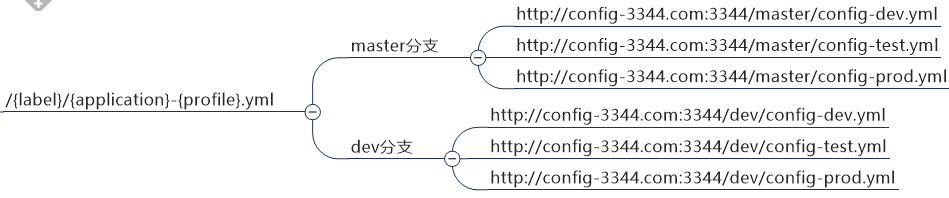
/{application}-{profile}.yml
不配置label标签也没问题,因为服务器中配置了具体的分支,如果服务器中也没配置就获取远程库默认的分支
default-label和label都存在的情况下优先选择default-label
如果没有请求地址对应的配置文件,机会直接返回
{}gitee的默认分支还是master分支,如果不在配置中心配置具体分支,就会去找默认gitee分支master
/{application}/{profile}[/{label}]
把分支写在最后,这种返回配置文件的json串,可以解析json串在代码中获取相关配置信息
不会管配置中心的配置文件指定什么分支,写什么分支就获取对应的分支文件返回json串
这种写法没有限制配置文件是yml还是properties,都可以转成对应的json返回
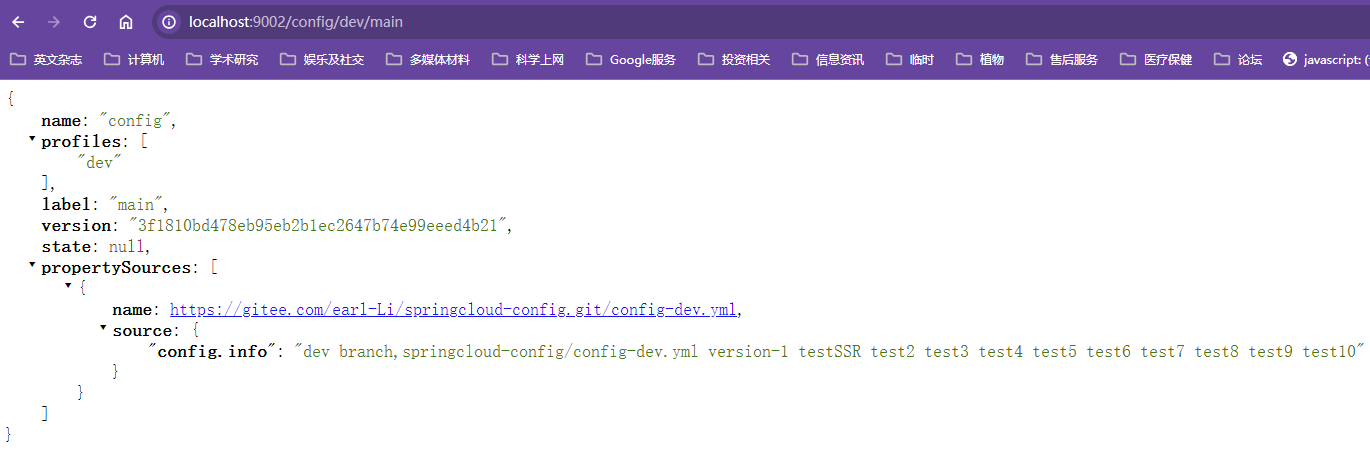
【下面实际上是properties类型配置文件的文件内容请求方式,和yml的用法完全相同,只是配置文件是yml类型】
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
微服务配置客户端
客户端只访问到配置中心,和远程库的同步只由配置中心负责,配置中心会自动和远程库通信隔断时间就同步配置文件
bootstrap是系统级的配置,优先级更高,bootstrap配置配置中心地址,服务先和配置中心沟通获取到application配置文件
bootstrap
没办法课程也是垃圾翻译,读都读不通顺,个人理解就是先加载bootstrap,配置中心客户端根据bootstrap中配置去配置中心获取application.yml【讲一堆垃圾话】
application.yml是用户级的资源配置项,bootstrap.yml是系统级配置项,bootstrap的优先级更高,加载更早,且bootstrap中的配置不会被application.yml的配置覆盖
Spring Cloud会创建一个“Bootstrap Context”,作为Spring应用的
Application Context的父上下文。初始化的时候,Bootstrap Context负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的Environment。
配置中心客户端
模块17
pom.xml
xxxxxxxxxx<dependencies><!--配置中心客户端--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-config</artifactId></dependency><!--注册中心--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--web标配--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--工具包--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>bootstrap.yml
xxxxxxxxxxserverport8008springapplicationnameconfig-clientcloud#Config客户端配置configlabelmain #分支名称nameconfig #配置文件名称profiledev #读取后缀名称#上述3个综合:master分支上config-dev.yml的配置文件被读取http://cloudconfig9002.com:9002/master/config-dev.ymlurihttp//localhost9002 #配置中心地址k#服务注册到eureka地址eurekaclientservice-urldefaultZonehttp//localhost7001/eureka启动类
xxxxxxxxxx//@EnableEurekaClient//不写也能被Eureka注册中心的服务列表显示,但是不知道有没有其他印象public class ConfigClientApplication {public static void main(String[] args){SpringApplication.run(ConfigClientApplication.class,args);}}控制器方法
xxxxxxxxxxpublic class ConfigClientController {("${config.info}")private String configInfo;("/configInfo")public String getConfigInfo(){return configInfo;}}测试效果
【没有注解也能显示服务在服务列表】
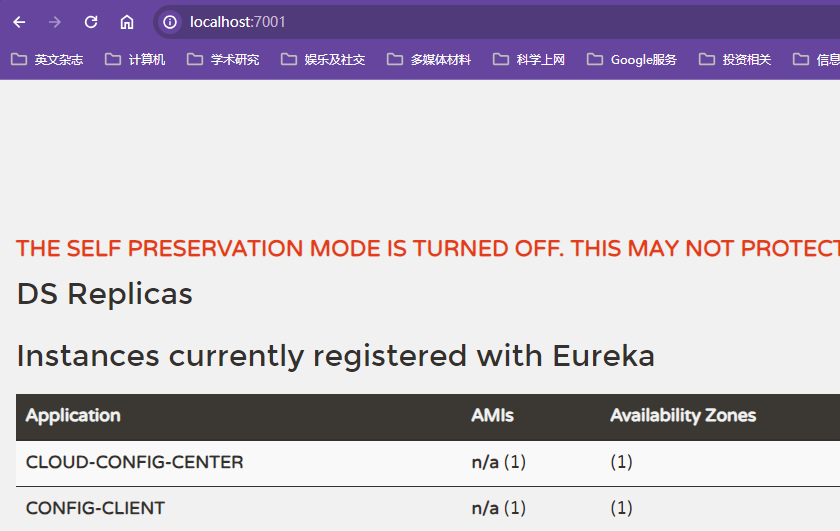
【测试配置文件配置成功】

【通过改客户端bootstrap.yml控制获取配置文件的分支】

致命问题
远程库的变化可以实时更新在配置中心,即通过配置中心自身访问配置文件可以实时显示配置变化,但是微服务更新配置文件必须重启,这对线上服务是致命的
疑问:更改配置文件只能在远程库改吗?在本地改能同步到远程库吗
【配置中心实时同步远程库】
从配置中心直接通过rest接口访问配置文件中文会乱码

【客户端必须重启才能同步远程库】
经过测试,不重启不能更新,客户端先拉取配置文件再响应给请求的中文不会乱码

微服务配置动态刷新
配置通过远程post请求手动刷新虽然解决了服务重启的问题,但是有多个微服务客户端时每个客户端都要执行一次post请求,当然可以写一个脚本,但是也可能存在项刷新特定几个服务的时候,很不方便
考虑能不能通过广播,一次通知,处处生效,以扩大自动刷新的范围,就引出了消息总线
动态刷新配置
引入actuator依赖
不知道具体的作用,但是发送post请求刷新配置客户端需要用到
xxxxxxxxxx<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>增加bootstrap配置项
说是暴露监控端口,实际啥也没说
xxxxxxxxxxserverport8008springapplicationnameconfig-clientcloud#Config客户端配置config#label: main #分支名称labelmaster #分支名称nameconfig #配置文件名称profiledev #读取后缀名称#上述3个综合:master分支上config-dev.yml的配置文件被读取http://cloudconfig9002.com:9002/master/config-dev.ymlurihttp//localhost9002 #配置中心地址k#服务注册到eureka地址eurekaclientservice-urldefaultZonehttp//localhost7001/eureka# 暴露监控端点,不知道是哪个包下的managementendpointswebexposureinclude"*"控制器方法上添加@RefreshScope注解开启刷新功能
不知道是不是必须加在控制器方法上,也不知道作用到底是啥,不清楚是不是每个控制器方法都加,反正水的一比
懒得看,以后看源码再追究:https://juejin.cn/post/7131193486849605646
xxxxxxxxxx//配置中心的依赖public class ConfigClientController {("${config.info}")private String configInfo;("/configInfo")public String getConfigInfo(){return configInfo;}}做完以上配置,还需要运维人员改完配置后发送post请求给配置更新对象,请求接口是:
http://主机地址:配置更新目标服务端口号/acuator/refresh此时微服务上的配置就和远程库手动同步了【避免了服务重启】
测试效果
【配置刷新请求】
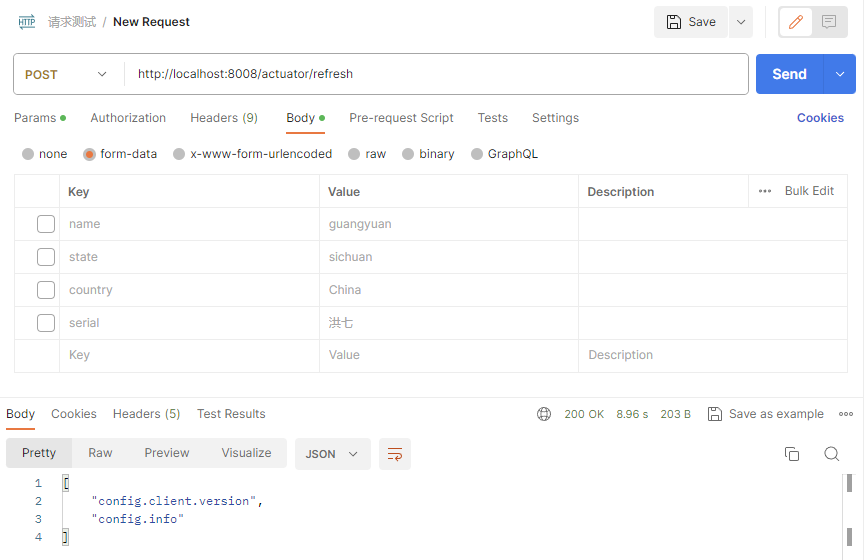
【动态刷新效果】 
消息总线
Spring Cloud Bus配合Spring Cloud Config一起使用可以实现真正的配置动态刷新,而且能自动实现差异化通知【全局广播和定点通知】
Bus作为消息总线支持两种消息代理RabbitMQ和Kafka,spring Cloud Alibaba用的是RocketMQ
概述
Bus+Config实现配置动态刷新
配置动态刷新架构图
第一步:将配置更新推送到远程库
第二步:配置中心服务器从远程库同步远程库更新
第三步:以前是运维发送post请求让服务更新,现在变成让消息队列推送请求,外部向其中一个服务发送一个请求Bus刷新的Post请求,服务发送消息到消息总线并从配置中心拉取配置,消息总线对所有指定服务发送刷新消息并从配置中心拉取配置
SpringCloud Bus就是将分布式系统的节点与轻量级消息系统连接起来的框架,整合了Java事件处理机制和消息中间件的主题订阅通知功能,SpringCloud目前支持的消息中间件为RabbitMQ和Kafka
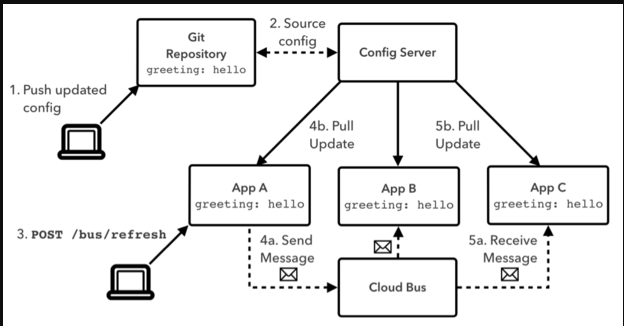
Bus的作用
管理和传播分布式系统间的消息,可以当做一个分布式执行器,也可以当做微服务间的通信通道,可用于广播状态更改、事件推送等
注意在下图中刷新请求可以直接推送给配置中心,配置中心直接对所有服务进行配置
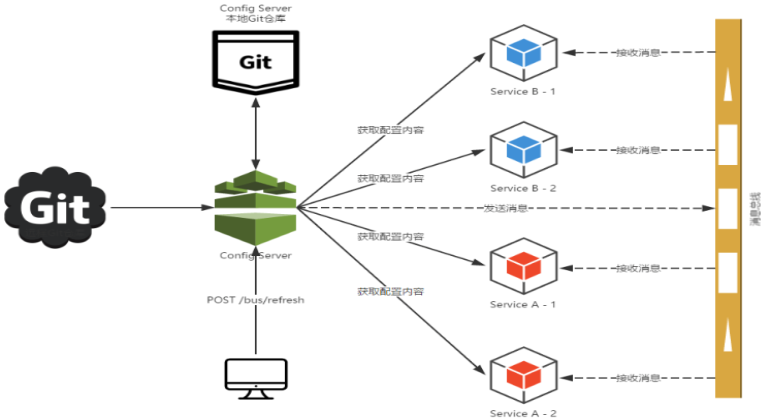
Bus总线
有点类似于整合消息总线,拉出一个主题交换机,将服务实例整合起来对应不同主题的消息队列,实现某个主题对应的消息被该主题下的所有服务实例监听和消费
总线定义
微服务架构的系统中,使用轻量级的消息代理来构建一个共用的消息主题,并让系统中所有微服务实例都连接上来。由于该主题中产生的消息会被所有实例监听和消费,所以称它为消息总线。在总线上的服务实例可以方便地监听一些需要连接在某个主题上的实例都需要知道的消息
实现原理
配置中心客户端实例都监听MQ中同一个主题交换机【默认是springCloudBus】。当一个服务刷新数据的时候,它会把这个信息放入到对应的Topic交换机中,其它监听同一Topic的服务就能得到通知并自动去更新自身的配置。
Bus整合RabbitMQ
RabbitMQ配置
配置windows的
配置Erlang运行环境:http://erlang.org/download/otp_win64_21.3.exe
安装RabbitMQ:Release RabbitMQ 3.7.14 · rabbitmq/rabbitmq-server · GitHub
启动RabbitMQ服务,可以直接在开始菜单点击启动来进行启动【报服务名无效直接点击重新安装即可,不要信网上什么删除注册表】
输入命令
rabbitmq-plugins enable rabbitmq_management添加RabbitMQ可视化插件,通过浏览器http://127.0.0.1:15672/进行访问添加用户的命令和linux系统是一样的【不添加用默认的也能访问】
Bus全局动态刷新
要求具备RabbitMQ的环境,需要配置RabbitMQ的信息,可以使用外部集群
创建18-config-client作为17的同级服务【为了方便,直接复制17模块的】,演示Bus的全局动态刷新效果
技术选型
利用消息总线触发配置中心服务端更加合适,触发一个客户端存在以下局限性
打破了微服务的职责单一性,因为微服务本身是业务模块,它本不应该承担配置刷新的职责。【万一宕机既影响服务也影响其他服务的配置更新】
破坏了微服务各节点的对等性。【增加配置的服务区分工作】
有一定的局限性。如微服务在迁移时,它的网络地址常常会发生变化,此时如果想要做到自动刷新,那就会增加更多的修改
技术1:测试利用消息总线触发一个客户端【配置了配置中心客户端的服务】,从而实现刷新所有的客户端配置
技术2:测试利用消息总线触发配置中心服务端,从而实现刷新所有客户端的配置
配置中心同步远程库,同时配置中心的Bus消息总线订阅RabbitMQ;
服务客户端也订阅RabbitMQ;
运维人员配置更新同步到远程库;
配置中心同步远程库,运维人员发送post请求到配置中心Bus总线暴露接口;
Bus总线发送消息到RabbitMQ,各个服务客户端监听到RabbitMQ的同步配置消息对应的服务客户端自动进行消息同步
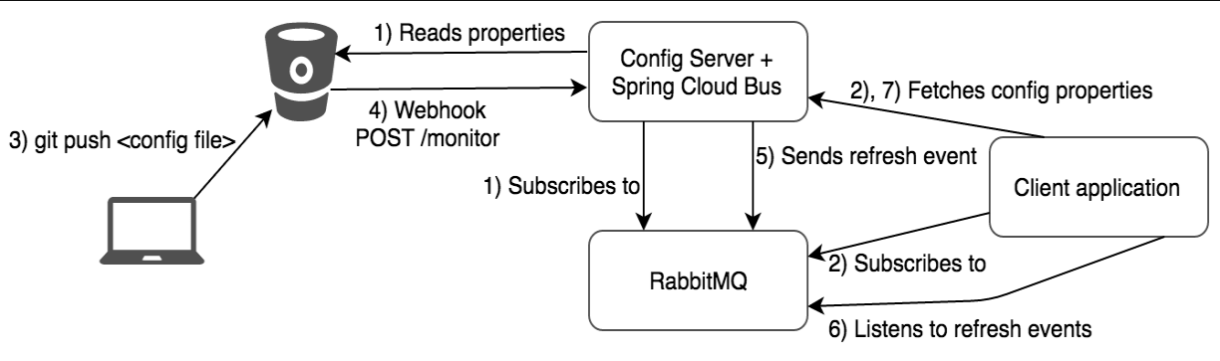
代码实现
访问Bus暴露接口,自动广播所有客户端服务对配置文件进行更新
在配置中心引入rabbitmq的依赖
凡是涉及暴露和监控的项目中都要有actuator依赖,没有需要补上
xxxxxxxxxx<!--添加消息总线RabbitMQ支持--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bus-amqp</artifactId></dependency>在配置中心添加对rabbitmq的配置并配置配置中心暴露给bus刷新的端点
xxxxxxxxxxspring#rabbitmq相关配置rabbitmqhostlocalhostport5672usernameguestpasswordguest##rabbitmq相关配置,暴露bus刷新配置的端点managementendpoints#暴露bus刷新配置的端点webexposureinclude'bus-refresh'每个客户端添加消息总线依赖
xxxxxxxxxx<!--添加消息总线RabbitMQ支持--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bus-amqp</artifactId></dependency>每个客户端添加对rabbitmq的支持【是spring打头的配置】
xxxxxxxxxxspring#rabbitmq相关配置 15672是Web管理界面的端口;5672是MQ访问的端口rabbitmqhostlocalhostport5672usernameguestpasswordguest
测试
启动eureka7001,配置中心9002,客户端8008,客户端8009
运维工程师修改Gitee【Gitee老是断网,不好用】上配置文件并增加版本号
【修改信息】
在master分支的config-dev.yml文件中增加了"version=v1.0.0"
【未发送请求状态】
只同步了配置中心服务器,没有同步客户端,老办法只能对每个服务单独发送Post请求挨个刷新
发送Post请求
"http://localhost:9002/actuator/bus-refresh"给配置中心注意:新版本是:curl -X POST "http://localhost:9002/actuator/busrefresh"
发送请求到位于配置中心服务器的Bus总线的暴露接口,又Bus总线的主题交换机springCloudBus发送消息给各个服务实例对配置文件进行同步

发送请求
http://config-9002.com:9002/config-dev.yml读取配置中心同步的配置文件发送请求
http://localhost:8008/configInfo和http://localhost:8009/configInfo读取客户端的配置文件信息测试结果
配置中心和客户端都同时进行了同步
3355、3366 一定要一个一个启动,不然报错rabbitmq消费者启动报队列未找到

RabbitMQ中交换机和队列的情况
【交换机和队列】
【队列详情】
Bus定点动态刷新
只想通知指定服务进行配置同步,其余的服务不进行同步
只通知8008进行配置同步,8009不进行配置同步
对配置中心发送post请求,请求地址全局刷新格式后面指定目标服务的目的地:destination=服务名:端口号
http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
存在问题
如何指定多个特定服务进行配置同步,难道还是一个一个发送请求吗?还是后面再添加/{destination}
如果服务名和端口号都相同【部署机器不同,即ip不同】,这种情况只更新一台机器还是两台机器都进行更新
测试效果
远程库更新master分支config-dev.yml的version=v1.0.1

发送请求
http://localhost:9002/actuator/bus-refresh/config-client:8008
服务配置更新效果
指定对8009端口更新,只会更新8008端口服务,不会更新8009端口服务
【8008端口更新情况】

【8009端口更新情况】

消息驱动
前端发送消息给后端处理以后,会产生一些数据可以提供给大数据平台进行广告推荐、商品定位;可能发生后端用的消息中间件用的RabbitMQ,大数据平台用的消息中间件为Kafka;一个系统存在两种消息中间件。两种消息中间件的架构不同,RabbitMQ有exchange,Kafka有Topic和Partitions;可能导致技术切换、系统维护和开发上的困难【业务需要时对消息队列进行迁移,此时一堆东西要推倒重做,这在开发上是不可接受的,因为消息中间件和系统耦合了,此时Stream提供了一种消息中间件解耦合的方式】,做精一个中间件已经不容易,同时都精通会加大开发维护成本
寻求一种新技术,不再关注消息队列的细节,使用一种适配绑定的方式,自动的实现在各种MQ内的切换,使用cloud stream屏蔽底层的细节差异,操作cloud stream就可以自动切换操作底层常用四种消息中间件
SpringCloud Stream的作用是"屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型"【看成JDBC就行了】
SpringCloud Stream简介
官网:https://spring.io/projects/spring-cloud-stream#overview
英文文档:https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/
中文指导手册:https://m.wang1314.com/doc/webapp/topic/20971999.html
Spring Cloud Stream是用于构建与共享消息传递系统连接的高度可伸缩的事件驱动微服务框架,应用程序通过inputs或者outputs【消息的发送和消费】来与Spring Cloud Stream中binder对象交互,Spring Cloud Stream的binder对象负责与消息中间件交互。程序员只需要搞清楚如何与Stream交互就能方便的使用消息驱动和消息中间件交互【玩的就是binder】
使用Spring Integration来连接消息代理中间件以实现消息事件驱动。Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引用了发布-订阅、消费组、分区的三个核心概念。
Spring Cloud Stream目前仅支持RabbitMQ和Kafka
标准MQ的结构
没有引入Stream的情况下,生产者/消费者之间靠消息通道MessageChannel传递信息内容,消息消费通过由MessageHandler消息处理器所订阅的消息通道MessageChannel的子接口SubscribableChannel负责收发处理
Stream统一消息底层中间件的策略
Stream架构图
绑定层作为中间层与消息队列进行通信,生产者和消费者通过绑定器生产或者消费消息
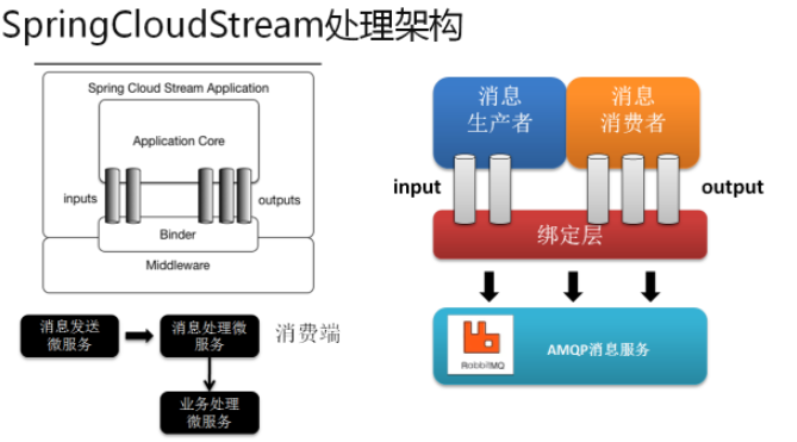
SpringBoot直接与消息中间件进行信息交互,对于不同的消息中间件的实现细节上有较大差异,比如不同消息中间件的消息发送和监听方式
Stream通过定义绑定器作为中间层,实现应用层与消息中间件细节之间的隔离,通过向应用程序暴露统一的Channel通道,让应用程序不再考虑消息中间件的差异,做到代码层对中间件无感知,甚至与可以动态切换消息中间件
Stream中的消息通信方式遵循发布-订阅模式,主要使用Topic主题对消息进行广播,Topic在RabbitMQ中是主题交换机,在Kafka中是Topic
Stream的标准流程
标准流程图
对应生产者的Stream有Source、Channel、Binder;对应消费者的Stream有Sink、Channel、Binder
Binder是屏蔽消息中间件的绑定器
Channel是MQ中对了的一种抽象,实现消息通讯系统中消息存储和转发的媒介,通过Channel可以对队列进行配置
Source可以简单的理解成消息的输入;Sink可以理解为消息的输出
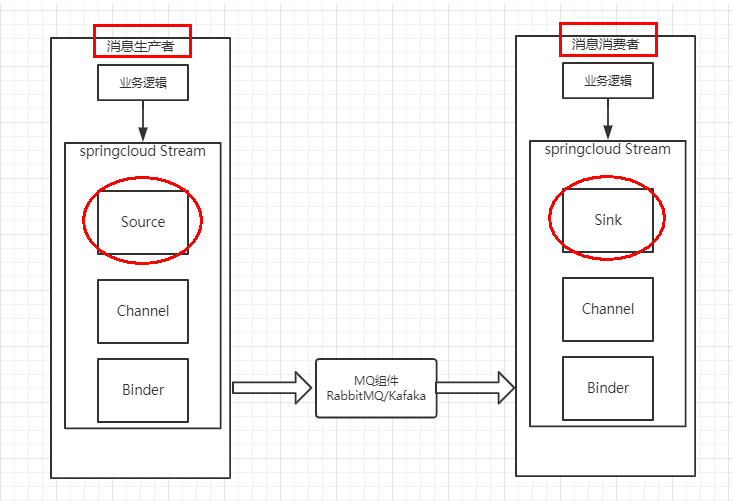
常用注解
output表示消息离开应用程序,所以对应生产者;响应的input,对应消费者
消息接收还是通过监听器相关注解@StreamListener实现
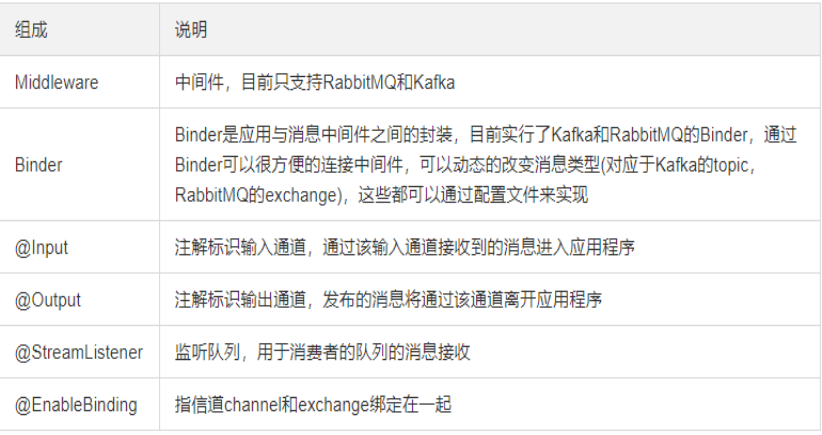
消息驱动系统搭建
前提是RabbitMQ环境搭建好了
新建模块8010【消息生产者】,8011【作为消费者】,8012【作为消费者】;在其中引入Stream消息驱动
生产者
pom.xml
多了stream-rabbit依赖,如果是kafka就换成kafka的
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--stream消息驱动整合RabbitMQ的依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-rabbit</artifactId></dependency><!--基础配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8010springapplicationnamecloud-stream-provider#stream的核心配置,其他都讲过,就这段配置是配置stream的cloudstreambinders# 在此处配置要绑定的rabbitmq的服务信息;defaultRabbit# 表示定义的名称,用于于binding整合typerabbit # 消息组件类型environment# 设置rabbitmq的相关的环境配置springrabbitmqhostlocalhostport5672usernameguestpasswordguestbindings# 服务的整合处理output# 这个名字是一个通道的名称destinationstudyExchange # 表示要使用的Exchange名称定义,没有就创建,没指定交换机类型啊,默认是主题交换机content-typeapplication/json # 设置消息类型,本次为json,文本则设置“text/plain”binderdefaultRabbit # 设置要绑定的消息服务的具体设置,是output下的属性,不用管报红,启动不会出问题,放在content-type下不会报红,但是无法启动#由于没有绑定队列,能看见消息发送频率上的Publish有消息发送记录,但是因为没有绑定队列消息自动丢弃eurekaclient# 客户端进行Eureka注册的配置service-urldefaultZonehttp//localhost7001/eurekainstancelease-renewal-interval-in-seconds2 # 设置心跳的时间间隔(默认是30秒)lease-expiration-duration-in-seconds5 # 如果现在超过了5秒的间隔(默认是90秒)instance-idprovider-8010.com # 在信息列表时显示主机名称prefer-ip-addresstrue # 访问的路径变为IP地址启动类
xxxxxxxxxxpublic class StreamProviderApplication {public static void main(String[] args){SpringApplication.run(StreamProviderApplication.class,args);}}消息发送接口和实现类
【接口】
xxxxxxxxxxpublic interface StreamMessageProvider {public String send() ;}【实现类】
新版本 @EnableBingding 注解已过时,过时的内容一般不允许在工作中使用,可以搜一下博客@EnableBingding 注解过时,新版本使用函数式接口
这个MessageChannel对象的实例名必须是 output,切记莫写成 outPut,不然会报错启动。。
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 注入了消息输出对象output,MessageChannel对象,在send方法中使用output发送消息,使用@EnableBinding(Source.class)注解* 【元注解有@Configuration】引入该消息发送对象,并在控制器方法进行调用* @创建日期 2023/11/13* @since 1.0.0*/(Source.class) // 将这个注解理解为是一个消息的发送管道的定义,实现的接口不用加任何注解,对应的方法必须是sendpublic class StreamMessageProviderImpl implements StreamMessageProvider {private MessageChannel output; // 消息的发送管道,显然这是项目启动自动配置的/*** @return {@link String }* @描述 send方法中封装了对output的调用来发送消息,这个方法的名字应该可以不固定为send* @author Earl* @version 1.0.0* @创建日期 2023/11/13* @since 1.0.0*/public String send() {String serial = UUID.randomUUID().toString();//这个MessageBuilder是org.springframework.integration.support包下的this.output.send(MessageBuilder.withPayload(serial).build()); // 创建并发送消息log.info("serial: "+serial);return serial;}}控制器方法调用
xxxxxxxxxx("/message")public class MessageController {StreamMessageProvider streamMessageProvider;("/send")public String sendMessage(){return streamMessageProvider.send();}}
测试
启动RabbitMQ
启动eureka7001服务注册中心
启动8010消息生产者
访问接口地址
http://localhost:8010/message/send观察消息队列的消息情况由于没有绑定队列,能看见消息发送频率上的Publish有消息发送记录,但是因为没有绑定队列消息自动丢弃,上方的队列消息显示为0
消费者
同一套写法创建两套消费者20模块和21模块
pom.xml
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><!--消费者也要引入stream整合RabbitMQ的依赖--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-rabbit</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--基础配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8011springapplicationnamecloud-stream-consumer#stream的核心配置,其他都讲过,就这段配置是配置stream的cloudstreambinders# 在此处配置要绑定的rabbitmq的服务信息;defaultRabbit# 表示定义的名称,用于于binding整合typerabbit # 消息组件类型environment# 设置rabbitmq的相关的环境配置springrabbitmqhostlocalhostport5672usernameguestpasswordguestbindings# 服务的整合处理output# 这个名字是一个通道的名称destinationstudyExchange # 表示要使用的Exchange名称定义,没有就创建,没指定交换机类型啊,默认是主题交换机content-typeapplication/json # 设置消息类型,本次为json,文本则设置“text/plain”binderdefaultRabbit # 设置要绑定的消息服务的具体设置,是output下的属性,不用管报红,启动不会出问题,放在content-type下不会报红,但是无法启动#没有绑定队列,能看见消息发送频率上的Publish有消息发送记录,但是因为没有绑定队列消息自动丢弃eurekaclient# 客户端进行Eureka注册的配置service-urldefaultZonehttp//localhost7001/eurekainstancelease-renewal-interval-in-seconds2 # 设置心跳的时间间隔(默认是30秒)lease-expiration-duration-in-seconds5 # 如果现在超过了5秒的间隔(默认是90秒)instance-idconsumer-8011.com # 在信息列表时显示主机名称prefer-ip-addresstrue # 访问的路径变为IP地址启动类
xxxxxxxxxxpublic class StreamConsumerApplication {public static void main(String[] args){SpringApplication.run(StreamConsumerApplication.class,args);}}消息监听消费业务类
xxxxxxxxxx(Sink.class)//public class ReceiveMessageListener {("${server.port}")private String serverPort;(Sink.INPUT)public void input(Message<String> message) {log.info("1号消费者接收到的消息:" + message.getPayload()+"\t port: "+serverPort);}}
测试
单个消费者对应单个生产者
启动eureka7001、消息生产者8010、消息消费者8011
请求消息发送接口
http://localhost:8010/message/send,观察消费者能否接收到消息【消息发送者】
当消息生产者指定的交换机有消费对象时会自动生成队列,不需要在应用程序指定队列
【测试结果】
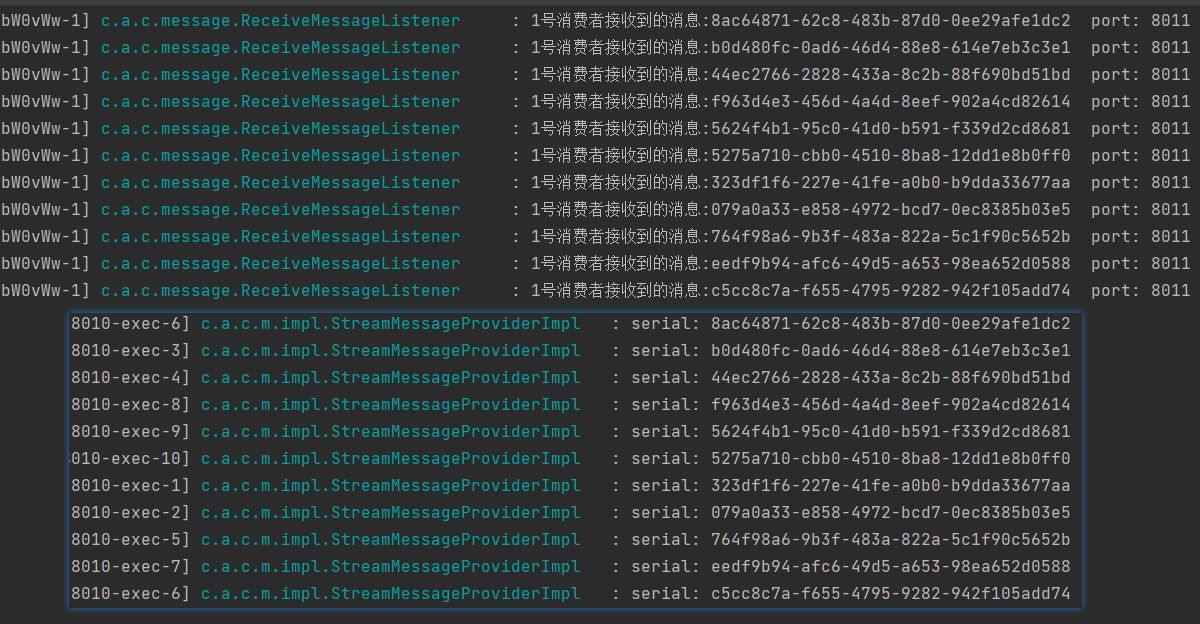
分组消费与持久化
两个消费者模块8011和8012,以eureka7001作为服务注册、8010作为消息发送者,8011和8012同时作为8010的消费者

存在问题
生产者发送一个消息被两个消费者同时消费,存在重复消费问题
比如订单集群重复消费可能导致重复扣款的问题,
但是又要有同时分发消息的场景,比如物流系统和库存系统
使用分组和持久化属性group来解决这个问题
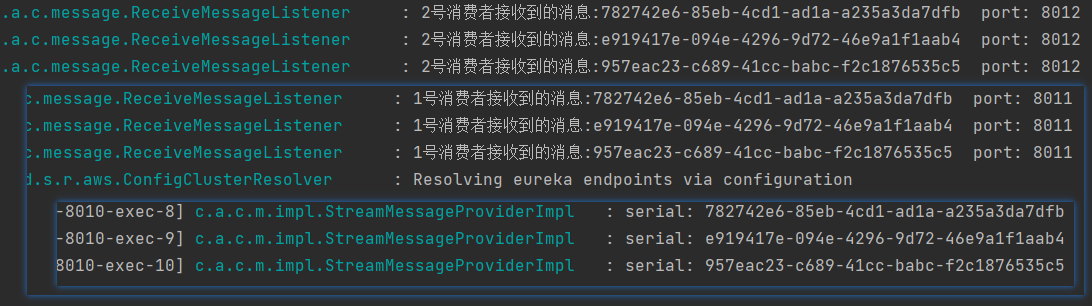
消息存在持久化问题
消费者分组
Stream中同一个组中的多个消费者是竞争关系,消息只会被同组的一个消费者消费一次,不同的组可以重复消费一个消息【理解成一个组就像一个支付服务集群,不同的组是不同的服务如物流服务】
anonymous.3x3vWyDPRaaJr7aYbW0vWw和anonymous.FExgq1TIQ9e6SJa2UGrSDg是分组的组名,两个消费者处于不同分组的队列中,因此消息被重复消费了xxxxxxxxxxstudyExchange.anonymous.3x3vWyDPRaaJr7aYbW0vWw 8011消费者对应的队列studyExchange.anonymous.FExgq1TIQ9e6SJa2UGrSDg 8012消费者对应的队列自定义配置将消费者分成同一个组,解决重复消费问题
同一个组内的微服务竞争同一条消息,同一个主题交换机下不同的组会重复消费同一条消息
消费者分成不同的组
在配置文件的input下添加group属性,将不同的微服务设置成不同的自定义分组
不同组消息可重复消费
【消费者1自定义分组】
xxxxxxxxxxspringcloudstreambindings# 服务的整合处理input# 这个名字是一个通道的名称#自定义消费者分组grouporderService【消费者2自定义分组】
xxxxxxxxxxspringcloudstreambindings# 服务的整合处理input# 这个名字是一个通道的名称grouptransferService【队列情况】
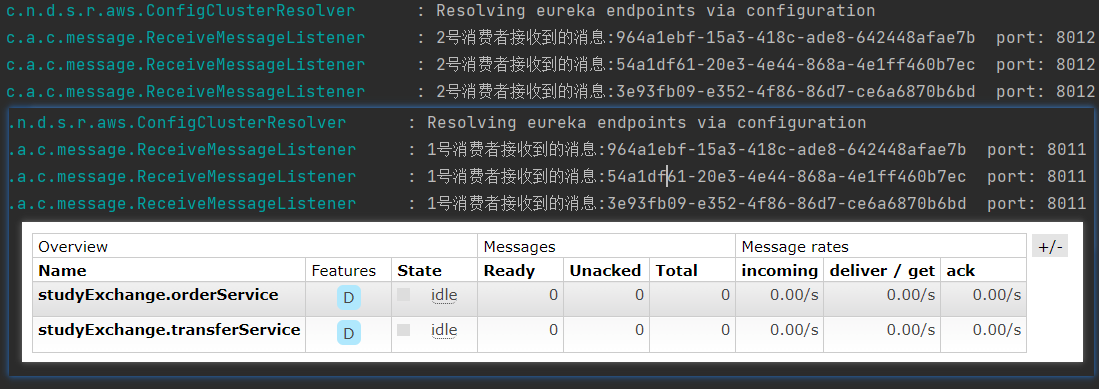
消费者分为相同组
相同组的消费者竞争同一条消息
【消费者1自定义分组】
xxxxxxxxxxspringcloudstreambindings# 服务的整合处理input# 这个名字是一个通道的名称#自定义消费者分组grouporderService【消费者2自定义分组】
xxxxxxxxxxspringcloudstreambindings# 服务的整合处理input# 这个名字是一个通道的名称grouporderService【队列情况】
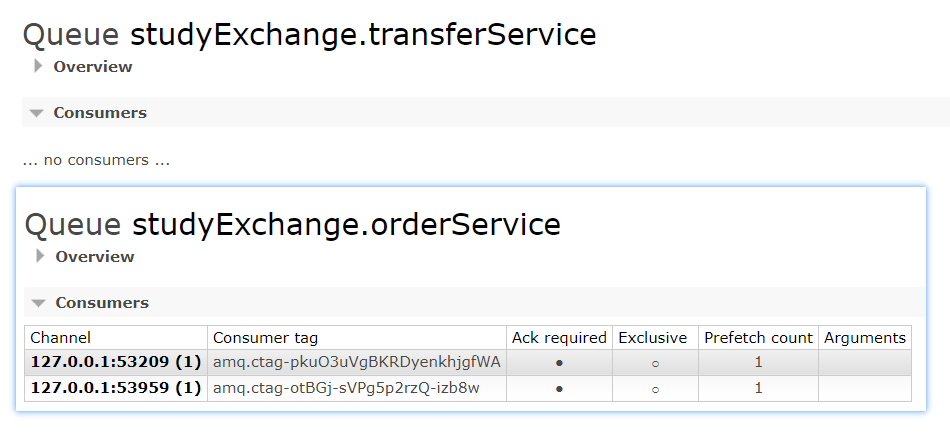
【测试消费情况】
消息持久化
注释掉8011的分组配置,8012分组维持原样
服务不分组,mq会给分配随机组(队列),每次重启都不同,所以你重启后就无法获取之前队列的消息,错过了就错过【重点是即便之前有分组,重启后分组变化了,宕机期间的数据会直接丢失,这里8011就演示这种情况,
8012演示分组为宕机前分组,宕机期间消息会自动被持久化
【?这是保存在队列中吧,能叫持久化吗,只要RabbitMQ不宕机就能等待消费,不过Stream创建的队列都是持久化队列,只要消息发送也设置了持久化,确实消息会持久化】,重启后继续监听原队列的数据,消息不会丢失】
关闭8011、8012模拟服务器宕机
8010生产者发消息模拟消费者宕机期间发送消息【注意这里消费者启动过,创建过队列,要是没有过消费者,生产者发送的消息会直接丢失】
分别开启两个消费者观察消息消费情况【注意宕机前两个消费者在同一个分组】
8011分组变了,宕机期间生产者发送的消息全部丢失;8012分组没变,维持原队列,宕机期间生产者发送消息全部接收并消费
如果宕机没有改变分组,两个消费者都应该能收到宕机期间的消息
两个消费者宕机期间的消息,设置了同一个分组是采用轮询的规则,设置不同的分组是同时都能收到【已经测试确认了】
链路追踪
微服务框架,一个客户端请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个前端请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败
对于大型系统多个链路调用需要链路追踪技术来实现服务跟踪和发现问题,负责Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,并且兼容支持了zipkin【Sleuth管服务监控,zipkin对监控状态进行Dashboard图形化展现】
zipkin
zipkin下载网址:Central Repository: io/zipkin/java/zipkin-server/2.12.9 (maven.org)能下载zipkin的jar包,这里跟随课堂使用2.12.9,下载zipkin-server-2.12.9-exec.jar,在当前目录使用
java -jar运行
zipkin控制台
访问本机9411端口访问zipkin
http://localhost:9411/zipkin/服务调用sleuth+zipkin服务监控链路流程
Trace:类似于树结构的Span类型节点的集合,表示一条调用链路,该调用链路树形结构的唯一标识
span:表示调用链路来源,通俗的理解span就是一次请求信息
一条请求链路通过Trace id作为唯一标识,Span标识请求信息,parenId是上一级的spanId;请求也会有一个单独的spanId,把请求响应作为和服务等价的部分,即简略图展示的效果,每个部分都单独分配一个spanId
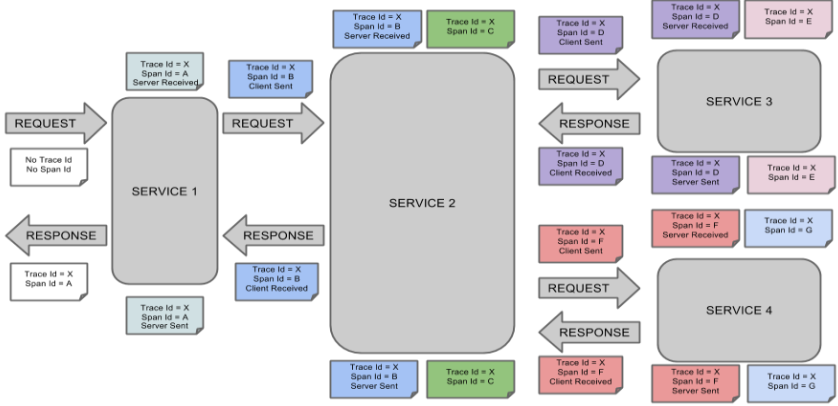
【简化图】
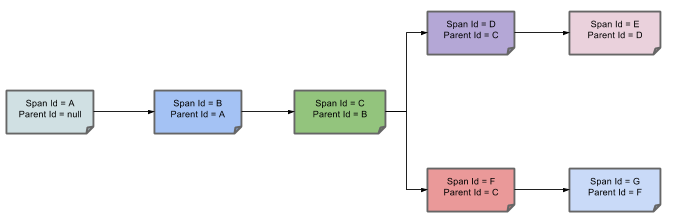
【链路依赖】
这个还是只考虑服务不考虑响应和请求
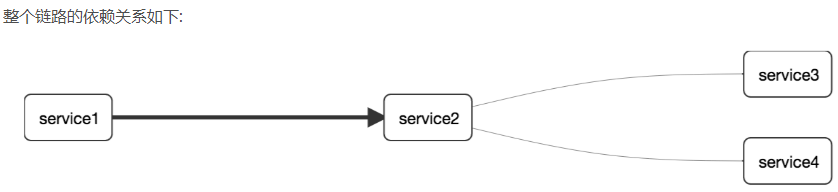
Slueth
可以认为SpringCloud收编了zipkin,在starter-ziipkin包下同时包含了Slueth和zipkin
在服务中引入服务调用链路监控
在payment8001中实现链路监控,通过02-order服务调用支付服务中的方法,服务调用者和被调用者都要添加starter-zipkin依赖
在01模块和02模块中引入slueth和zipkin依赖
xxxxxxxxxx<!--包含了sleuth+zipkin--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId></dependency>在01模块和02模块中配置zipkin
xxxxxxxxxxspring#zipkin相关配置zipkin#监控的数据要打到9411端口上供图形化显示base-urlhttp//localhost9411#Sleuth配置sleuthsampler#采样率值介于 0 到 1 之间,1 则表示全部采集,一般用0.5一半采样就够了probability1在02模块配置控制器方法
xxxxxxxxxx/*** @return {@link String }* @描述 zipkin+sleuth监控下的订单服务,其中调用payment中的控制器方法paymentZipkin* @author Earl* @version 1.0.0* @创建日期 2023/11/13* @since 1.0.0*/("/consumer/payment/zipkin")public String paymentZipkin() {String result = restTemplate.getForObject("http://localhost:8001"+"/payment/zipkin/", String.class);return result;}在01模块配置被调用控制器方法
xxxxxxxxxx/*** @return {@link String }* @描述 sleuth监控下的payment服务调用* @author Earl* @version 1.0.0* @创建日期 2023/11/13* @since 1.0.0*/("/payment/zipkin")public String paymentZipkin() {return "hi ,i'm payment zipkin server fall back O(∩_∩)O哈哈~";}
测试
启动eureka7001,order80和支付服务8001,启动zipkin
使用
http://localhost:9411/zipkin开始zipkin控制台发送一次请求调用,使用zipkin查看服务调用链路情况
【调用情况】
失败的那次是使用ribbon方式进行负载均衡时,只能使用在注册中心注册了的应用名,不能使用ip+portd的形式进行访问,否则会抛异常,报错500

【服务依赖关系】
为啥span显示只有2个,按照服务调用链路简化图不应该是3个吗?
Spring Cloud Alibaba简介
Spring Cloud Alibaba官网:https://spring.io/projects/spring-cloud-alibaba#overview
文档:
中文https://github.com/alibaba/spring-cloud-alibaba/blob/master/README-zh.md
英文https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
SpringCloud Alibaba于2018.10.31正式入驻SpringCloud 官方孵化器,在maven中央仓库发布第一个版本,目前用起来比SpringCloud爽
Spring Cloud Alibaba体系:根本原因还是整个netflix项目进入停更进维模式
spring.io/blog是spring的官方博客,2018/12/12的博客宣布Netflix Projects进入维护模式,进入维护模式意为着SpringCloud团队不会向该netflix模块中添加新功能,只修复block级别的bug和安全问题,考虑审查社区的小型拉取合并请求;博文https://spring.io/blog/2018/12/12/spring-cloud-greenwich-rc1-available-now
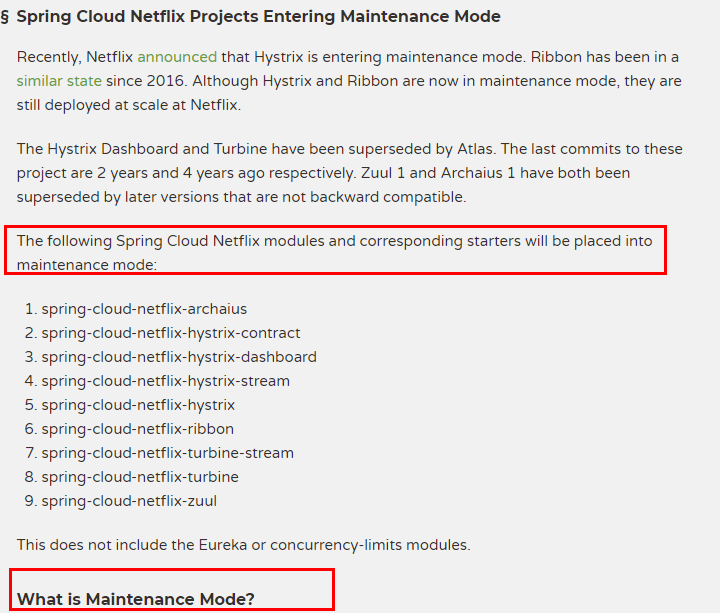
【官方推荐的相关功能替代】

Spring Cloud Alibaba的应用场景
服务限流降级:
默认支持 Servlet、Feign、RestTemplate、Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
服务注册与发现:
适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
分布式配置管理:
支持分布式系统中的外部化配置,配置更改时自动刷新。
消息驱动能力:
基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
阿里云对象存储:
阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
分布式任务调度:
提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
引入SpringCloud Alibaba的依赖
这个依赖的gav坐标阳哥也是从官方文档宕下来的
xxxxxxxxxx<!--spring cloud alibaba 2.1.0.RELEASE--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2.1.0.RELEASE</version><type>pom</type><scope>import</scope></dependency>SpringCloud Alibaba中的组件
Sentinel
Nacos
RocketMQ
Dubbo
Seata
Alibaba Cloud OSS
Alibaba Cloud SchedulerX
Alibaba Cloud SMS

Nacos注册与配置中心
包含了服务注册、配置中心【配置中心就整合了消息总线】的功能
nacos简介
前四个字母分别为Naming和Configuration的前两个字母,最后的s为Service。是一个易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Git:https://github.com/alibaba/Nacos
下载:https://nacos.io/zh-cn/index.html,https://github.com/alibaba/nacos/tags
直接用网站平台的形式替代Eureka的服务注册中心微服务和客户端的搭建配置
Nacos是AP模型,支持控制台管理,社区活跃度很高,在阿里内部有超过10w的实例在运行,经过双十一等各种大型流量考验
nacos的使用者

nacos的安装使用
使用命令
startup.cmd在当前窗口启动Nacos,默认以单击模式【stand alone mode】启动,使用http://localhost:8848/nacos对控制台进行访问
服务注册中心
微服务搭建
SpringCloud alibaba的依赖已经在父pom中引入了,创建22模块使用8013端口,使用nacos作为注册中心
pom.xml
引入spring-cloud-starter-alibaba-nacos-discovery,父工程已经引入springcloud alibaba;
nacos中自带ribbon负载均衡
xxxxxxxxxx<dependencies><!--SpringCloud ailibaba nacos ,也可以从官方文档查看引入方式--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--日常通用jar包配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8013springapplicationnamenacos-provider-paymentcloudnacosdiscoveryserver-addrlocalhost8848 #配置Nacos地址managementendpointswebexposureinclude'*'#暴露要监控的所有端点,actuator中的,雷神springboot最后有讲【端点详解】
actuator默认只支持端点 /health、/info
在application.properties中配置端点
可以组合使用,比如暴露所有端点,再不暴露指定端点
暴露部分端点
management.endpoints.web.exposure.include=info,health,beans,env
暴露所有端点
management.endpoints.web.exposure.include=*
不暴露beans端点
management.endpoints.web.exposure.exclude=beans
端点说明
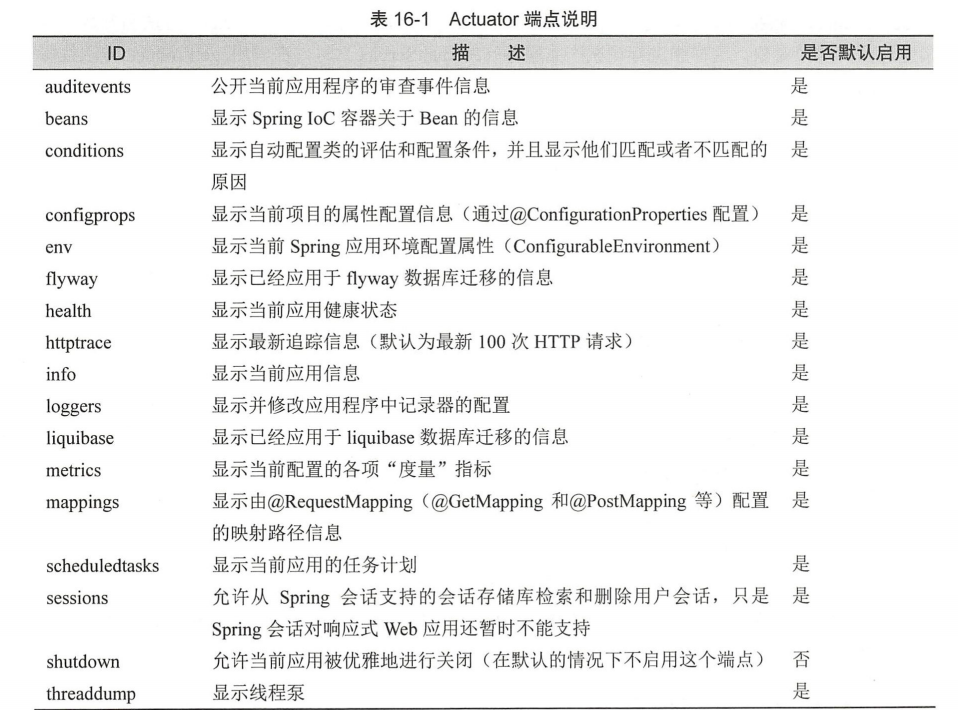
启动类
xxxxxxxxxx//启动类使用@EnableDiscoveryClient启动服务发现客户端功能public class PaymentApplication {public static void main(String[] args) {SpringApplication.run(PaymentApplication.class, args);}}控制器方法
xxxxxxxxxxpublic class PaymentController {("${server.port}")private String serverPort;(value = "/payment/nacos/{id}")public String getPayment(("id") Integer id) {return "nacos registry, serverPort: "+ serverPort+"\t id"+id;}}测试
只需要启动服务,不需要再创建注册中心微服务即可实现服务注册,也不需要设置心跳等信息
oss是因为后台启动了对象存储图床上传服务

服务注册中心对比
Nacos同时支持AP和CP模式的切换
coreDNS也是一个服务注册中心

C是所有节点在同一时间看到的数据是一致的【保证各个服务网络分区数据一致】;
而A的定义是所有的请求都会收到响应【允许部分数据在服务或者网络分区中不一致,优先对请求进行响应,就是为了高可用】
模式选择
AP模式:如果不需要存储服务级别的信息且服务实例是通过nacos-client注册,并能够保持心跳上报,那么就可以选择AP模式。
当前主流的服务如 Spring cloud 和 Dubbo 服务,都适用于AP模式,AP模式为了服务的可能性而减弱了一致性,因此AP模式下只支持注册临时实例。
CP模式:如果需要在服务级别编辑或者存储配置信息,那么 CP 是必须,
K8S服务和DNS服务则适用于CP模式。CP模式下则支持注册持久化实例,此时则是以 Raft 协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不存在,则会返回错误。
使用命令
curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP'可以进行模式的切换
Nacos支持两种模式切换的原因
Nacos想兼容全部的生态【如dubbo+Zookeeper可以轻松换成dubbo+nacos】,有些是A端设计理念,有些是C端设计理念,nacos的设计可以让其在适配工具时轻易切换
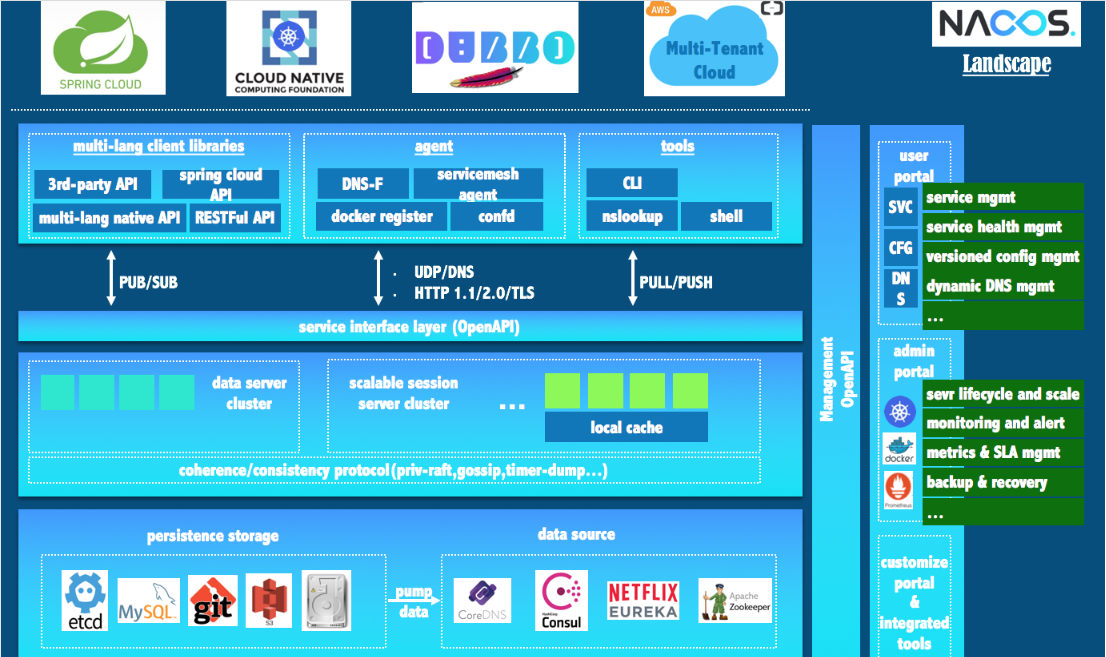
nacos服务发现实例模型
nacos遇到临时实例【如Zookeeper的临时节点】,就应该选择AP模式【wtf?上面又说Zookeeper是CP模式】
如果遇到持久化实例【如Consul关闭保护模式,服务宕机仍然会保存服务节点信息】,就应该选择CP模式
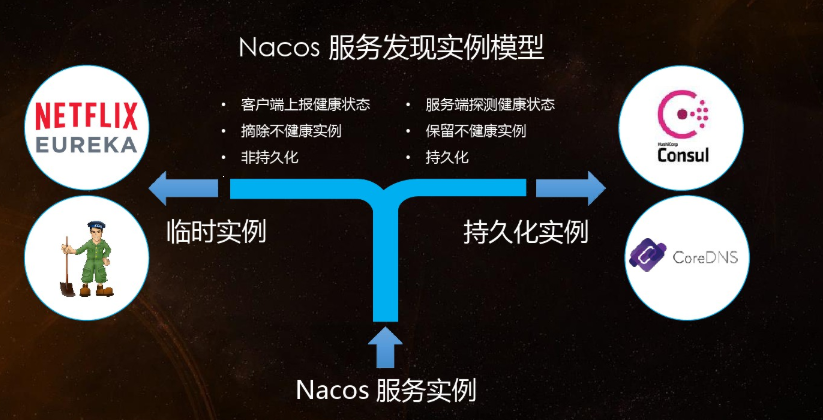
负载均衡
创建23模块和22模块组成集群,展示nacos的负载均衡功能
可以取巧的直接拷贝虚拟端口映射,为了和课程同步,还是创建出来23模块
支付模块虚拟端口映射
以22模块服务为模板,拷贝一份,以9011端口对服务进行启动
虚拟端口映射的服务端口是灰色的
虚拟端口映射
nacos服务列表
一个集群,两个实例
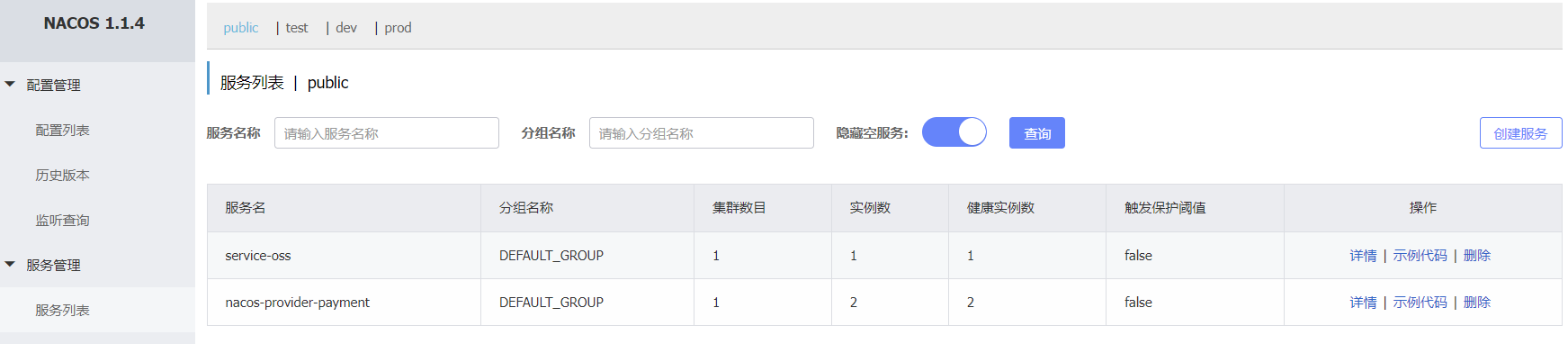
【访问效果】
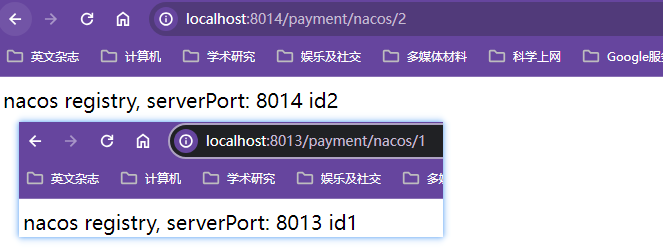
创建订单服务24模块
pom.xml
xxxxxxxxxx<dependencies><!--SpringCloud ailibaba nacos --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--日常通用jar包配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport80springapplicationnamenacos-consumer-ordercloudnacosdiscoveryserver-addrlocalhost8848#消费者将要去访问的微服务名称(注册成功进nacos的微服务提供者)service-urlnacos-user-servicehttp//nacos-provider-payment启动类
xxxxxxxxxxpublic class OrderApplication {public static void main(String[] args){SpringApplication.run(OrderApplication.class,args);}}控制器
xxxxxxxxxxpublic class OrderController {private RestTemplate restTemplate;("${service-url.nacos-user-service}")private String serverURL;("/consumer/payment/nacos/{id}")public String paymentInfo(("id") Long id){return restTemplate.getForObject(serverURL+"/payment/nacos/"+id,String.class);}}配置Ribbon负载均衡
xxxxxxxxxxpublic class ApplicationContextBean {public RestTemplate getRestTemplate(){return new RestTemplate();}}测试
通过order服务使用ribbon负载均衡调用支付服务
经过测试,nacos就是默认使用的ribbon轮询负载均衡策略
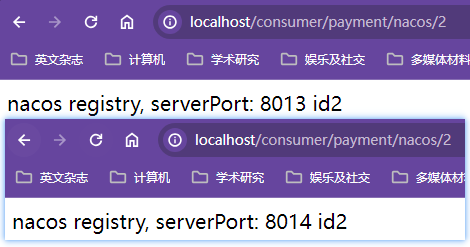
配置中心
基础配置
创建模块25,作为nacos配置中心的客户端
项目构建
pom.xml
xxxxxxxxxx<dependencies><!--nacos-config,nacos配置中心--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--nacos-discovery,nacos注册中心和服务发现--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--web + actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--一般基础配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>bootstrap.yml
xxxxxxxxxx# nacos配置,Nacos同springcloud-config一样,在项目初始化时,要保证先从配置中心进行配置拉取,拉取配置之后,才能保证项目的正常启动。serverport7003springapplicationnamenacos-config-clientcloudnacosdiscoveryserver-addrlocalhost8848 #Nacos服务注册中心地址configserver-addrlocalhost8848 #Nacos作为配置中心地址#file-extension: yaml #指定yaml格式的配置file-extensionyml #测试配置文件名为yml且此处写yml文件是否可以被访问【经过测试,没有问题,即便是nacos1.2版本以前】# ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension}application.yml
xxxxxxxxxxspringprofilesactivedev # 表示开发环境启动类
xxxxxxxxxxpublic class NacosConfigClientApplication {public static void main(String[] args) {SpringApplication.run(NacosConfigClientApplication.class, args);}}控制器
通过 Spring Cloud 原生注解
@RefreshScope实现配置自动更新xxxxxxxxxx//在控制器类加入@RefreshScope注解使当前类下的配置支持Nacos的动态刷新功能。public class ConfigClientController {("${config.info}")private String configInfo;("/config/info")public String getConfigInfo() {return configInfo;}}
dataId
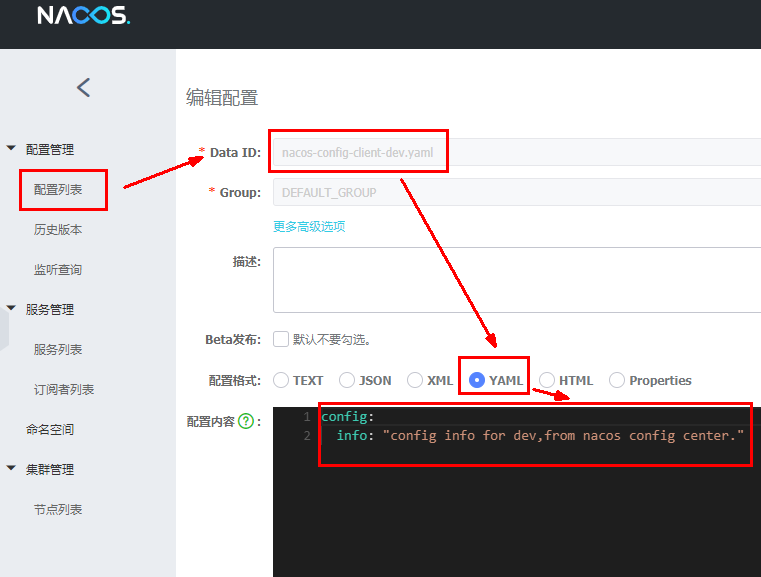
在
bootstrap.properties中配置 Nacos server 的地址和应用名之所以需要配置
spring.application.name,是因为它是构成 Nacos 配置管理dataId字段的一部分。xxxxxxxxxxspring.cloud.nacos.config.server-addr=127.0.0.1:8848spring.application.name=${prefix}dataId的完整格式如下xxxxxxxxxx${prefix}-${spring.profiles.active}.${file-extension}prefix默认为spring.application.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profiles.active即为当前环境对应的 profile【prod、dev、test】,详情可以参考 Spring Boot文档。注意:当
spring.profiles.active为空时,对应的连接符-也将不存在,dataId 的拼接格式变成${prefix}.${file-extension}【不要让spring.profiles.active为空,可能会出现莫名其妙的问题】可以通过application.yml或者bootstrap.yml中的
spring.profiles.active属性为dev或者test灵活切换读取nacos中不同dataID对应的配置文件file-exetension为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension来配置。目前只支持properties和yaml类型【这里也可以写yml,nacos配置中心文件名后缀为yml这里就必须写yml】。nacos上的配置文件后缀为yml,bootstrap中的配置
spring.profiles.active=dev也可以在nacos上读取到相应配置文件;nacos1.2以后nacos配置文件后缀为yml,配置文件为yaml启动也能读取的到,应该是已经修复了【但是这种方式nacos1.1.4会报错】
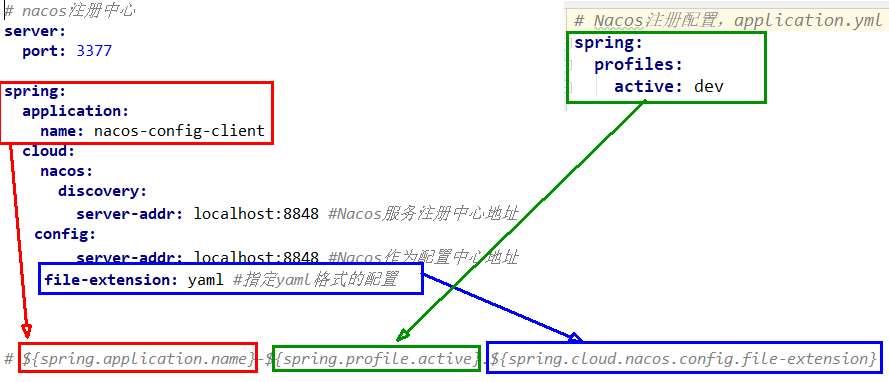
在nacos中新增配置文件
创建配置文件
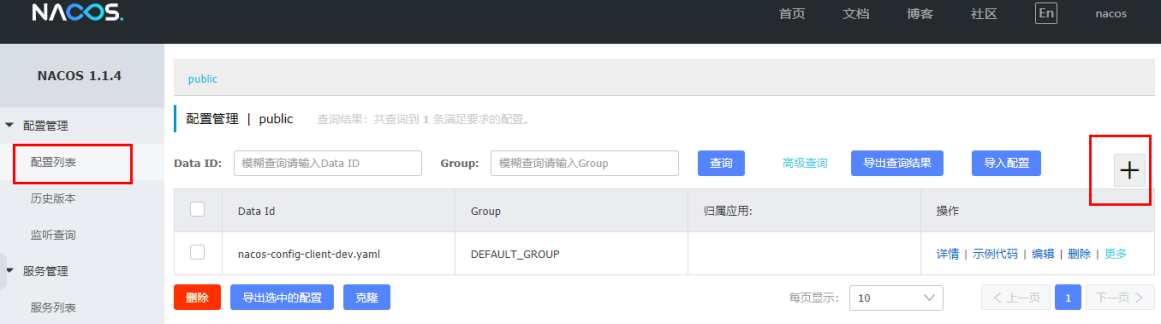
配置内容
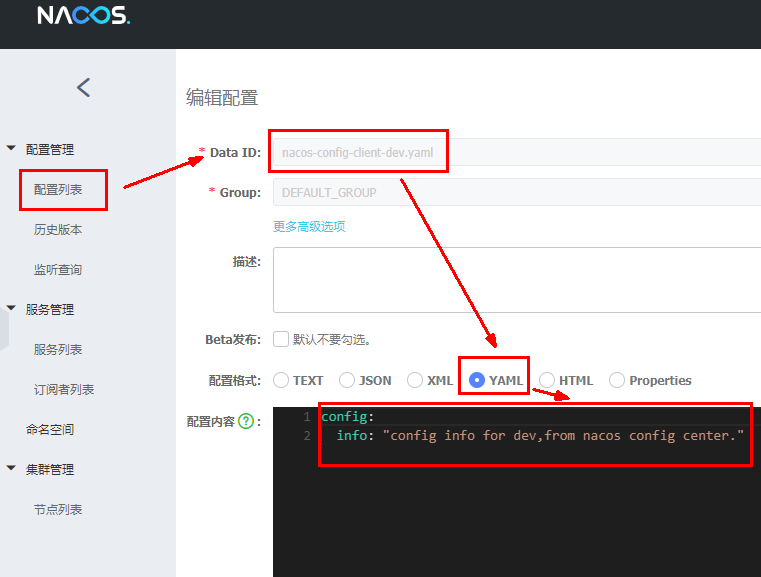
测试
开启25模块,发送请求获取nacos中配置文件中的内容
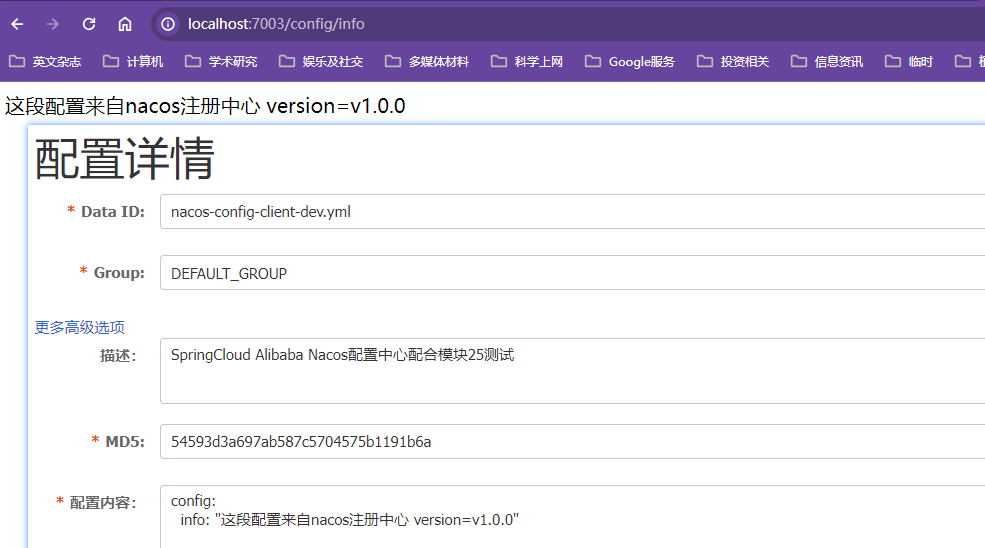
修改nacos中的配置文件,再次请求25模块,观察配置文件的自动同步效果
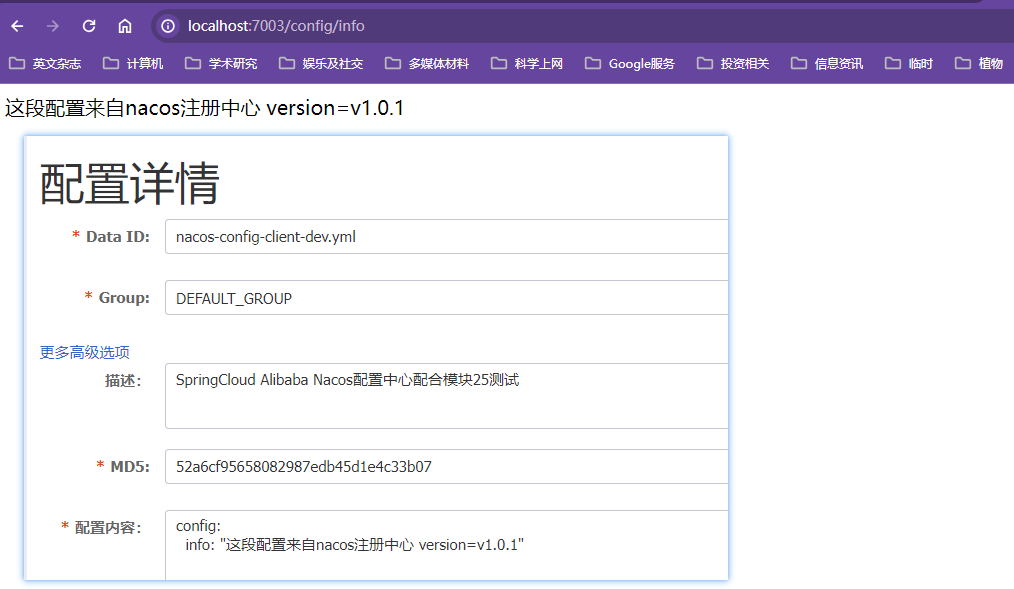
配置的版本及一键回滚
Nacos通过提供配置版本管理及其一键回滚能力,帮助用户改错配置的时候能够快速恢复,降低微服务系统在配置管理上的一定会遇到的可用性风险。
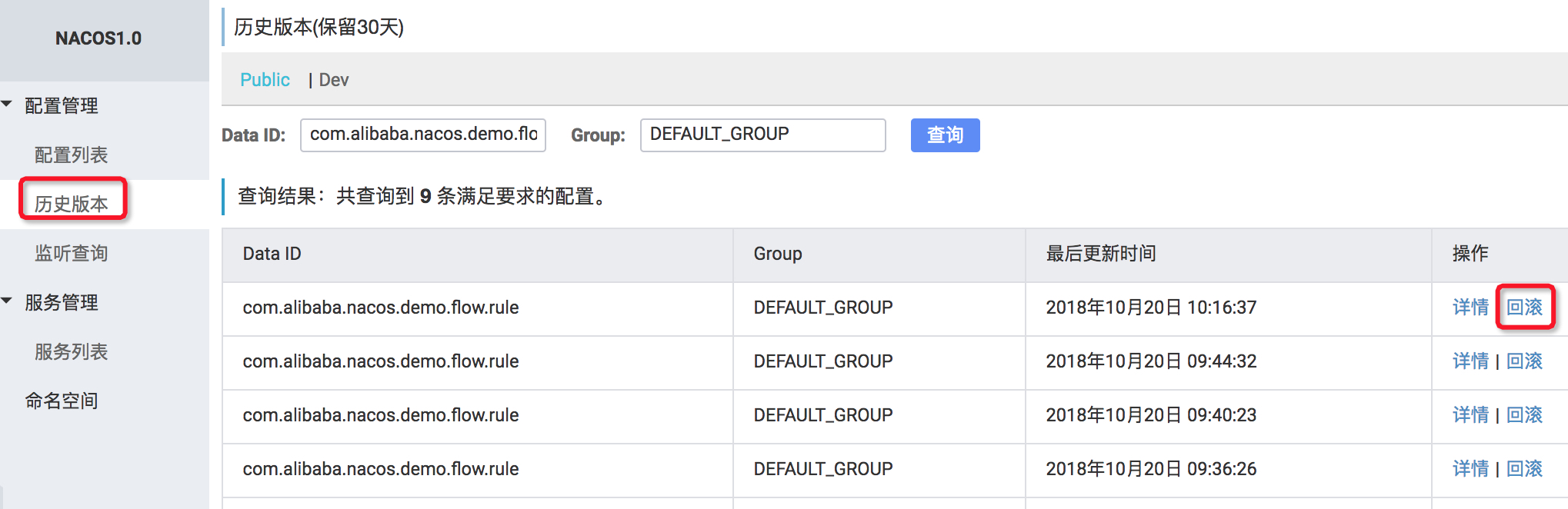
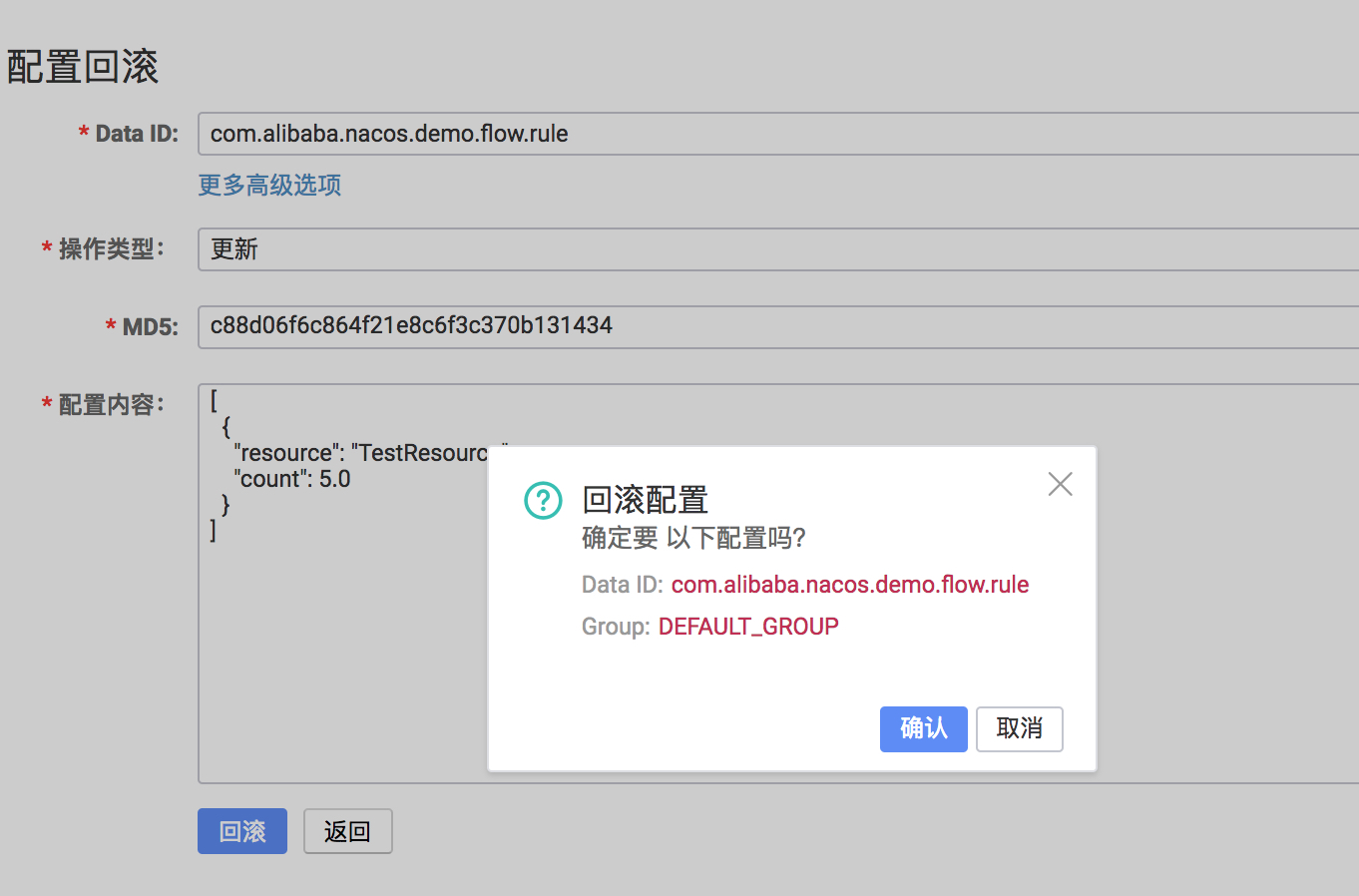
分类配置
多环境多项目管理
项目系统会运行在不同的环境,如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件
每个分布式微服务系统都有很多微服务子项目,每个微服务都有对应的prod、test、预发环境、prod环境,如何对这些微服务配置进行管理呢
命名空间分组
默认命名空间

Namespace、Group、Service三者关系
类似Java里面的package名和类名,
最外层的namespace是可以用于区分部署环境的,默认情况下是public,根据三个环境创建三个命名空间,达到不同环境之间的隔离
Group默认是DEFAULT_GROUP,可以把不同的微服务划分到同一个分组里面去
Service就是服务;一个Service可以包含多个Cluster(集群)【为了容灾,将service分别部署在了杭州机房和广州机房,这时就可以给杭州机房的Service起一个集群名称(HZ),给广州机房的Service微服务起一个集群名称(GZ),还可以尽量让同一个机房的微服务互相调用以提升性能。】
Nacos默认Cluster是DEFAULT,Cluster是对指定服务的一个虚拟划分。Instance是微服务的实例
三者关系
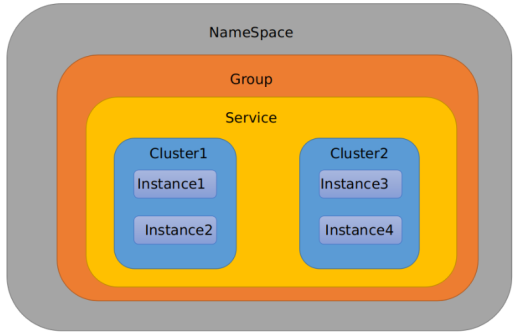
分类配置方案
这些方案中如果是一个服务集群,那么都读取的是同一个配置文件吗?
最终dataId+group+namespace来唯一确定来拉取配置, dataId,group,namespace都可以动态切环境,类似于包名+类名的思想确定唯一的配置文件【相当于三级目录区分不同环境和多项目】
DataID方案
在nacos中新建dataID的
spring.profiles.active为test的文件nacos-config-client-test.ymlspring.profiles.active不一定只能是三种环境,而是随意的,只是要和文件名进行匹配修改客户端配置文件application.yml的
spring.profiles.active=test浏览器访问服务读取的nacos上配置文件的内容
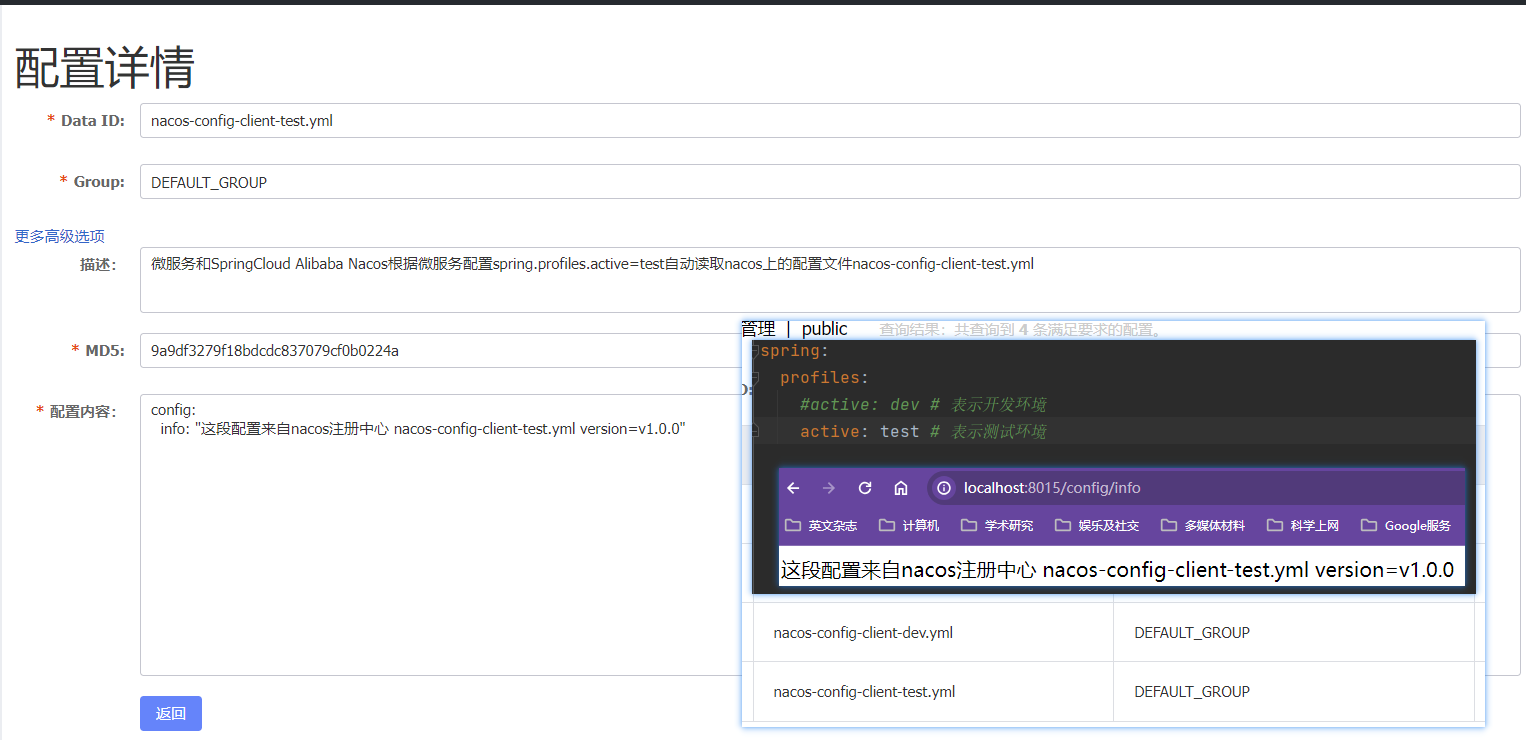
Group方案
在nacos中创建分组不同的配置文件,创建DEV_GROUP和TEST_GROUP分组下的两个同名文件
nacos-config-client-info.yml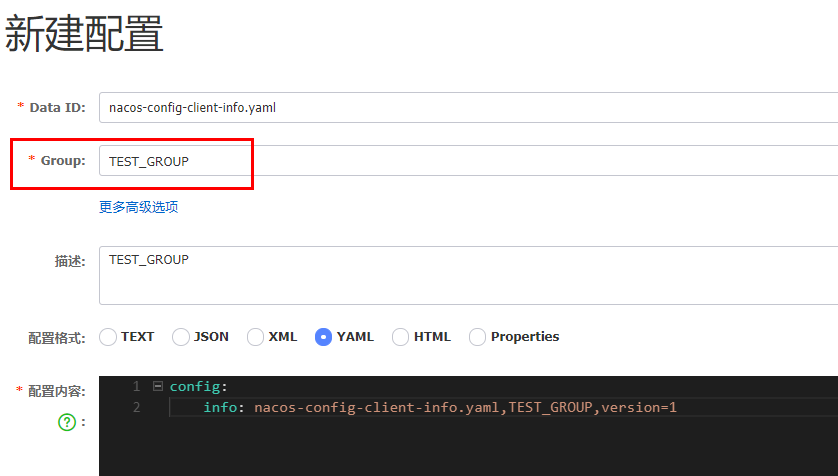
【配置效果】
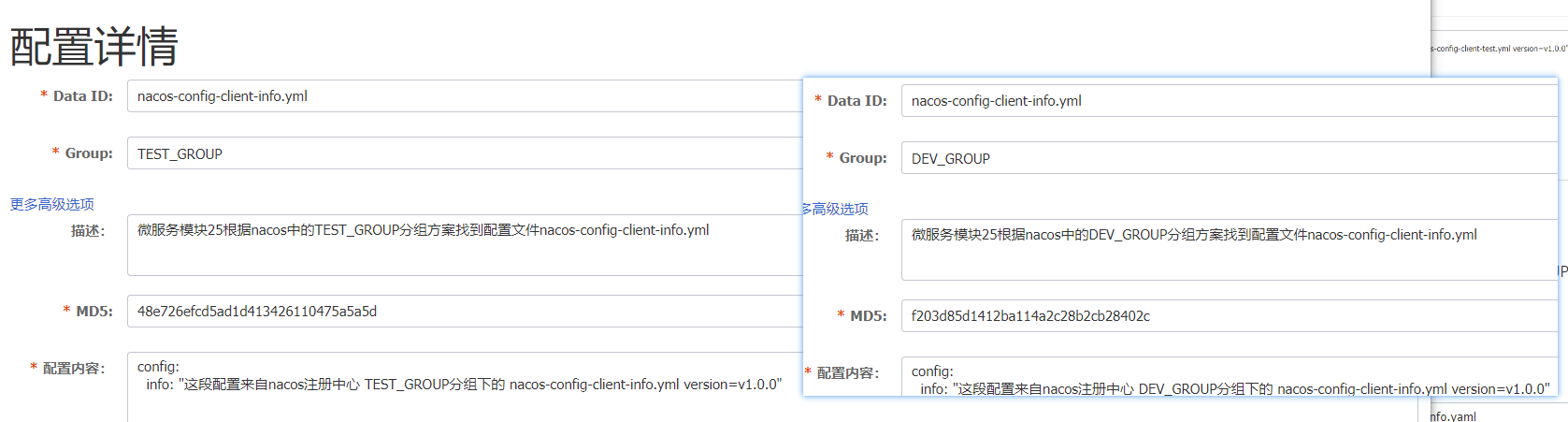
将application.yml中的
spring.profiles.active设置为info,向bootstrap.yml中添加配置spring.cloud.nacos.config.group为目标配置文件分组组名xxxxxxxxxx# nacos配置,Nacos同springcloud-config一样,在项目初始化时,要保证先从配置中心进行配置拉取,拉取配置之后,才能保证项目的正常启动。serverport8015springapplicationnamenacos-config-clientcloudnacosdiscoveryserver-addrlocalhost8848 #Nacos服务注册中心地址configserver-addrlocalhost8848 #Nacos作为配置中心地址#file-extension: yaml #指定yaml格式的配置file-extensionyml #测试配置文件名为yml且此处写yml文件是否可以被访问【经过测试,没有问题,即便是nacos1.2版本以前】#group: TEST_GROUP #找TEST_GROUP分组下的配置文件,没有该配置就找默认分组下的该配置文件groupDEV_GROUP #找DEV_GROUP分组下的配置文件,没有该配置就找默认分组下的该配置文件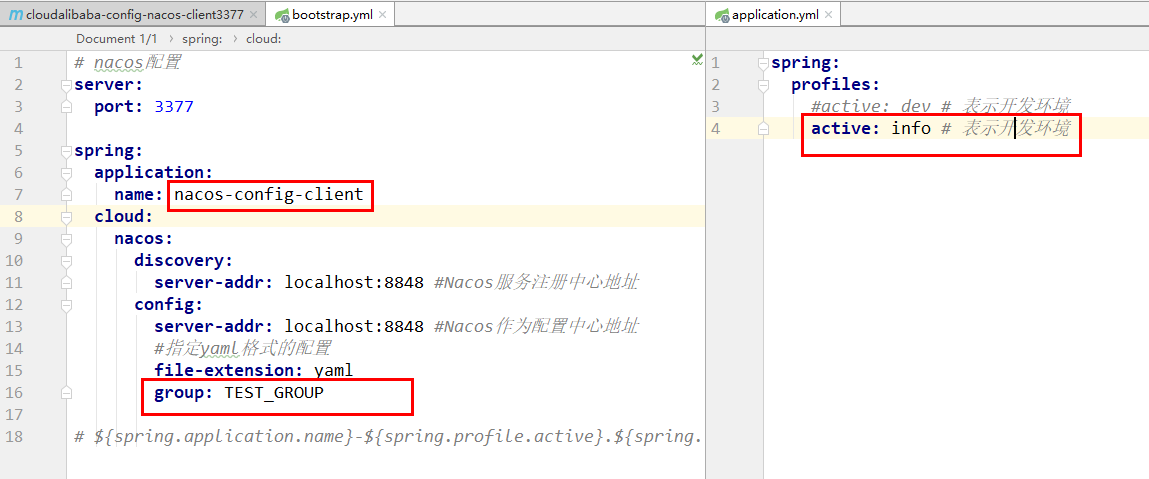
访问微服务读取微服务加载的配置文件内容
Namespace方案
默认public命名空间是删除不了的,自定义命名空间可以删,每个自定义命名空间都对应一个命名空间id
微服务可以通过配置命名空间id属性
spring.cloud.config.nacos.namespace找到对应的自定义命名空间新建dev、test、prod命名空间
【新建】
【命名空间列表】
在三个命名空间下分别创建三个同名的配置文件
nacos-config-client-namespace.yml,两个默认分组。一个DEV_GROUP在bootstrap.yml中配置
spring.cloud.config.nacos.namespace为对应命名空间的id,并变化Group属性为DEFAULT_GROUP和DEV_GROUP,观察服务加载的配置文件内容不配置namespace会走默认的public命名空间
【bootstrap.yml】
xxxxxxxxxx# nacos配置,Nacos同springcloud-config一样,在项目初始化时,要保证先从配置中心进行配置拉取,拉取配置之后,才能保证项目的正常启动。serverport8015springapplicationnamenacos-config-clientcloudnacosdiscoveryserver-addrlocalhost8848 #Nacos服务注册中心地址configserver-addrlocalhost8848 #Nacos作为配置中心地址#file-extension: yaml #指定yaml格式的配置file-extensionyml #测试配置文件名为yml且此处写yml文件是否可以被访问【经过测试,没有问题,即便是nacos1.2版本以前】#group: TEST_GROUP #找TEST_GROUP分组下的配置文件,没有该配置就找默认分组下的该配置文件groupDEV_GROUP #找DEV_GROUP分组下的配置文件,没有该配置就找默认分组下的该配置文件namespacea0abe6ea-86cd-40f1-9ccd-91da442e478a #test命名空间,注释掉就是用默认命名空间#namespace: a88106bf-1518-42a8-935e-bde7b0039596 #dev命名空间,注释掉就是用默认命名空间【application.yml】
xxxxxxxxxxspringprofiles#active: dev # 表示开发环境#active: test # 表示测试环境#active: info # 可以设置通用的profile读取不同分组下的同名配置文件activenamespace测试效果
外部持久化配置
一些重要的系统数据需要配置到Nacos中,同时一些特别重要的数据还需要配置到数据库中,数据库还要采用贮备模式或高可用数据库
nacos内置数据库
Nacos默认使用嵌入式数据库Derby存储数据。如果启动多个默认配置下的Nacos节点,数据存储会存在一致性问题。为了解决这个问题,Nacos采用了集中式存储的方式来支持集群化部署,目前只支持MySQL的存储。【不配置外部数据库mysql的情况下,每个Nacos都会使用自带的数据库做集群配置,会出问题】
在nacos的github源码的pom.xml能找到derby的依赖【为apache开发的产品】
nacos0.7版本前,单机模式只支持使用嵌入式数据库实现数据存储,0.7版本后增加了支持mysql数据源的能力
配置nacos使用mysql实现数据存储
第一步:安装mysql数据库,版本:5.6.5+
第二步:初始化mysql数据库,在nacos中找到confg目录下的数据库初始化文件:nacos-mysql.sql
window下的mysql,新建一个名为nacos_config的数据库,在该数据库下执行sql文件中的代码创建对应的数据库表
第三步:修改nacos的conf/application.properties文件,增加支持mysql数据源配置,添加mysql数据源的url、用户名和密码
【windows下mysql的配置】
Mysql8.0+的:1.去下载一个mysql-connector-java-8.0.27.jar,2.放在nacos\plugins\mysql目录下,因为nacos源码中使用的数据库驱动不一定是8的
不要用nacos1.1.4去支持mysql8,支持不了,实测nacos1.3.1可以支持,一次点亮,而且还自带有针对适合mysql8的url
xxxxxxxxxx#*************** Config Module Related Configurations ***************#### If use MySQL as datasource:spring.datasource.platform=mysql### Count of DB:db.num=1### Connect URL of DB:db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTCdb.user=rootdb.password=Haworthia0715第四步:重启nacos,nacos所有写入嵌入式数据库的数据都会写到mysql

集群配置
eureka需要自己创建每个微服务来组成集群,eureka微服务间要配置相互注册,要配置是否开启保护模式等等,客户端也要对所有eureka集群挨个注册,不方便
nacos生产上一般都用集群
这里的Vip是Virtual IP【虚拟映射IP的意思,物理意义就是nginx】
在linux系统下配置nacos集群并设置mysql持久化【使用1个nginx+3个nacos+1个mysql】
集群架构
【官网架构图】
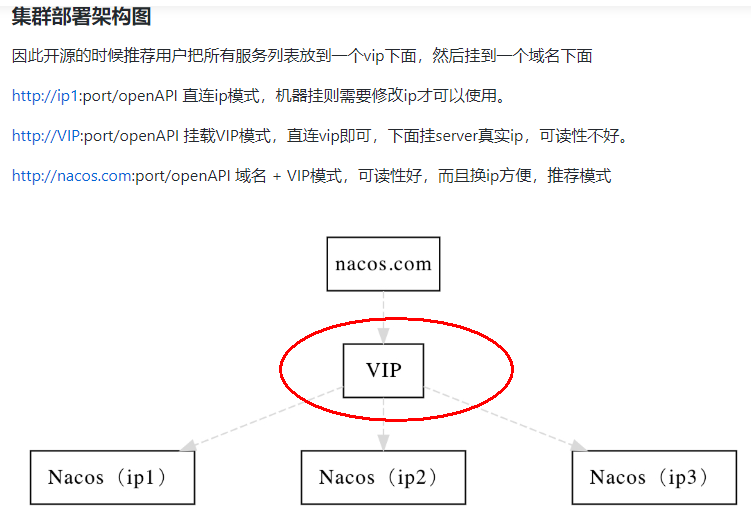
【真实架构图】
nginx是最外面的门户,也需要用集群,就是上图所说的虚拟映射IP
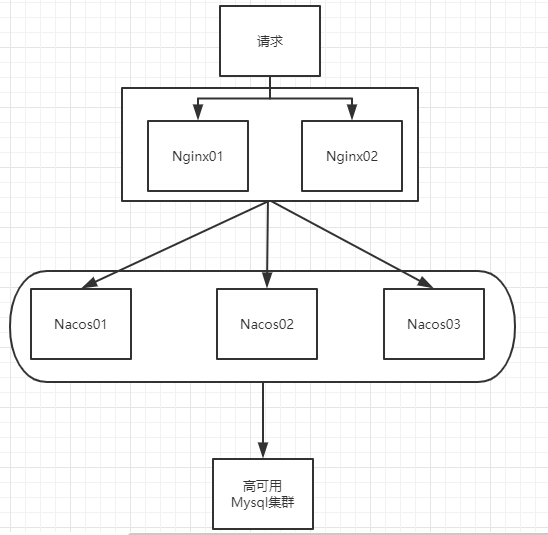
【本次搭建】
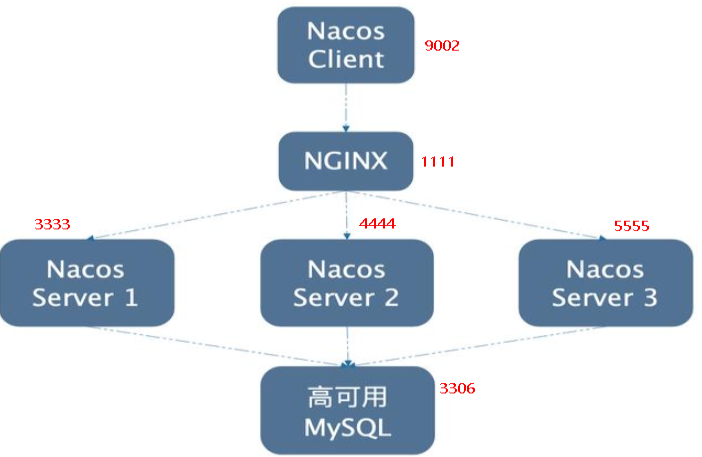
nacos支持三种部署模式
单机模式
用于测试和单机试用
集群模式
用于生产环境,确保高可用
多集群模式
用于多数据中心场景
集群搭建
nacos的运行需要jdk、maven,nacos推荐运行在linux系统中,推荐maven在3.2.x+,需要3个或者3个以上的nacos节点才能构成集群
在Linux上安装Nacos
从地址
https://github.com/alibaba/nacos/tags下载linux系统下的nacos安装包nacos-server-1.3.1.tar.gz将
nacos-server-1.3.1.tar.gz安装包拷贝到/usr/local/nacos目录下使用命令
tar -zxvf nacos-server-1.3.1.tar.gz解压安装包到当前目录进入bin目录使用命令
startup 8848启动nacos
安装成功测试
启动nacos,使用浏览器访问
http://localhost:8848/nacos出现nacos可视化页面即安装成功启动nacos时提示
Public Key Retrieval is not allowed错误解决方法背景
在使用hive元数据服务方式访问hive时,使用jdbc连接到mysql时提示错误:
java.sql.SQLNonTransientConnectionException: Public Key Retrieval is not allowed
原因分析
如果用户使用了 sha256_password 认证,密码在传输过程中必须使用 TLS 协议保护,但是如果 RSA 公钥不可用,可以使用服务器提供的公钥;可以在连接中通过 ServerRSAPublicKeyFile 指定服务器的 RSA 公钥,或者AllowPublicKeyRetrieval=True参数以允许客户端从服务器获取公钥;但是需要注意的是 AllowPublicKeyRetrieval=True可能会导致恶意的代理通过中间人攻击(MITM)获取到明文密码,所以默认是关闭的,必须显式开启。
解决措施
在请求的url后面添加参数allowPublicKeyRetrieval=true&useSSL=false
亲测加了以后不报错正常启动
如果是xml配置注意&符号的转义

注意:Xml文件中不能使用&,要使用他的转义&来代替。
Nacos集群配置
nacos1.3.1能连上mysql8,且配置mysql友好,最好在根目录下创建plugins/mysql目录,把对应mysql的驱动jar包放进去,linux和windows用的驱动jar包是一样的
一台nginx+三台nacos+一台mysql实现注册配置中心集群化配置【自带消息总线】
nacos启动命令
startup 8848默认使用8848,单机版以集群的方式启动,需要修改startup.sh添加startup -p 8848,statup -p 8849,startup -p 8850以多端口的方式启动nacos配置nacos使用mysql数据库进行持久化
凡是修改配置文件的
在linux系统下的mysql中创建数据库nacos_config,在该数据库下使用命令
source /usr/local/nacos/nacos/conf/nacos-mysql.sql执行nacos的confg目录下的nacos-mysql.sql中的SQL语句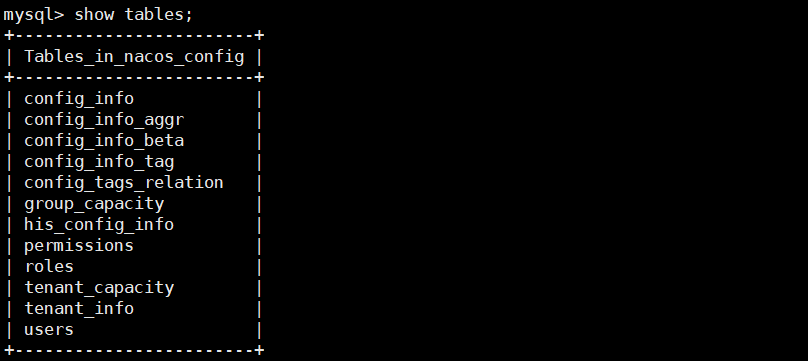
修改配置文件application.properties,让nacos使用外置数据库mysql
xxxxxxxxxx#*************** Config Module Related Configurations ***************#### If use MySQL as datasource:spring.datasource.platform=mysql### Count of DB:db.num=1### Connect URL of DB:db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTCdb.user=rootdb.password=Haworthia0715linux服务器上nacos的集群配置cluster.conf
定出3台nacos服务的端口号,默认出厂没有cluster.conf文件,只有一个cluster.conf.example
使用命令
|拷贝cluster.conf.example文件并重命名cluster.conf使用命令
hostname -i查看本机ens33的ip地址
配置cluster.conf集群配置
集群配置一定要用上述的ip地址
xxxxxxxxxx#cluster server192.168.200.132:8849192.168.200.132:8850192.168.200.132:8851修改nacos启动脚本startup.sh,使其能接受不同的启动端口
就是在启动脚本中写入命令
startup -p 8849【端口号一定要是在cluster.conf中配置过的端口】使用命令
set number或set nu在vim中显示行号,使用命令set nonu[mber]取消显示行号,使用命令set nu!或者set invnu[mber]反转行号【反转行号显示的效果是有行号变成不显示行号,没有行号的变成显示行号】,使用命令set relativenumber设置相对于某一行的行号将反转行号绑定到按键将这行代码
nnoremap <C-N><C-N> :set invnumber<CR>放入vimrc文件中,意思是连按两下<Ctrl-N>便可以反转行号显示【<Ctrl-N>就是CTRL+n的意思,CTRL+N也可以用】,如果要在【insert模式】下反转行号显示,可以使用代码:inoremap <C-N><C-N> <C-O>:set invnumber<CR>【修改启动脚本】
修改前:如果启动命令传递的是m就走模式分支MODE,传递的是f就走FUNCTION MODE分支,传递的是s就走SERVER分支
修改后添加了
p:,传参p就会走PORT分支,表示传递变量值$OPTARG给变量PORT
在$JAVA和$JAVA_OPT之间加了
-Dserver.port=${PORT}表示把输入启动命令的参数值即此前给PORT赋值的参数值传递给$JAVA -Dserver.portNacos本身没做这个原因应该是,学习是在同一台机器进行。实际生产在不同服务器做分布式集群。
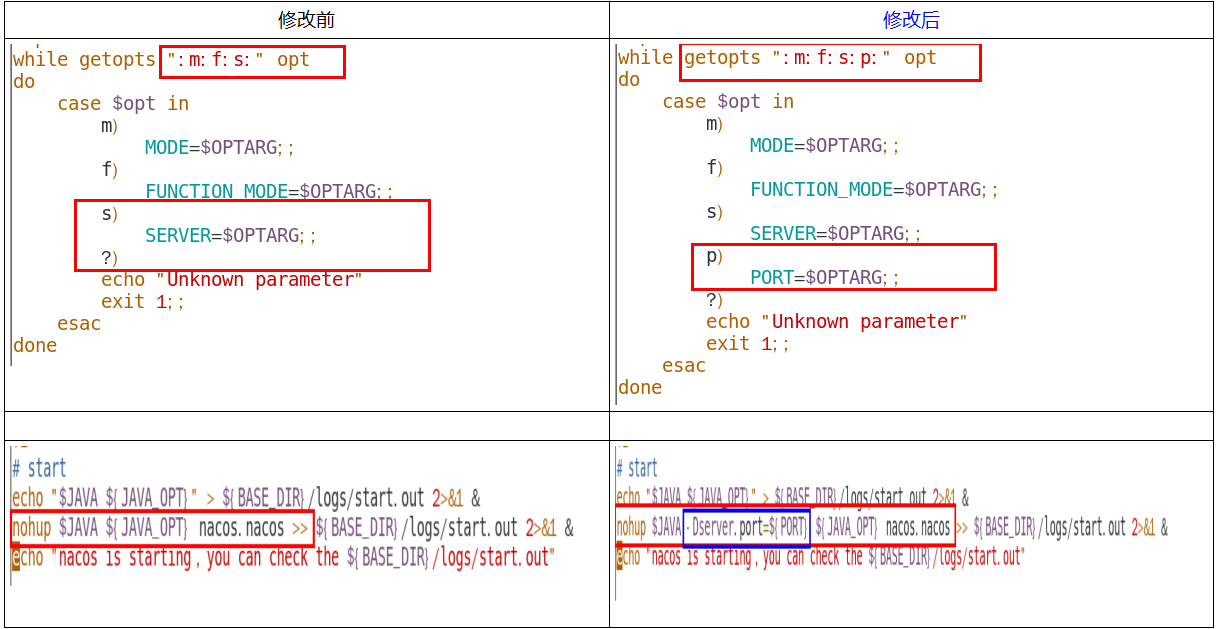
在nacos根目录下创建plugins/mysql目录,将对应mysql数据库的驱动引入其中,windows下用的jar包就行,经过测试,能正常启动,因为第一次的startup.sh的
-Dserver.port写到上一行去了,所以启动不起来才考虑加入mysql驱动插件的,然后发现startup.sh写错了,改了以后启动正常了,但是是否要加驱动jar包就不知道了,反正加了不会报错修改Nginx配置,让其作为负载均衡器
nginx的配置

测试
启动mysql服务
在nacos的bin目录下使用命令
./startup.sh -p 8849和./startup.sh -p 8850和./startup.sh -p 8851在不同端口启动3台nacos服务器启动单台一定要测试是否启动成功,直接在浏览器访问对应端口的服务,启动不了nginx是访问不了的
使用ps命令确认过三台nacos服务都启动了
使用命令
ps -ef|grep nacos|grep -v grep|wc -l可以查看nacos服务器启动的台数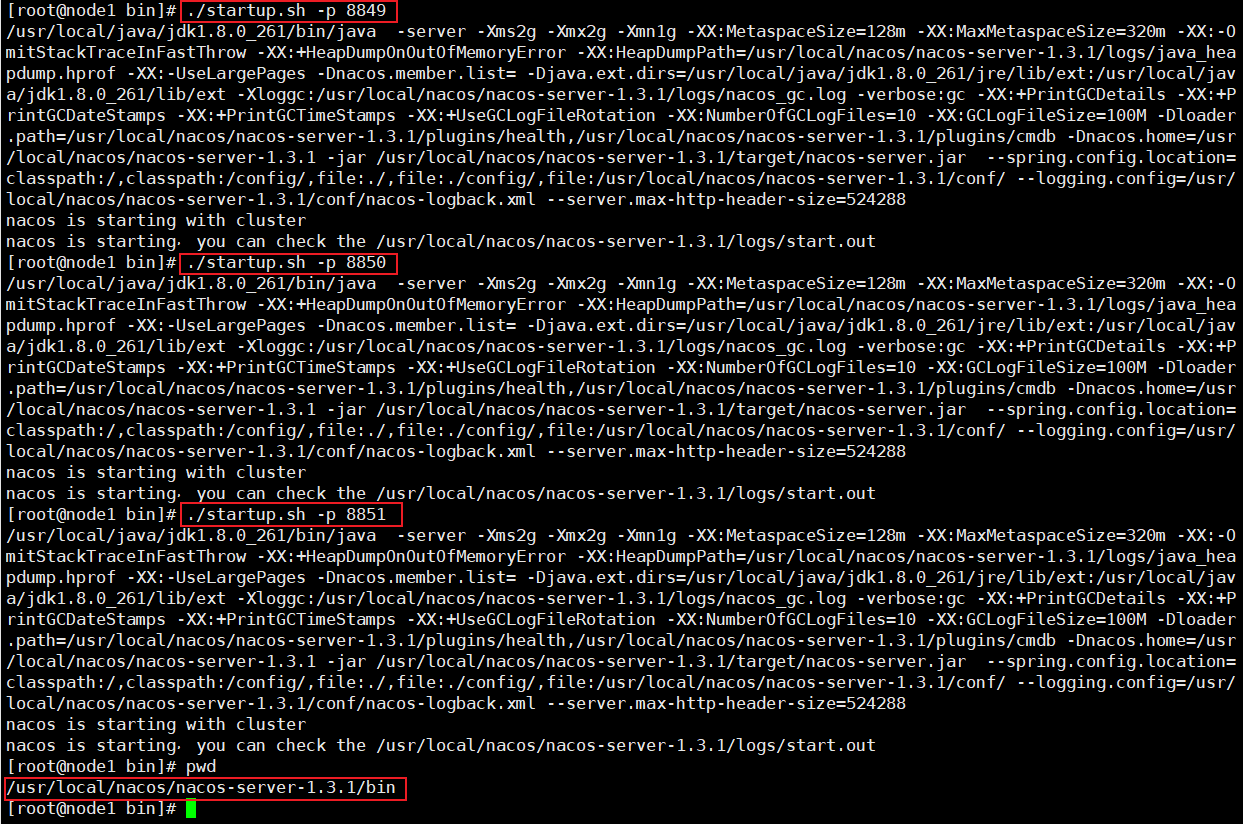
在nginx的sbin目录下使用命令
./nginx -c /usr/local/nginx/conf/nginx.conf启动nginx使用ps命令确认过nginx服务已经启动

使用请求路径
192.168.200.132:1111/nacos访问nacos集群
测试集群是否搭建成功
启动后发现只有两台nacos启动了,第三台无法访问
原因是虚拟机内存用完了

【nacos服务状态】
第三台因为内存不够没启动成功,这里有第一个8848端口的nacos是因为配置文件写错了,后来改了,最后一个是因为虚拟机内存不够了,启动不起来
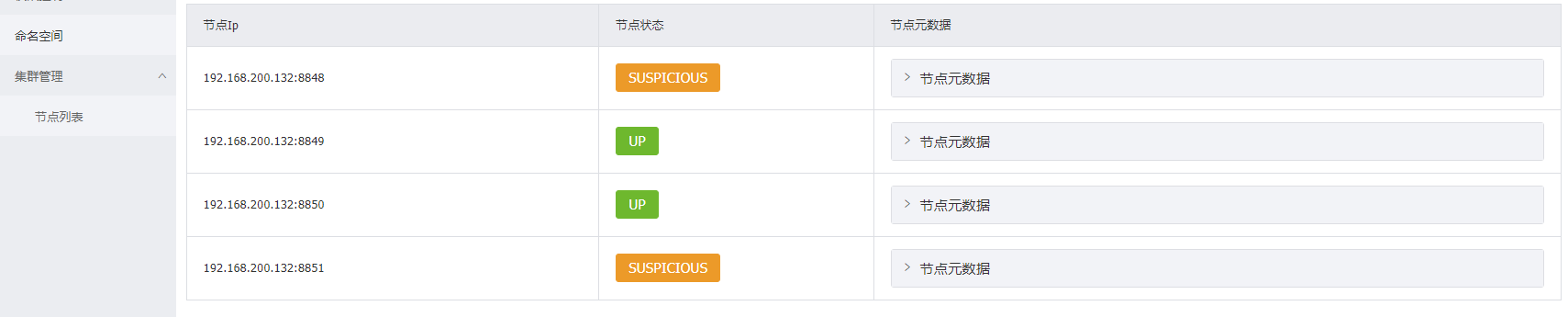
新建配置文件
配置文件会创建在数据库nacos_config的config_info表下,存在服务器没起来也能新建配置文件写入数据库,但是存在nacos服务器起不来,无法向nacos集群注册服务,服务列表是空的
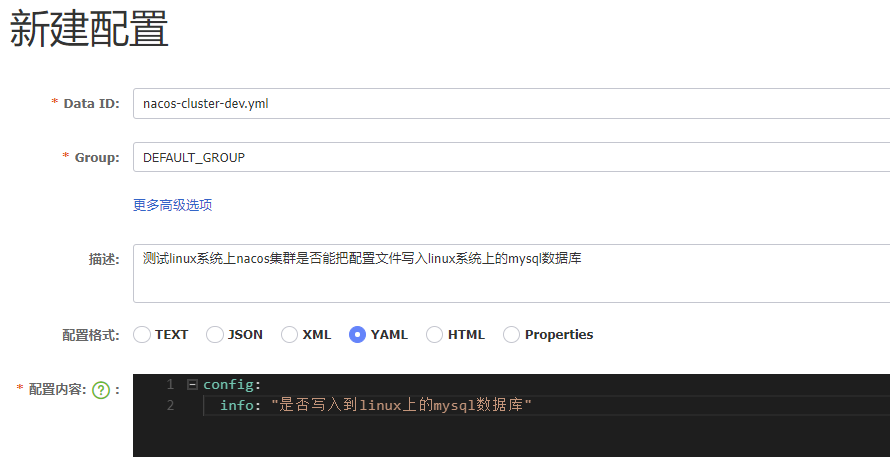
【数据库配置文件存储实况】
文件名、配置文件信息都和新建配置一模一样
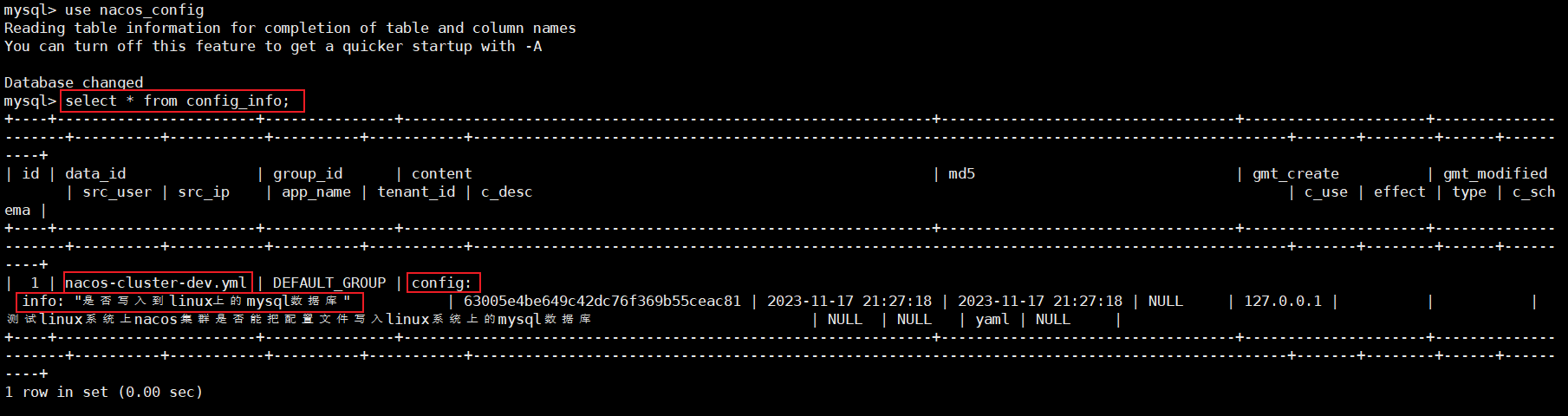
将模块23的注册中心迁移到linux系统上由nginx负责负载均衡的nacos集群上来
此时读取的应该是linux上mysql数据库的配置文件
23模块配置文件切换注册中心为nacos集群
xxxxxxxxxxserverport8014springapplicationnamenacos-provider-paymentcloudnacosdiscovery#server-addr: localhost:8848 #配置Nacos地址server-addr192.168.200.1321111 #配置Nacos地址managementendpointswebexposureinclude'*' #暴露要监控的所有端点,actuator中的,雷神springboot最后有讲如果nacos注册中心中服务列表显示该模块则证明服务成功注册到nacos集群中
几个要点,
nacos中的集群管理的节点列表中会显示写在配置文件的所有nacos服务器,只要这个列表中有一台服务器起不起来,比如虚拟机内存不够了服务就启动不起来,此时服务就无法注册到nacos集群中,服务列表不会显示启动的服务【错误配置8848端口的nacos没有上线其他三台正常服务无法注册;更正8848后故意只启动两台,服务无法注册,报错拒绝连接;此时启动第三台,服务成功注册】只要有一台nacos服务器宕机,服务就无法注册到注册中心,这不是违背高可用和配置集群的原则吗?
可以修改nacos的配置文件来限制nacos的运行内存大小,达到增加集群中服务器数量的目的
修改nacos运行内存限制
【运行内存的默认配置】
在startup.sh中的JVM配置中
【更改后的运行内存配置】
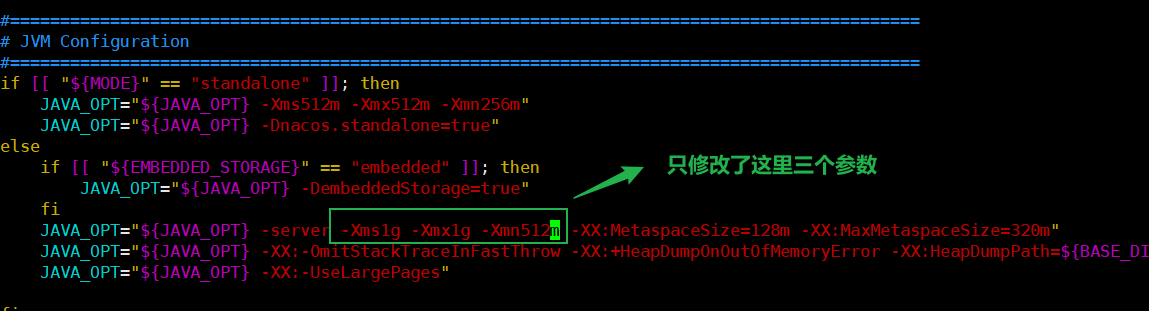
【修改后再次启动三个服务均运行正常】
第一个有8848纯属是nacos集群配置文件写错了,多加了一个8848,更改后就好了
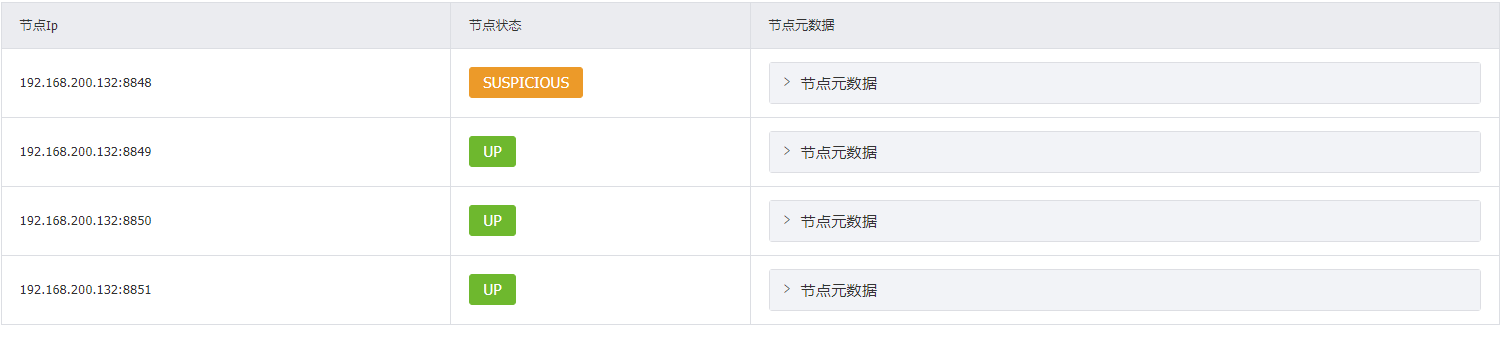
Sentinel熔断限流
实现熔断与限流,是一个轻量级面对云原生微服务的流量控制、熔断降级组件,能够监控保护微服务
官方文档:https://github.com/alibaba/Sentinel
中文文档:https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D
下载地址:https://github.com/alibaba/Sentinel/releases
sentinelResoource是由sentinelResourceApect切面类实现的,看这个类的源码就知道这里是怎么处理的了,逻辑很简单
几种熔断框架的比较
国外用redilience4j比较多
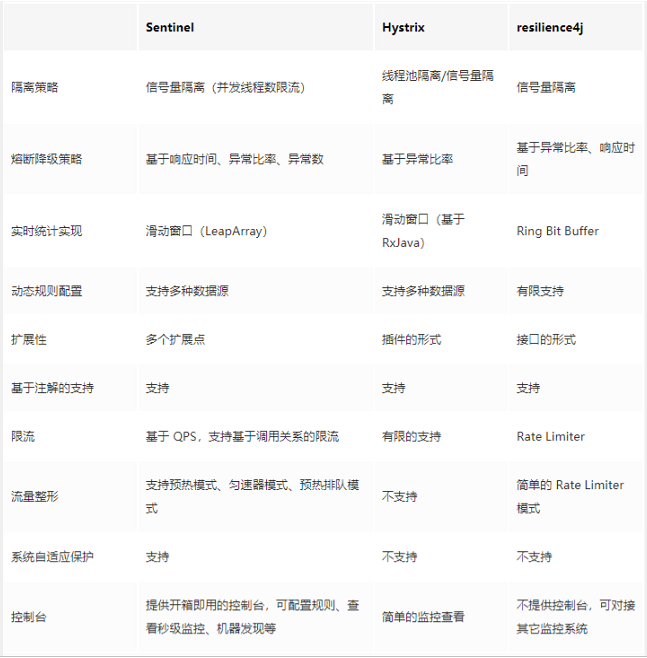
Sentinel简介
Sentinel的配置都可以写在代码中,但是本次学习仍然大规模使用配置和注解的方式,少写代码,用配置代替编写
Sentinel主要特性
主要是做绿色区域的功能,粗略的说就是防止服务雪崩、实现服务降级、服务熔断、服务限流
应用场景丰富
承接阿里十年双十一的流量核心场景,如在秒杀即将突发流量控制在系统容量可承受的范围内,消息销峰填谷,集群流量控制,实时熔断下游不可用服务
实时监控完备
可以在控制台中看到接入应用的单台机器的秒级数据,甚至能架空500台以下服务集群的运行汇总情况
开箱即用
提供与多种开源框架的整合模块,如SpringCloud、Dubbo、gRPC都只需要引入响应的依赖就能快速整合Sentinel
SPI扩展点
提供完善的SPI扩展点,通过实现扩展接口能快速定制规则管理、适配动态数据源等
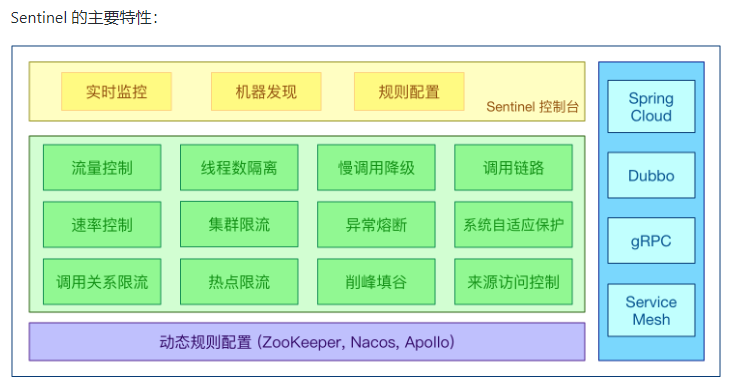
Sentinel的开源生态
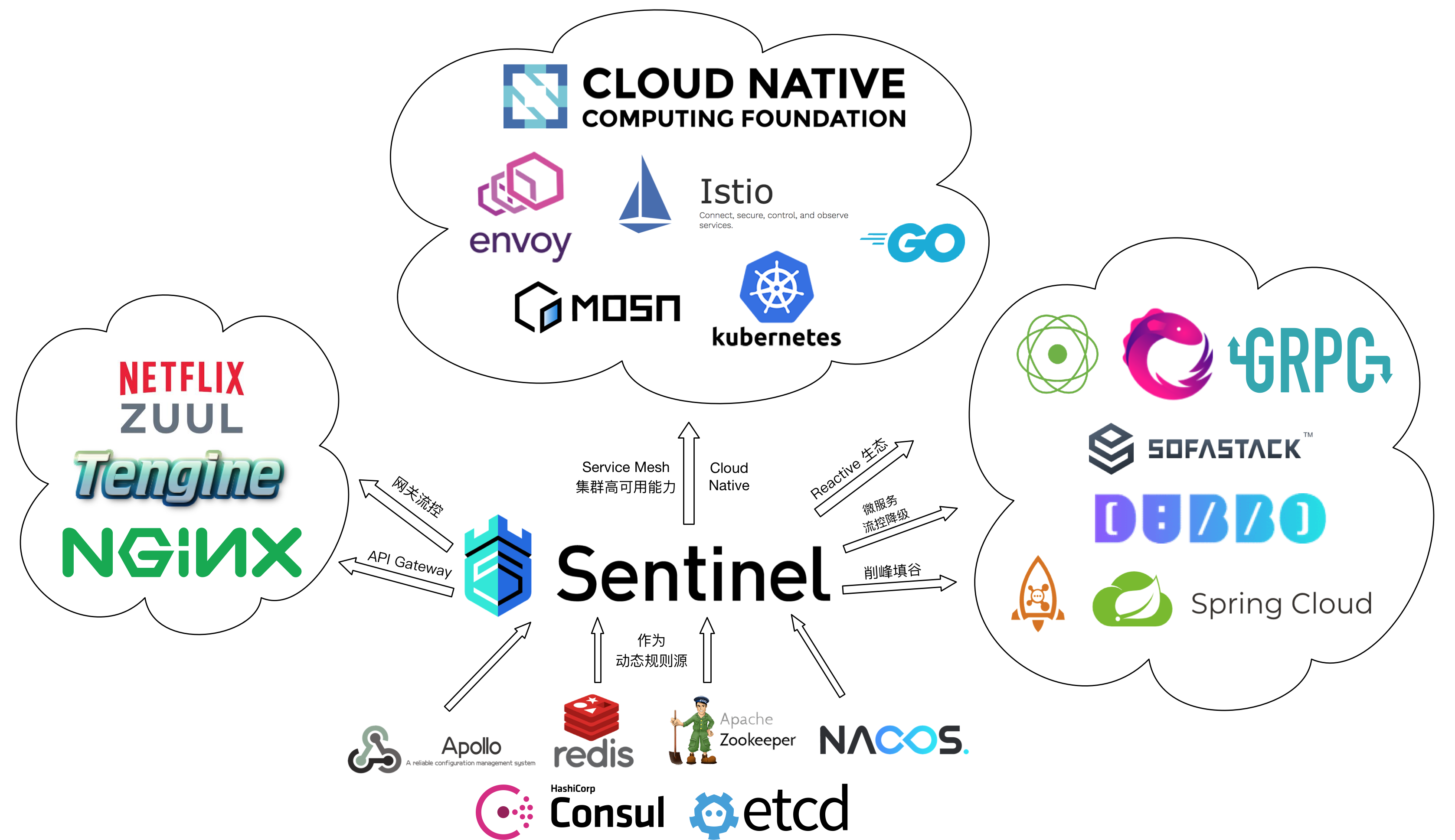
Hystrix的缺点
需要程序员自己手工搭建HystrixDashboard对服务进行可视化监控
没有一套web界面停更给程序员更细粒度化的配置流控【降低某个微服务的访问量】、速率控制【漏斗算法进行速率控制】、服务熔断、服务降级
Sentinel相较于Hystrix的优点
形成单独独立的组件,不需要程序员对监控面板手动搭建
使用界面化的监控平台能够细粒度地对服务进行统一配置
Sentinel的安装
下载v1.7.0版本,下载
Sentinel-dashboard-1.7.0.jar安装sentinel控制台【sentinel和Hystrix一样由后台和前台组成,前台就是监控界面,默认端口是8080】
后台就是java核心类库,运行于java的jre环境,对Dubbo和SpringCloud有较好支持
控制台就是Dashboard,是基于SpringBoot开发的并被打包成jar包,使用
java -jar Sentinel-dashboard-1.7.0.jar命令就能直接运行前提,有java8运行环境,8080端口不能被占用,Tomcat的端口就是8080,不知道为何sentinel也选8080
运行jar包后使用连接
http://localhost:8080访问sentinel界面使用命令启动异常,原因是因为jdk的版本太高,原以为是jdk8,一查真是17,可以更改启动命令,使用特定的包进行反射
java --add-opens java.base/java.lang=ALL-UNNAMED -jar sentinel-dashboard-1.8.1.jar,也可以将jdk的版本降低至jdk8,降低后启动正常初始账户密码都是sentinel

【控制台页面】
整合Sentinel
新建26模块,以nacos作为注册中心,整合Sentinel进行流控、熔断和服务降级
启动nacos控制台,登录nacos控制台
http://localhost:8848/nacos一定要加nacos,否则会提示不一样的404,类似于nacos自带的资源找不到页面
创建26模块整合sentinel
pom.xml
xxxxxxxxxx<dependencies><!--SpringCloud ailibaba nacos --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--SpringCloud ailibaba sentinel-datasource-nacos 后续做持久化用到,sentinel和nacos是有关联的,可以用nacos做持久化,所以项目之初就可以引入nacos、sentinel、sentinel和nacos的数据源依赖--><dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</artifactId></dependency><!--SpringCloud ailibaba sentinel --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency><!--openfeign服务调用--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!-- SpringBoot整合Web组件+actuator --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--日常通用jar包配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>4.6.3</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport8015springapplicationnamesentinel-clientcloudnacosdiscovery#Nacos服务注册中心地址server-addrlocalhost8848sentineltransport#配置Sentinel dashboard地址,8080只是控制器界面端口dashboardlocalhost8080#通讯监听端口默认找8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口#8015:微服务端口 8080:sentinel前台展示端口 8719:sentinel后台监控端口port8719managementendpointswebexposureinclude'*'启动类
xxxxxxxxxxpublic class SentinelApplication {public static void main(String[] args){SpringApplication.run(SentinelApplication.class,args);}}业务类
xxxxxxxxxx("/sentinel")public class FlowLimitController {("/test1")public String test1(){return "------test1";}("/test2")public String test2(){return "------test2";}}
使用命令
java -jar sentinel-dashboard-1.7.0.jar启动sentinel控制台启动微服务26模块
此时会发现sentinel控制台仍然没有任何信息,是因为Sentinel使用了懒加载,执行一次控制器方法对微服务进行一次访问就会显示微服务信息
关于使用高版本的控制台爆
web configuration错误的循环依赖问题的在yml中增加Spring.main.allow-circular-references=true注意:用 Linux 系统装的 Sentinel 的同学,除了 yml 多配了一个 clientIp 外,还需要确保 Linux 系统和你Windows 系统的时间是一致的
勿使用JDK1.8以上版本启动sentinel的jar包,网页正常但无法显示服务。
【访问前】
【访问一次后】
【实时监控效果】
一个控制器方法一张表
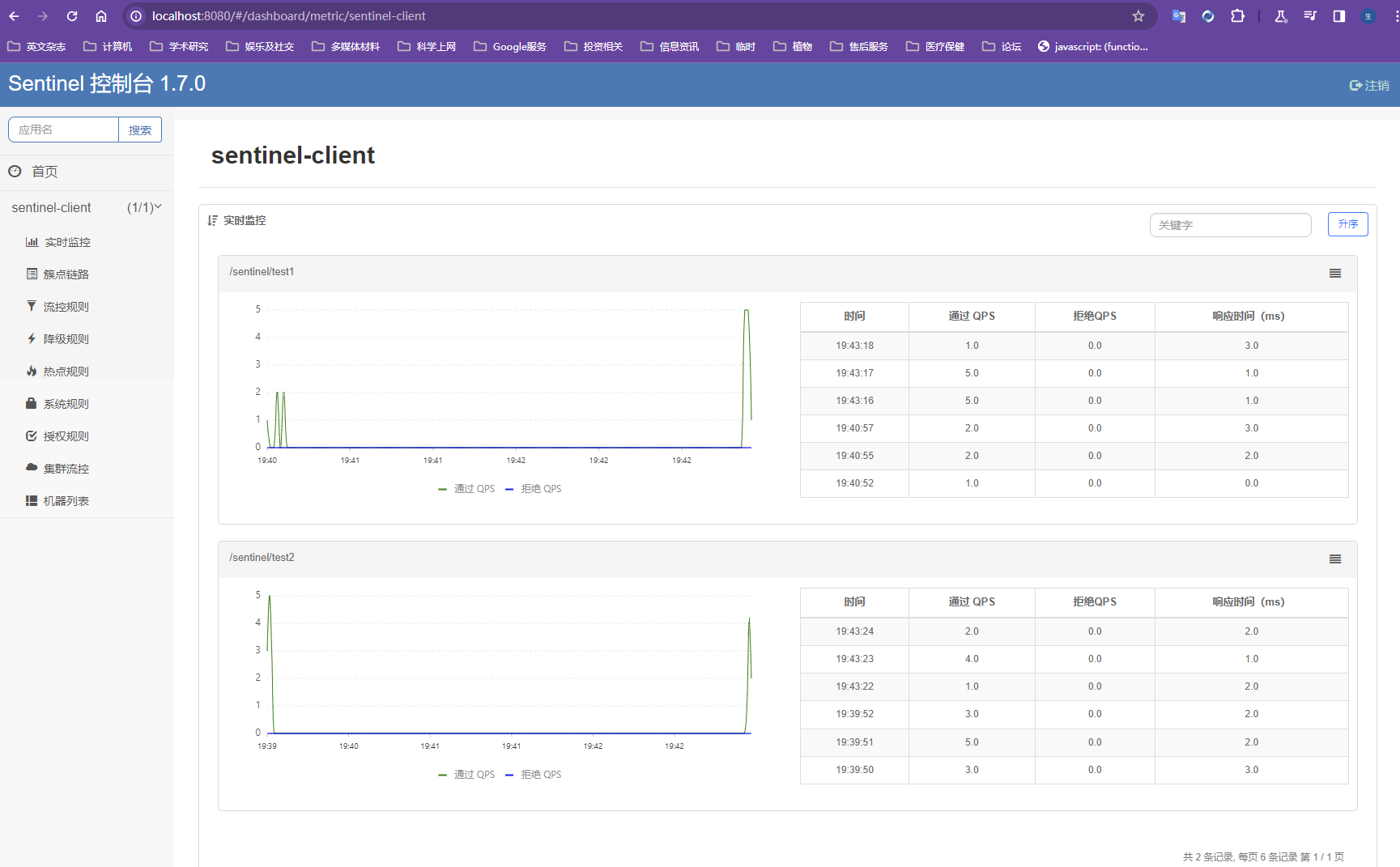
【簇点链路】
访问了哪些簇点,拼接成了什么链路,簇点的意思是类似于可以发起的请求吗
Sentinel流控
流量控制,
流控参数
资源名:默认以请求路径作为唯一名称
针对来源:Sentinel可以针对调用者【指系统中的微服务消费者】进行限流,这里填写调用者指微服务名称,默认是default【不针对任何调用者限流】
阈值类型:
QPS【每秒钟的请求数量】:当调用指定api【即资源名指定的api】的QPS达到闻值的时候,进行限流
线程数:当调用该api的线程数达到阈值的时候,进行限流
单机阈值:是对单台机器的QPS或者线程数的阈值进行指定【超过该阈值会提示前台页面被sentinel锁住限流了,会自动恢复】
直接调用默认报错信息直接返回给前台,考虑自定义限流信息提示【默认+自定义的方式】
是否集群:不需要集群
流控模式:
直接:当对应资源达到限流条件时,直接限流资源本身,以资源抛异常并提示被限流信息的方式实现限流自己
关联:当关联的资源达到阈值时,就限流自己
两个资源,比如订单资源处理后会经过支付资源,支付资源达到阈值后【订单资源并没有达到阈值】限流与其关联的订单资源,
链路:只记录指定链路上的流量【指定资源从入口资源进来的流量,如果达到阈值,就进行限流)】[api级别的针对来源]
流控效果:
快速失败:直接失败,抛异常,展示的效果就是报
Block by SentinelWarm Up:根据codeFactor 【冷加载因子,默认3】的值,设置单机阈值为10,从单机阈值/codeFactor等于3作为系统初始单机阈值,经过设置的预热时长【单位秒】,缓慢将单机阈值达到设置的QPS阈值10
排队等待:匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效0
流控模式
添加流控规则
可以从簇点菜单的资源列表添加流控规则,也可以从流控规则菜单添加【都是默认以请求路径uri作为资源名】,在簇点菜单添加设定规则后会显示在流控规则中
设置超QPS阈值时限流服务
请求uri
sentinel/test1一秒钟请求数量超过1次就限流锁资源
【添加效果】
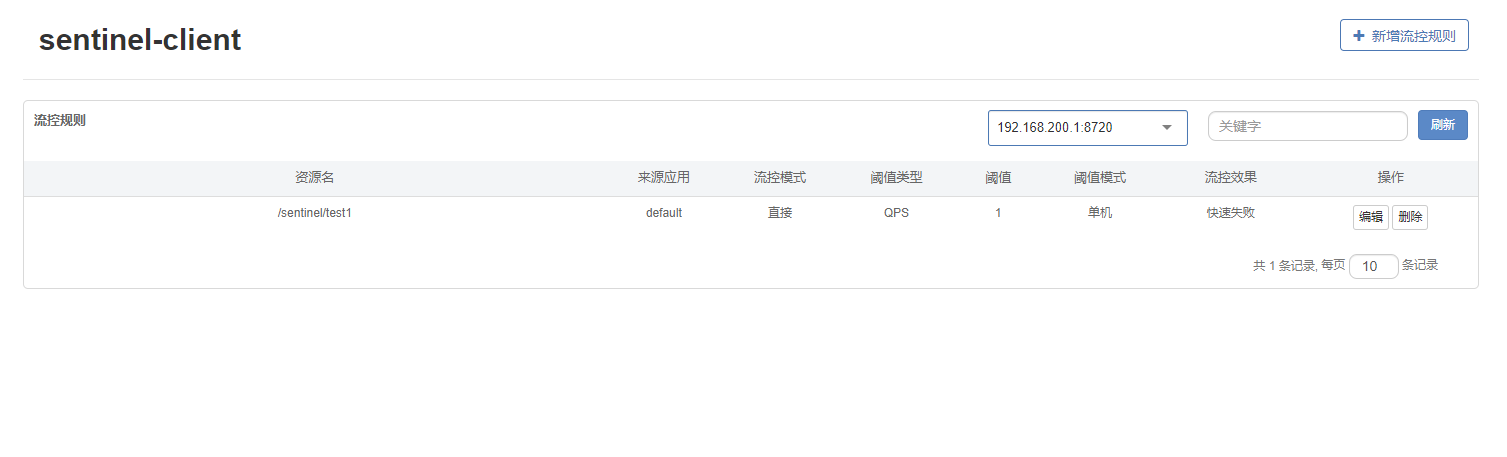
【测试效果】
这是默认的提示信息,可以自定义提示信息,这也是流控效果快速失败的效果
设置超线程数阈值时限流服务
设置
sentinel/test2单个请求执行时间2秒,使得上一个请求还没处理完,新进请求需要使用额外的线程xxxxxxxxxx("/test2")public String test2() {try{TimeUnit.SECONDS.sleep(2);}catch (InterruptedException e){e.printStackTrace();}return "------test2";}配置
sentinel/test2流控策略
测试效果
两秒内发起第二次请求就会出现这个限流提示
关联
两个资源,比如订单资源处理后会经过支付资源,支付资源达到阈值后【订单资源并没有达到阈值】限流与其关联的订单资源,支付服务要瘫痪了,订单服务就不要下单下太猛了
简单地说就是一个资源达到阈值后将会导致与其关联的另一个资源不能使用
流控配置
清空此前流控规则,注释掉test2的休眠时长,对test2设置关联流控模式,关联到test1,一旦test1的QPS超过每秒1次,test2会被直接限流,这很重要,不要配置错了,一定是test1超阈值test2限流;不是test2超阈值test1限流
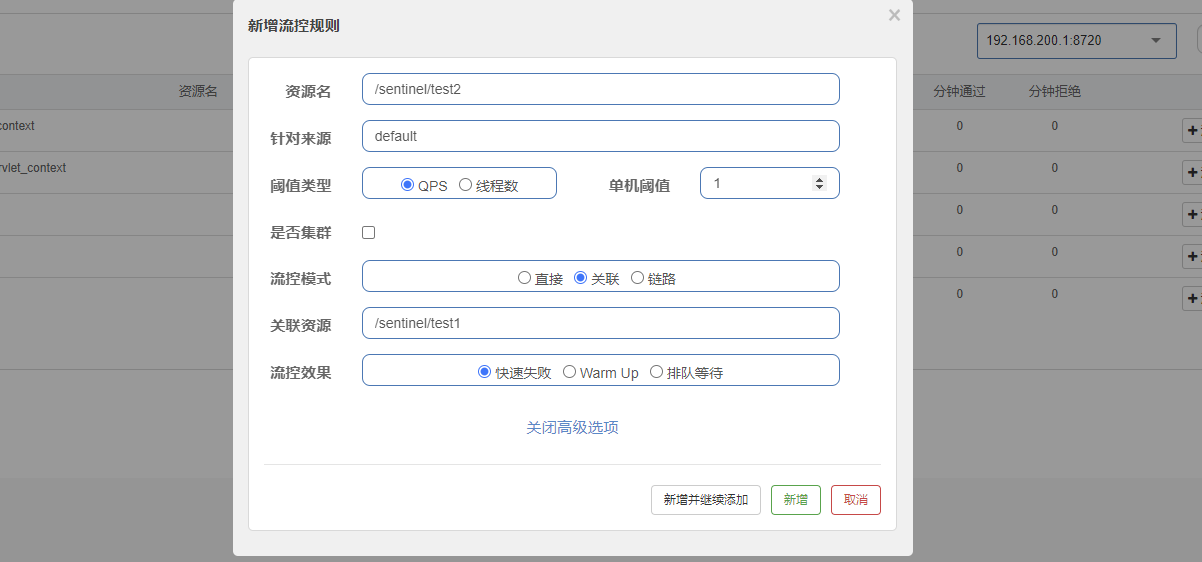
使用Postman密集向test1发送并发请求
postman的runner是串行不是并发的,市面上的大多数接口测试软件都不支持并发,真正支持并发的只有Jmeter,这里配置的意思理解为请求间隔0.3秒,循环发起20次请求
【将单个请求保存到集合】
设定请求发送规则
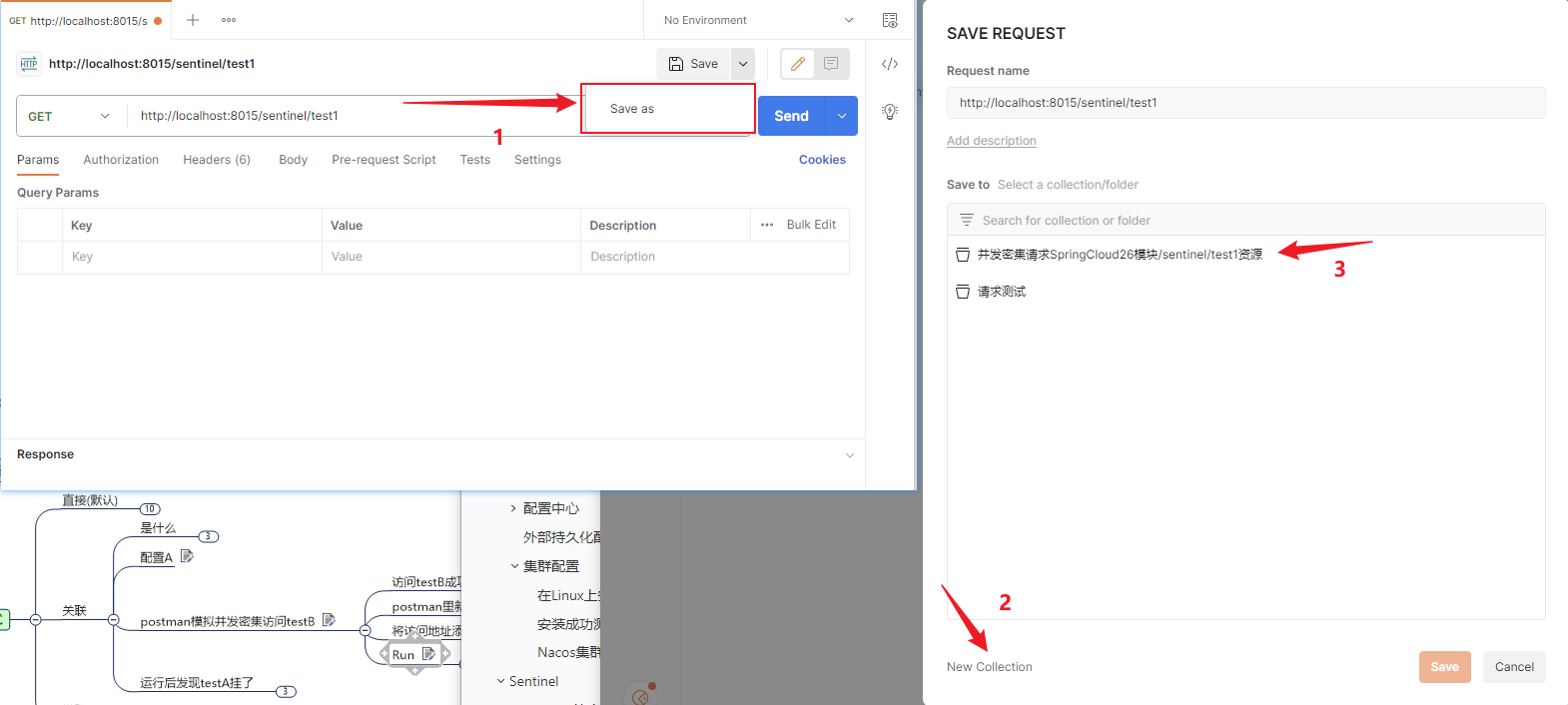
【设置请求发送规则】
请求间隔0.3秒,发送20次
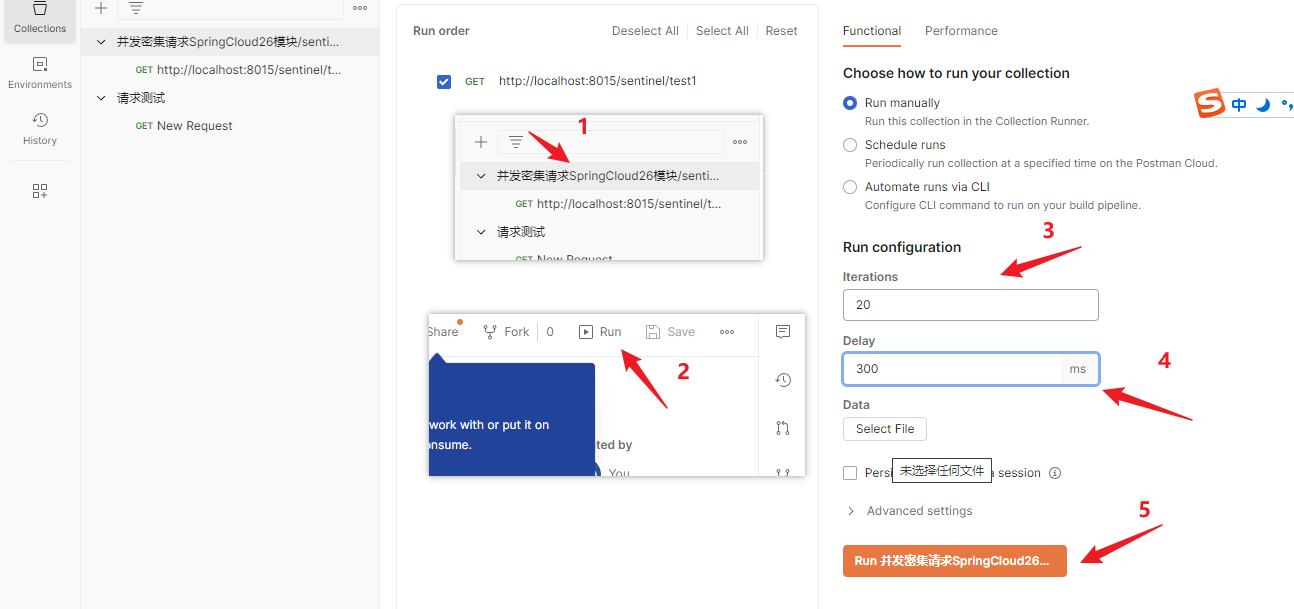
测试结果
postman向test1发送请求每秒QPS超过1个,此时test1的关联资源test2被限流了
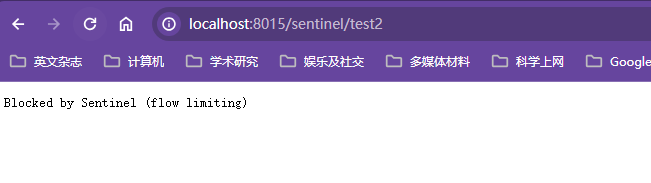
链路
课程不讲,连概念都不讲,自己看官网和博文补充吧
流控效果
参考官方文档https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
直接失败
通过抛出异常的方式快速失败,是默认的流控处理,com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController是直接失败的源码
预热【Warm Up】
Warm Up(
RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。详细文档可以参考 流量控制 - Warm Up 文档,具体的例子可以参见 WarmUpFlowDemo。
通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:

预热的设置
选择预热模式下,在平时访问量很少的情况下,QPS没有达到以单机阈值/冷加载因子【默认值是3】作为初始阈值,当资源访问量超过该初始阈值,尝试在预热时长设置值5s内将单机阈值提升到预设值
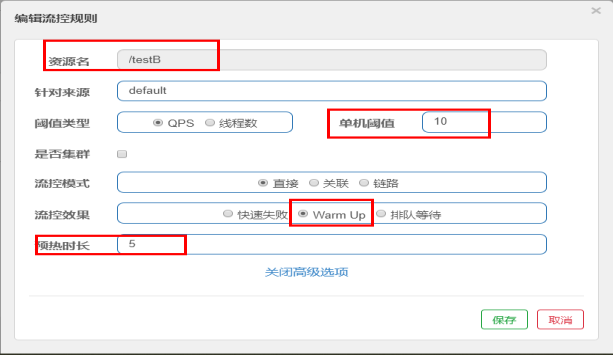
冷加载因子
在类
com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController的构造方法中默认了冷加载因子是3
预热效果
刚开使连续点击,会显示被锁住的情况,信息提示和快速失败一样,五秒钟后,单机阈值上去了就不会被限流【不显示提示】,但是超过单机阈值的上限又会被重新限流,QPS降低到初始阈值以下再次上升又会重复这一过程
匀速排队
就是请求排队,高并发请求进入服务器开始排队,类似于打饭窗口,一次最多处理窗口个数的打饭请求【开几个窗口可以系统自己决定】,剩下的请求排队
匀速排队(
RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。详细文档可以参考 流量控制 - 匀速器模式,具体的例子可以参见 PaceFlowDemo匀速排队作用示意图
让请求以一定时间间隔被排队处理,这种方式主要用于处理间隔性突发的流量,例如消息队列。【这样的设计主要用于某一秒有大量的请求到来,接下来几秒时间处于空闲状态,希望在接下来的空闲时间内逐渐处理这些请求,而不在第一秒直接拒绝】
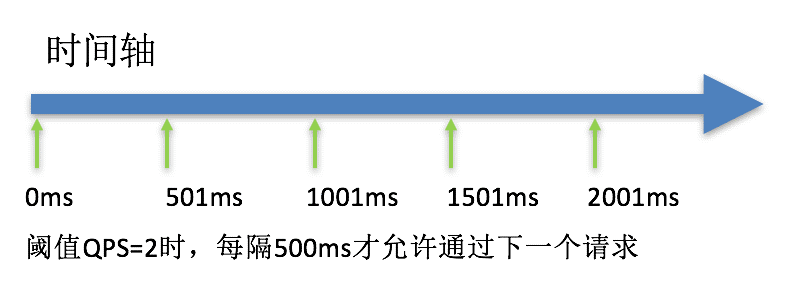
匀速排队的阈值类型只能设置成QPS,不支持设置线程阈值,且匀速排队模式暂时不支持QPS >1000的场景,选线程数就自动把流控效果面板关闭了
流控规则设置
对资源/testA限制QPS阈值每秒一次请求,超过的请求进行排队等待,设置请求的超时时间为20s,即超时未处理就报限流信息提示
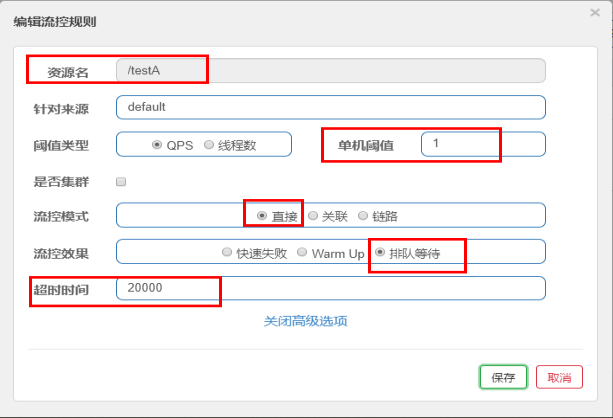
测试
设置对test1的匀速排队,限定每秒只能处理一个
有时候可能没设置上,多刷新页面或者删掉流控规则重新设置
后台打印时间,对test1进行访问,直接用postman间隔0.1秒发起20次请求,观察后台的线程和时间状况
【请求规则】
经过测试,Postman的请求是串行的,如果响应时间大于请求的发起间隔,会在响应时间结束后再次发起新的请求
所以这里使用jmeter进行测试
【postman请求测试】
【jmeter测试参数】
这个等待响应也是一秒一秒的响应,请求是否瞬间发完没有找到日志【还要具体学一下jmeter】,但是总归是因为设置了流控规则才导致的执行是间隔1s执行的
【jmeter并发请求后台响应】
Sentinel降级
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时【例如调用超时或异常比例升高】,对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断【默认行为是抛出 DegradeException】
降级参数
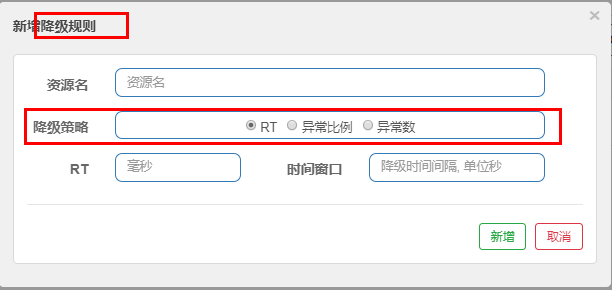
RT【平均响应时间,单位是毫秒】
当平均响应时间超出设置的RT阈值且在1s进入的请求数
≥5,两个条件同时满足的情况下触发资源降级,在接下来的时间窗口【DegradeRule中的timeWindow】以抛出DegradeException异常的方式自动熔断对用的方法窗口期过后关闭断路器,可以正常访问
RT的最大值为4900,即5s钟以内,更大的平均响应时间需要通过
-Dcsp.sentinel.statistic.max.rt=XXXX进行设置
注意:最新版本 RT 改为 慢调用比例 (SLOW_REQUEST_RATIO),并且引入 HALF-OPEN 状态
异常比例【秒级统计】
QPS≥5且异常比例超过阈值时触发服务降级,时间窗口结束后关闭断路器
异常数【分钟统计】
异常数超过阈值时触发降级,时间窗口结束后关闭断路器
降级策略
RT
平均响应时间超过200ms且每秒请求数超过5个就会发生服务熔断,
控制器方法
xxxxxxxxxx("/test3")public String test3(){//暂停几秒钟线程try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("test3 测试RT");return "------test3";}降级策略配置
平均响应时间200ms以内,发生服务熔断后时间窗口1s内任何对该资源的请求都会被熔断,sentinel1.8以前没有半开状态,1.8以后有了
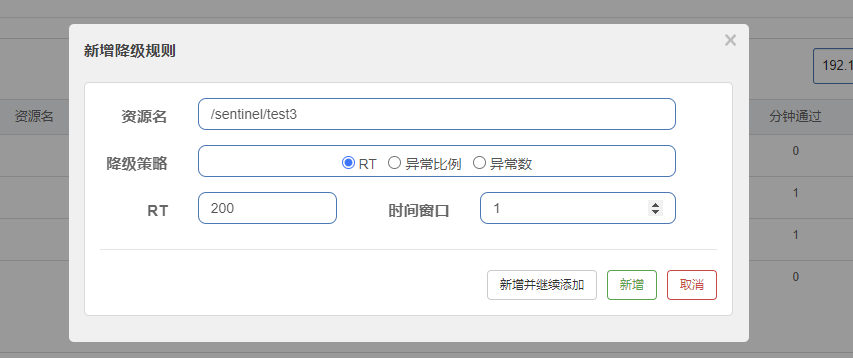
jmeter测试规则
一秒钟10个请求,无限发送,请求期间访问对应的test3资源服务熔断
效果
和流控的直接失败显示的是一样的效果,CPU都拉满了,关闭以后CPU使用率变成个位数
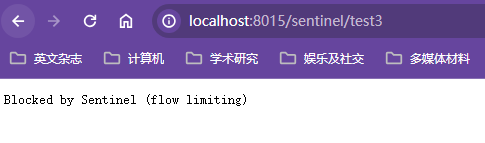
【关闭jmeter后效果】
在预设时间窗口1s后恢复
根据异常比例判断服务降级
每秒钟的请求数≥5且每秒钟异常比例超过设定的阈值会触发降级打开断路器,时间窗口期结束后关闭熔断器开启对资源的访问
确认是官网说的每秒请求数大于等于5且每秒钟异常总数栈通过量的比值超过阈值
设置服务降级参数
意思是当
QPS≥5的条件下,当每秒钟的异常比例大于0.2会直接触发服务降级,对服务进行熔断,熔断的时间窗口是3秒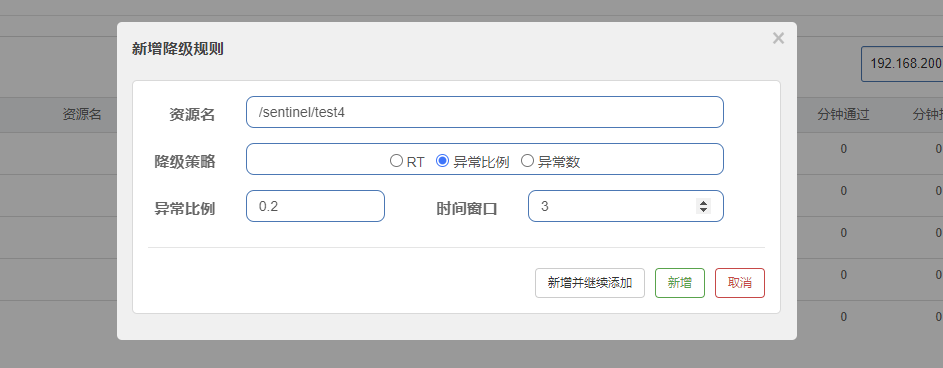
控制器方法
xxxxxxxxxx("/test4")public String test4() {int i=10/0;log.info("test4 测试RT");return "------test4";}使用jmeter发起并发请求
触发每秒QPS大于等于5,触发每秒的异常比例大于阈值0.2,使Sentinel实现熔断降级
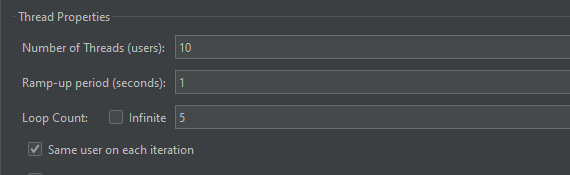
浏览器测试效果
jmeter开启期间,服务被熔断,提示被sentinel限流
jmeter关闭,未满足sentinel异常比例降级条件,显示原生的除0异常
根据异常数判断服务降级
可以应用于用户密码错误五次以上等待一段时间
当资源近一分钟的异常数超过阈值后会进行熔断,由于统计时间窗口是分钟级别,若熔断时间窗口小于60s,结束熔断状态后仍然可能直接再进入熔断状态
控制器方法
xxxxxxxxxx("/test5")public String test5(){log.info("test5 测试分钟异常数");int age = 10/0;return "------test5 测试分钟异常数";}sentinel降级策略设置
最好设置时间窗口大于一分钟,避免时间窗口小于一分钟再次点击再次触发熔断
近一分钟内该资源的异常数大于5次【一定是大于】触发服务降级进入熔断状态,熔断时间窗口为1分钟零1s【经过测试,第六次才进入服务降级】

测试
浏览器依次对
sentinel/test5发起六次访问,观察第六次的服务降级效果
Sentinel热点
热点规则仅支持QPS,因为热点对应的就是访问量
热点:即经常访问的数据,很多时候我们希望统计或者限制某个热点数据中访问频次最高的TopN数据,并对其访问进行限流或者其它操作
官网:https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81
热点限流的源码:
com.alibaba.csp.sentinel.slots.block.BlockException
热点规则示例
对控制器方法的指定参数的QPS进行约束,对带指定参数的请求数量超过阈值直接报错,在没有指定自定义降级方法的前提下直接显示原生错误,通过@SentinelResource注解可以指定超过阈值采用对应的降级方法
限流后sentinel系统默认的提示:
Blocked by Sentinel (flow limiting)在sentinel中使用@SentinelResource注解来找到对应的自定义兜底降级方法
热点降级策略
各个降级策略都用同一套规则,即对第一个参数的QPS限制每秒阈值为1,时间窗口为3s,除了value值其他都相同
表示只对第一个参数的访问量进行控制,对其他参数无论访问量是多少,都不会进行限流熔断或者服务降级
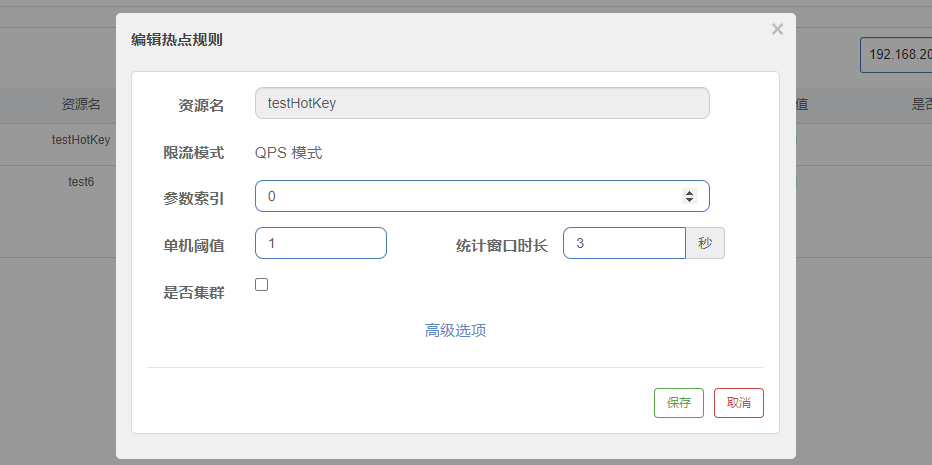
【热点规则参数简介】
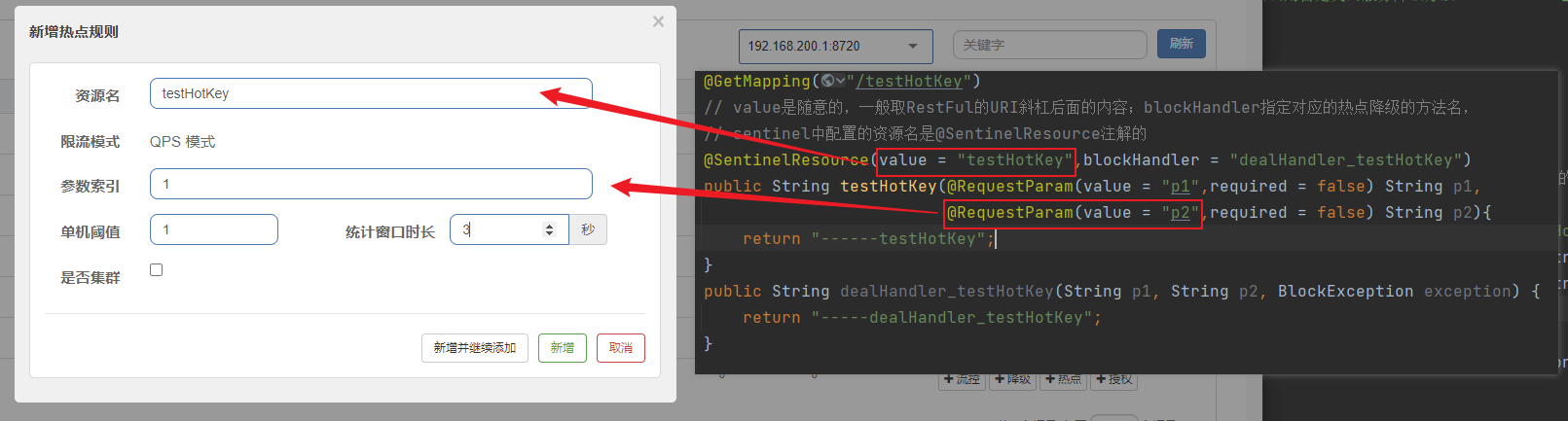
控制器方法+兜底方法
设置不同的value对应不同的@SentinelResource,可以绑定相同的降级服务方法,value看做当前控制器方法对应降级服务的唯一标识,
但是一旦热更新重启以后,热点降级的规则还在,即对某个参数的访问量超过阈值还是会报错,但是此时找不到对应的降级方法,即便代码是完全正确的【需要完全将项目】
不同value值对应同一个降级方法
xxxxxxxxxx/*** @param p1* @param p2* @return {@link String }* @描述 不满足该控制器的sentinel热点规则熔断以后调用自定义的服务降级方法dealHandler_testHotKey* @author Earl* @version 1.0.0* @创建日期 2023/11/21* @since 1.0.0*/("/testHotKey")// value是随意的,一般取RestFul的URI斜杠后面的内容;blockHandler指定对应的热点降级的方法名,// sentinel中配置的资源名是@SentinelResource注解的//只要重启就噶(value = "testHotKey",blockHandler = "dealHandler_testHotKey")public String testHotKey((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "------testHotKey";}public String dealHandler_testHotKey(String p1,String p2,BlockException exception) {return "-----dealHandler_testHotKey";}("/test6")(value = "test6", blockHandler = "dealHandler_testHotKey")public String test6((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "----test6";}public String dealHandler_test6(String p1, String p2, BlockException exception) {return "-----dealHandler_test6";}测试效果
不同的value值能完全显示在对应的控制器方法下,且能调用同一个降级方法
对一个热点降级规则指定后另一个热点降级规则会用之前的参数自动生成
相同value值对应相同的控制器方法
经过测试两个控制器方法的@SentinelResource注解中的value值也可以相同,虽然在sentinel控制台上只会显示第一个指定该value值的控制器方法的降级方法,但是效果是完全可行的
xxxxxxxxxx("/testHotKey")// value是随意的,一般取RestFul的URI斜杠后面的内容;这个value会在sentinel控制台作为控制器方法的下级簇点,// blockHandler指定对应的热点降级的方法名,sentinel中配置的资源名是@SentinelResource注解的//只要热部署重启就噶,需要完全关闭并等待sentinel控制台刷新重新配置才有效,否则热点降级规则有效,但是降级方法找不着(value = "testHotKey",blockHandler = "dealHandler_testHotKey")public String testHotKey((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "------testHotKey";}public String dealHandler_testHotKey(String p1,String p2,BlockException exception) {return "-----dealHandler_testHotKey";}("/test6")(value = "testHotKey", blockHandler = "dealHandler_testHotKey")public String test6((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "----test6";}测试效果
test6方法不显示对应的降级方法,但是只设置testHotKey降级服务的第1个参数的QPS超阈值规则,两个方法都会同时生效
不同value值对应不同的控制器方法
xxxxxxxxxx("/testHotKey")// value是随意的,一般取RestFul的URI斜杠后面的内容;这个value会在sentinel控制台作为控制器方法的下级簇点,// blockHandler指定对应的热点降级的方法名,sentinel中配置的资源名是@SentinelResource注解的//只要热部署重启就噶,需要完全关闭并等待sentinel控制台刷新重新配置才有效,否则热点降级规则有效,但是降级方法找不着(value = "testHotKey",blockHandler = "dealHandler_testHotKey")public String testHotKey((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "------testHotKey";}public String dealHandler_testHotKey(String p1,String p2,BlockException exception) {return "-----dealHandler_testHotKey";}("/test6")(value = "test6", blockHandler = "dealHandler_test6")public String test6((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "----test6";}public String dealHandler_test6(String p1, String p2, BlockException exception) {return "-----dealHandler_test6";}测试效果
对一个热点降级规则指定后,另一个热点降级规则不会用之前的参数自动生成
不指定兜底方法的热点规则
【控制器方法】
xxxxxxxxxx("/test6")public String test6((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "----test6";}【热点规则配置】
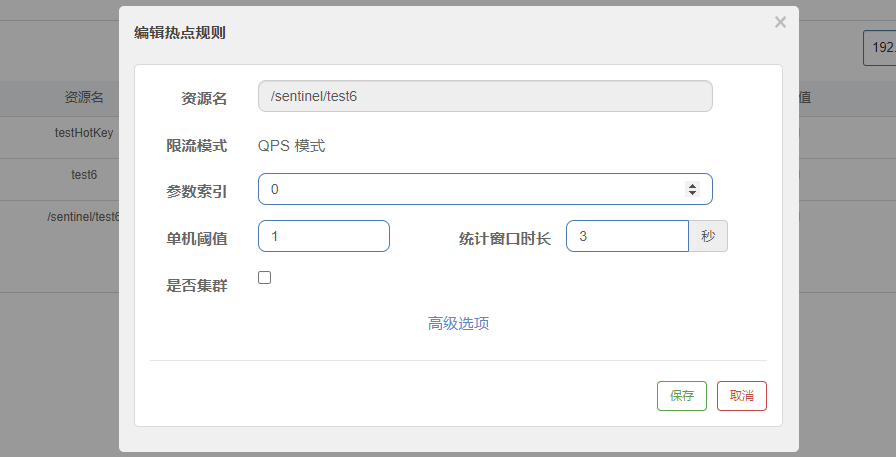
【测试效果】
配置的热点降级规则根本就不会生效,也不会发生熔断限流并且产生错误页或者提示效果
指定兜底方法并对控制器方法指定热点规则
【控制器方法】
xxxxxxxxxx("/testHotKey")// value是随意的,一般取RestFul的URI斜杠后面的内容;这个value会在sentinel控制台作为控制器方法的下级簇点,// blockHandler指定对应的热点降级的方法名,sentinel中配置的资源名是@SentinelResource注解的//只要热部署重启就噶,需要完全关闭并等待sentinel控制台刷新重新配置才有效,否则热点降级规则有效,但是降级方法找不着(value = "testHotKey",blockHandler = "dealHandler_testHotKey")public String testHotKey((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "------testHotKey";}public String dealHandler_testHotKey(String p1,String p2,BlockException exception) {return "-----dealHandler_testHotKey";}("/test6")(value = "test6", blockHandler = "dealHandler_test6")public String test6((value = "p1",required = false) String p1,(value = "p2",required = false) String p2){return "----test6";}public String dealHandler_test6(String p1, String p2, BlockException exception) {return "-----dealHandler_test6";}【热点规则配置】
只配置带兜底方法的控制器方法
【测试效果】
生成所有的@SentinelResource注解的value对应的热点规则,使用当前控制器热点规则的参数
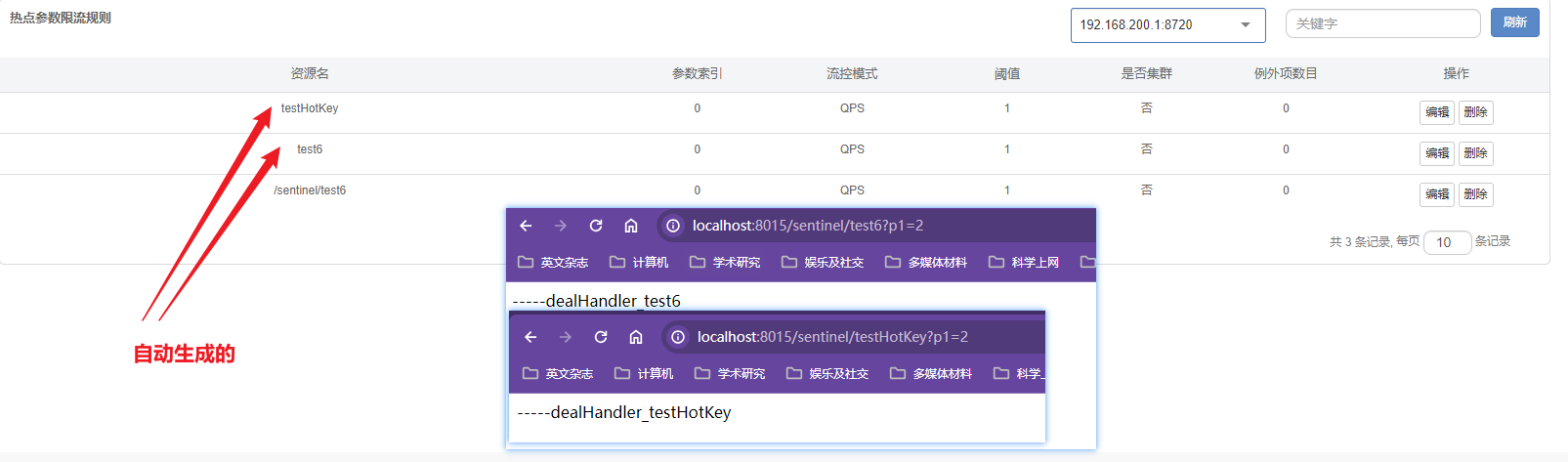
总结
这些教程根本就没讲,以下针对sentinel1.7.0,感觉sentinel还很不稳定,存在很多问题
不要对没有@SentinelResource注解标注的控制器方法指定热点策略,对控制器方法指定热点策略且控制器方法没有配置@SentinelResource注解,热点规则根本不会生效,
可以对@SentinelResource注解的value指定对应的热点策略【不是对控制器方法,而是控制器方法的@SentinelResource注解的value】,这样指定使用相同降级方法的value也会使用相同的参数创建对应热点策略;
也可以对标注了@SentinelResource注解的控制器方法指定热点规则,此时会用指定的参数对所有的@SentinelResource的value和当前控制器方法都生成对应的热点策略
在热点降级下使用热部署,项目重启以后,服务列表和降级规则都在,此时热点规则仍然可用,但是找不到自定义的服务降级方法,会显示默认的错误页,删了热点降级规则重新创建还是一样的效果;需要完全把项目停掉,刷新sentinel控制台没有对应的规则和服务列表,重启项目重新配置才能生效
不同的控制器方法可以通过@SentinelResource注解指定对应的热点服务降级自定义方法,其中value和blockHandler可以完全相同,不影响降级规则和降级方法的调用
value值相同的时候,会导致簇点的控制条列表显示出问题,而且相同value不同降级方法没测试过,这种写法有点憨,但是使用没有问题
value不同,但是降级方法是一样的,生成一个控制器方法的降级方法的热点策略会自动生产和该降级方法关联的控制器方法的热点降级策略
value值和降级方法都不同,此时需要挨个指定对应value的资源的降级规则
参数例外项
普通参数的热点条件是不论参数值是多少,只要带该参数的请求访问次数达到阈值,就会触发服务降级报错或者执行自定义降级方法
现在有需求:当指定热点参数的值为某个特定值的时候,开发人员希望带该参数值的请求次数的阈值能提升到500,即假如p1不等于5限流阈值为1,当p1=5时,限流阈值为3或者不被限流
可以添加多个指定参数值
疑问:是特指参数值为特定值时达到500,还是一段时间内包含指定参数值的时候总请求次数达到500很难测试,根据目前的测试暂时认为是指定值的QPS达到500才会触发服务降级,而不是包含特定值在内的总请求数目达到500,使用jmeter持续发送参数为5的请求,每秒三次,使用浏览器发送参数为5的请求直接服务降级,但是参数值为2的请求不受影响,由此看出该参数例外项是针对特定参数的,不是针对总的请求次数
参数例外项只支持6种基本数据类型外加String类型的请求参数【没有short和boolean】
参数例外项设置
当第一个参数值为5时,将限流阈值提升到3,超过3次才会服务降级,等于三次不会
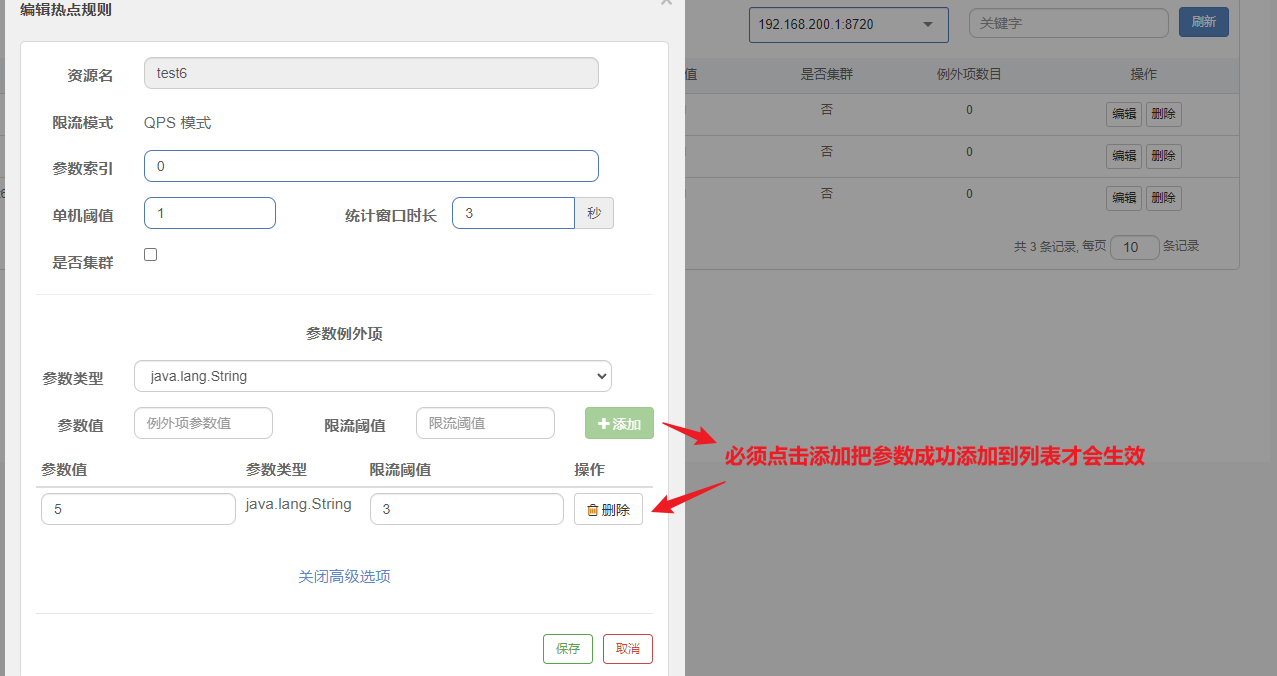
使用jmeter对参数等于5发起每秒三次请求
测试对参数等于5的请求访问是否成功,同时测试对参数等于2的情况是否访问成功
测试效果
当jmeter启动后,通过浏览器访问参数等于5直接服务降级;但是浏览器访问参数等于2的请求一切正常,第二次发生服务 降级,说明参数2的判断和参数5的判定是隔离开的;从而验证了此前访问阈值只对特定值有效的假设
如果控制器方法中存在运行时异常,@SentinelResource配置的服务降级在没有触发热点配置规则的前提下,不会触发对应的服务降级,仍然报错原生的异常信息;但是一旦触发热点配置的条件,就不会报运行时异常,仍然调用对应的服务降级方法,后台也不会打印运行时异常【可能还没执行到产生异常的地方就被拒绝了】
Sentinel系统规则
使用起来比较危险,一个指标超了,基本上系统就不能用了
Sentinel结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性【保证系统不被拖垮且在稳定的前提下,保持系统的吞吐量】。
背景
讲的都很浅显
传统系统保护的思路是根据硬指标,即系统的负载来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当load开始好转,则恢复流量的进入。这个思路给我们带来了不可避免的两个问题:
load 是一个“结果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性,当前通过率对load的影响至少要过 1 秒之后才能观测到,这样就浪费了系统的处理能力,看到的曲线也总是抖动的。
请求通过率恢复慢。下游应用不可靠导致整体的 RT【响应时间Response time】 很高,从而 load 到了一个很高的点。一段时间之后下游应用恢复了,应用 RT 也相应减少。但此时load 响应慢,根据load调整通过率,此时短时间内通过率也存在相应的延迟。
TCP BBR 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。Sentinel 在系统自适应保护的做法是,用 load1 作为启动自适应保护的因子,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(
EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。系统规则支持以下的模式:
触发系统保护感觉视频的意思是直接禁止请求访问,提示被sentinel限流
就是直接根据设定的以下五个参数阈值,超阈值直接限流任意请求
Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的
maxQps * minRt估算得出。设定参考值一般是CPU cores * 2.5。CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
演示根据应用入口QPS开启系统保护
设置根据应用入口QPS的单机阈值来触发系统保护
以下设置表示1秒整个系统只能处理一个请求,超过直接整个系统服务限流【实际上阈值为1能接收到2个】
实际上不知道是系统故意设置阈值为0系统能收到1个请求还是由于系统判定请求数并进行服务降级需要时间,基本上设置阈值为1但是每秒能收到两个请求;经过测试,设置为1确实能接收到两个请求,这不是因为执行服务降级需要时间导致的,因为设置阈值为0的时候,鼠标点击浏览器能正常显示1次;设置为1的时候,鼠标点击能正常显示两次,但是系统判断服务降级的速度肯定比我手快,由此记结论
设置每秒钟QPS阈值为n可以接收n+1个请求
在高并发的情况下,如每毫秒就有十几二十个请求,即使使用了QPS入口阈值的系统规则,仍然不能完美控制通过请求的数量,因为此时存在服务降级方法还没执行请求就已经进入系统并执行方法了,但是可以实现极大极大的拒绝高并发的请求【不设置可能每毫秒几十个请求,设置以后在阈值为1的情况下,每秒钟才接收到10个左右的请求】
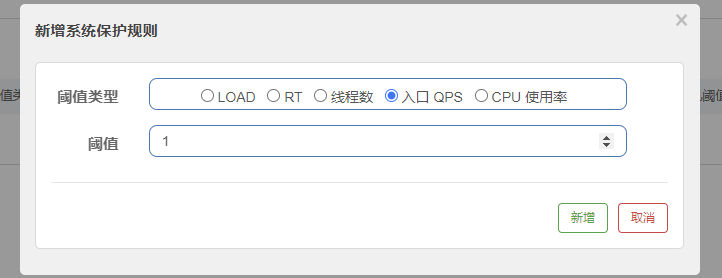
jmeter测试说明
以下jmeter的参数的意思是4秒内【第二个参数】发送4组【第三个参数】请求,每组请求发送10个
这种参数并不是完全准确的,比如两秒内发送四个请求可能两毫秒就发送完成了【可能是随机的原因】,当请求数量比较大比如几十个请求的情况下,这种情况会好很多
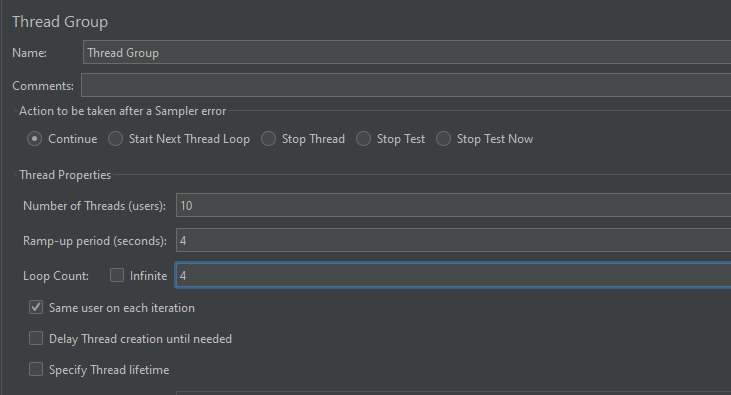
测试效果
随便一个请求,只要超过设定的入口QPS,直接所有的请求直接提示被限流
经过测试,在开启系统规则的QPS阈值情况下,设置的热点规则会全部失效,在设置阈值为1,每秒钟发起十个请求的情况下,系统仍然只能接收到2个请求
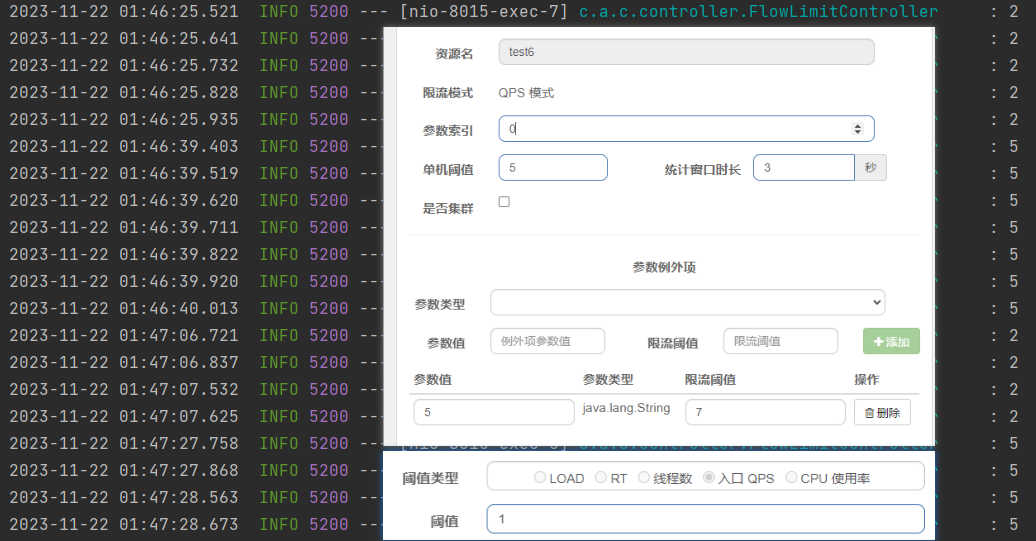
@SentinelResource注解
在模块26的基础上引入公共模块以使用统一返回格式,在该模块中添加RateLimitController来编写后续控制器方法
按value属性值配置限流
引入自定义公共模块
xxxxxxxxxx<dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency>创建控制器并编写控制器方法
控制器方法是使用@SentinelResource注解指定自定义降级方法,配置流控规则使用value的值对应的资源进行流控规则的配置
xxxxxxxxxx("/sentinel")public class RateLimitController {/*** @return {@link CommonResp }* @描述 按照@SentinelResource注解的value属性配置流控规则,使用自定义降级方法* @author Earl* @version 1.0.0* @创建日期 2023/11/22* @since 1.0.0*/("/byResource")(value = "byResource", blockHandler = "handleException")public CommonResp byResource() {return new CommonResp(200, "按资源名称限流测试OK", new Payment(2020L, "serial001"));}public CommonResp handleException(BlockException exception) {return new CommonResp(444, exception.getClass().getCanonicalName() + "\t 服务不可用");}}流控规则配置
对标注了@SentinelResource注解的控制器方法进行配置,如果该控制器方法的QPS超过配置的单机阈值1就调用自定义服务降级方法
访问对应资源超过每秒一次就限流并调用自定义的降级服务
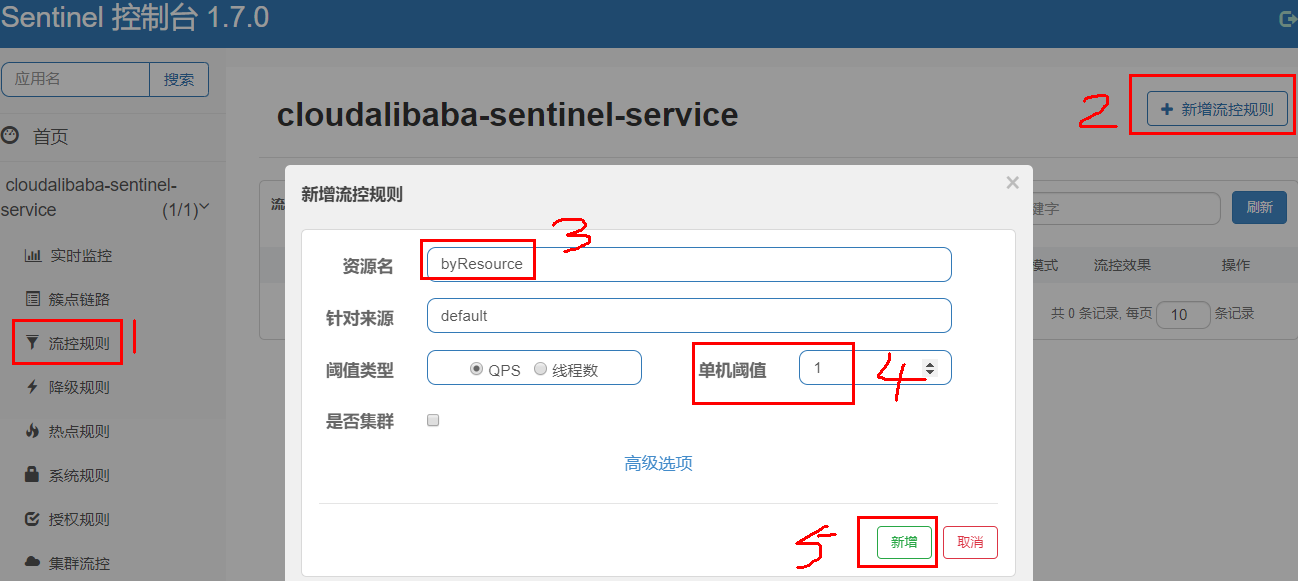
【参数说明】
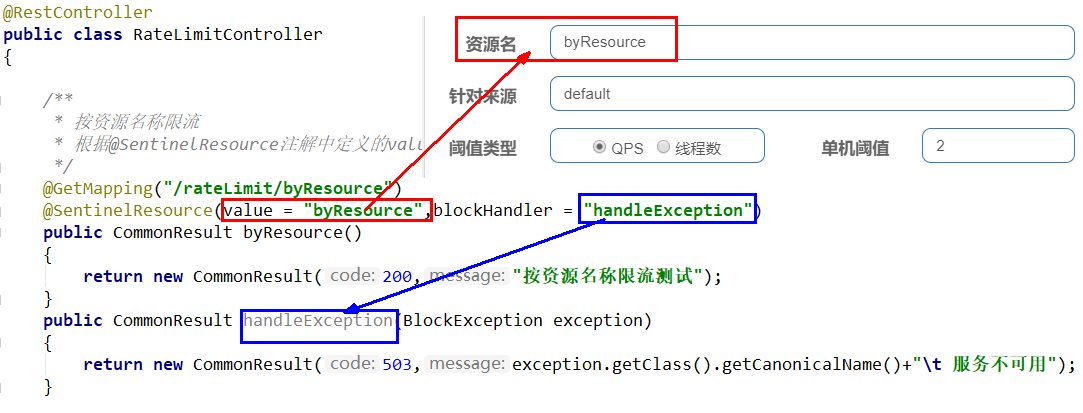
测试效果
@SentinelResource注解对控制器方法指定了value和自定义方法,对value设置流控规则对控制器方法适用,且超出阈值后会自动调用自定义的服务降级方法
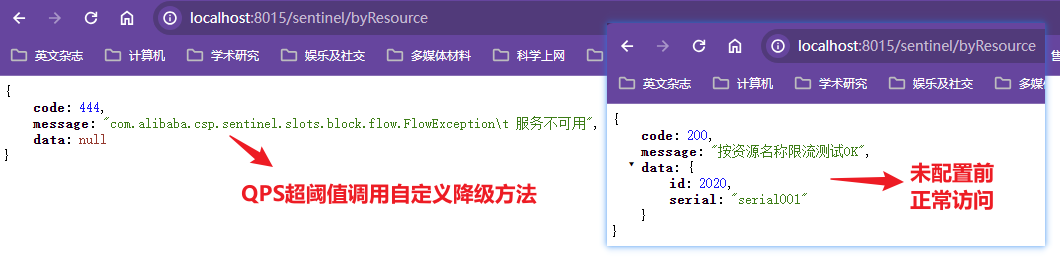
此时再次设置对控制器方法进行流控
控制器方法没有变化,仍然有@SentinelResource注解并指定了自定义降级方法
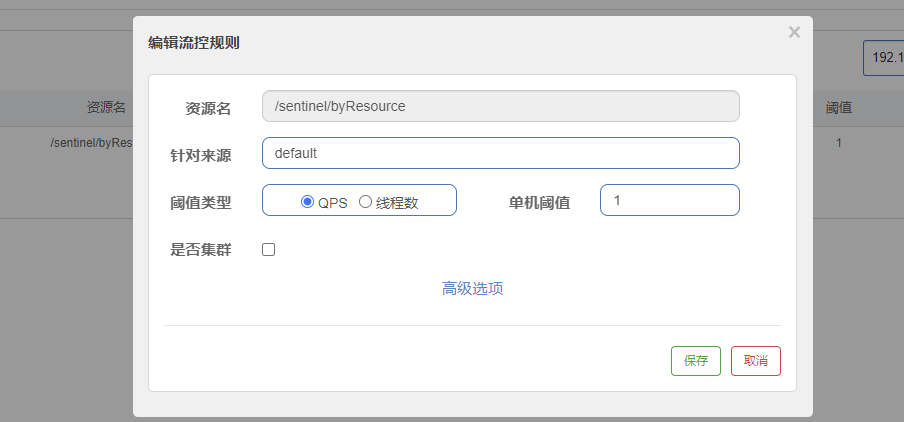
测试效果
流控规则生效,但是降级方法使用的sentinel自带的默认提示信息,没有使用@SentinelResource注解指定的降级方法
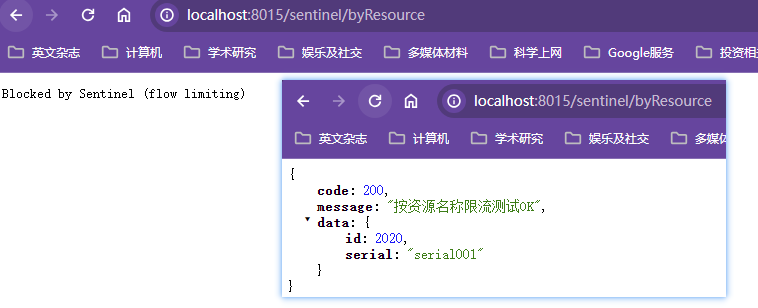
关闭服务观察流控规则列表
对应服务的流控规则消失,说明sentinel的流控配置默认是临时的,并没有持久化
按URI路径配置限流
实际上一个例子已经配置了并得出结论即使配置了@sentinelResource注解并指定了自定义配置自定义降级方法,使用URI路径配置限流仍然不会采用自定义降级方法,限流规则可用,但是调用的是sentinel默认的限流提示,【这里对于热点规则配置并不是一样的,热点规则对uri配置热点规则会直接使用参数会自动生成其上的@sentinelResource注解的value属性值对应资源热点配置,且能够直接调用对应的服务降级方法,在没有配置自定义服务降级方法时,即便配置了URI热点规则也不会生效,这是经过本人验证的,但是视频无论此处还是热点规则都没有讲】但是还是要走一遍流程
控制器方法
使用了@SentinelResource(value = "byUrl")注解但是没有指定对应的自定义降级方法,即便指定了,对URI配置流控规则也不会生效
xxxxxxxxxx("/rateLimit/byUrl")(value = "byUrl")public CommonResp byUrl() {return new CommonResp(200, "按url限流测试OK", new Payment(2020L, "serial002"));}流控配置
没有对@SentinelResource注解的value属性值生成流控规则
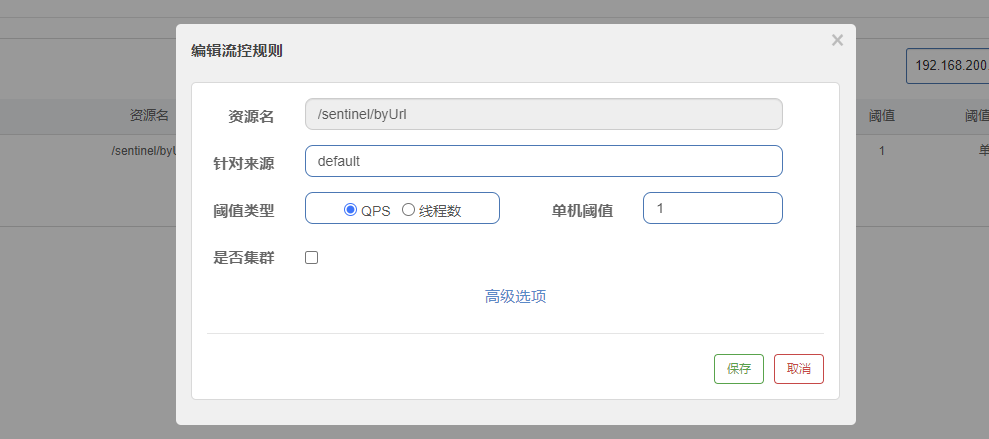
效果
采用默认的限流提示信息
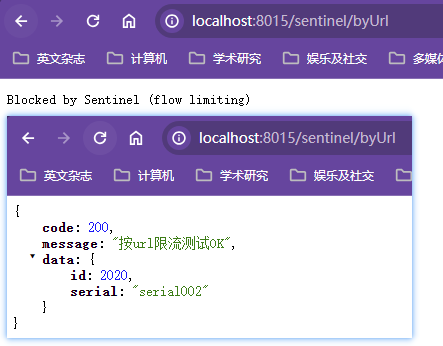
自定义限流处理逻辑
到此Sentinel存在以下问题:
系统默认的,没有体现我们自己的业务要求
依照现有条件,我们自定义的处理方法又和业务代码耦合在一块,不直观。
每个业务方法都添加一个兜底的,那代码膨胀加剧。【其实这个问题很难说,因为降级方法可以被重复调用,顶多说没有配置降级方法的会自动调用全局的降级方法】
全局统一的处理方法没有体现。
自定义限流处理逻辑
其实就是把自定义方法放在CustomerBlockHandler,并且通过指定类名和方法名对降级方法进行静态方法调用
创建CustomerBlockHandler类用于自定义限流处理逻辑,这里面指定全局的用户自定义降级静态方法,方法必须添加static关键字,认为sentinel是通过静态方法调用即类名调用,且返回值类型需要和调用方法的返回值类型相同
这个名字是自定义的,方法相比于原来的参数多了一个BlockException用于sentinel传参
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 sentinel的全局限流服务自定义降级处理类* @创建日期 2023/11/22* @since 1.0.0*/public class CustomerBlockHandler {public static CommonResp handleException(BlockException exception) {return new CommonResp(2020, "自定义的限流处理信息......CustomerBlockHandler");}}控制器方法
xxxxxxxxxx/*** @return {@link CommonResp }* @描述 自定义通用的限流处理逻辑* 自定义通用的限流处理逻辑,* blockHandlerClass = CustomerBlockHandler.class* blockHandler = handleException* 上述配置:找CustomerBlockHandler类里的handleException方法进行兜底处理* @author Earl* @version 1.0.0* @创建日期 2023/11/22* @since 1.0.0*/("/customerBlockHandler")(value = "customerBlockHandler",blockHandlerClass = CustomerBlockHandler.class, blockHandler = "handleException")public CommonResp customerBlockHandler() {return new CommonResp(200, "按客户自定义限流处理逻辑");}流控配置以及测试效果
这就只是把处理方法提取出来放在一个类中,通过静态方法调用实现,没有解决根本问题,

注解的属性介绍
注意:注解方式埋点不支持 private 方法。
@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项。 @SentinelResource 注解包含以下属性:
value:资源名称,必需项(不能为空)entryType:entry 类型,可选项(默认为EntryType.OUT)blockHandler/blockHandlerClass:blockHandler对应处理BlockException的函数名称,可选项。blockHandler 函数访问范围需要是
public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为BlockException。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
blockHandlerClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
【以下在服务熔断讲】
fallback/fallbackClass:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了exceptionsToIgnore里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:返回值类型必须与原函数返回值类型一致;
方法参数列表需要和原函数一致,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。1.6.0 之前的版本 fallback 函数只针对降级异常(
DegradeException)进行处理,不能针对业务异常进行处理。
defaultFallback(since 1.6.0):默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)默认 fallback 函数可以针对所有类型的异常(除了
exceptionsToIgnore里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。defaultFallback 函数签名要求:返回值类型必须与原函数返回值类型一致;
方法参数列表需要为空,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。exceptionsToIgnore(since 1.6.0):用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。
1.8.0 版本开始,
defaultFallback支持在类级别进行配置。
注:特别地,若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出
BlockException时只会进入blockHandler处理逻辑。若未配置blockHandler、fallback和defaultFallback,则被限流降级时会将BlockException直接抛出(若方法本身未定义 throws BlockException 则会被 JVM 包装一层UndeclaredThrowableException)。
服务熔断
测试环境搭建
测试环境搭建
sentinel整合ribbon和openFeign实现服务熔断,创建三个模块,一个消费者,两个生产者
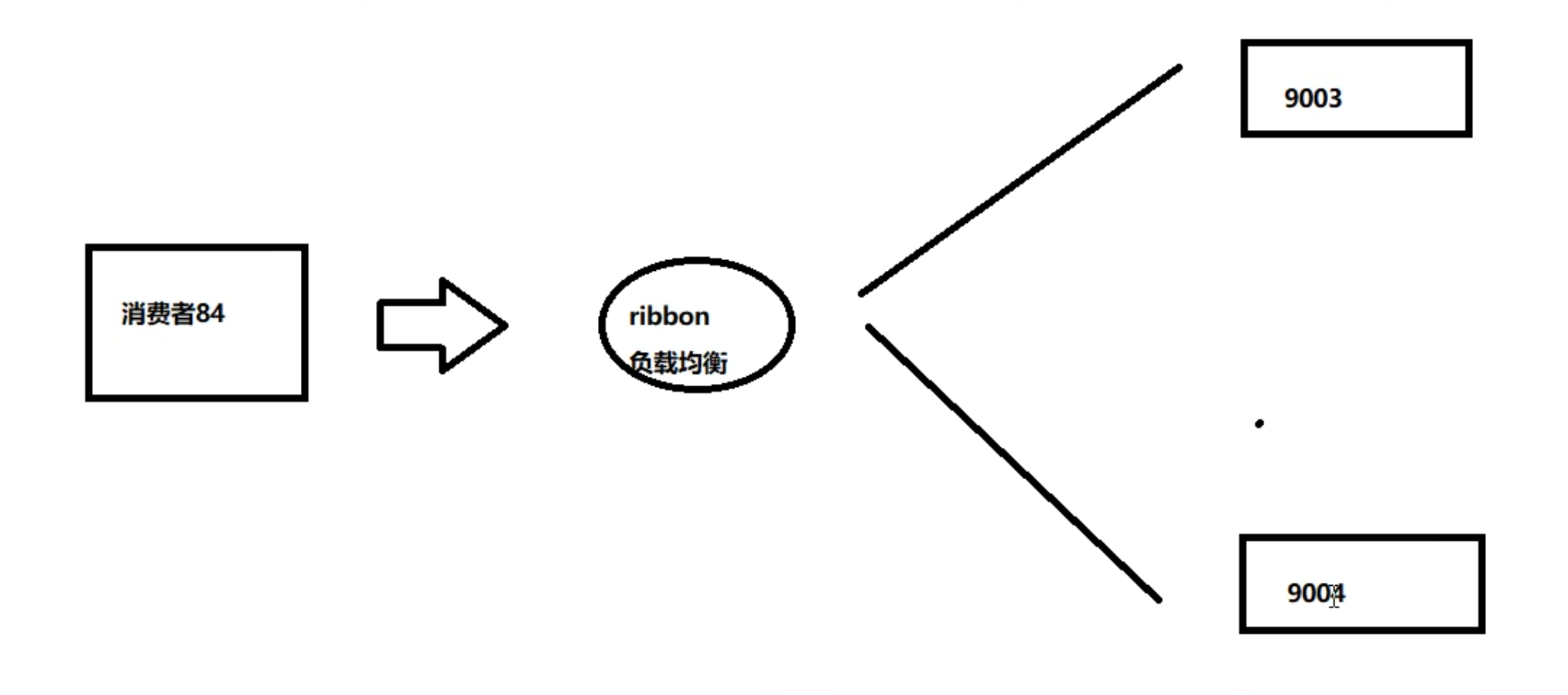
搭建27、28模块
作为生产者
pom.xml
xxxxxxxxxx<dependencies><!--SpringCloud ailibaba nacos --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--日常通用jar包配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
将两个模块的端口号修改成不同的端口号
xxxxxxxxxxserverport8016springapplicationnamenacos-payment-providercloudnacosdiscoveryserver-addrlocalhost8848 #配置Nacos地址managementendpointswebexposureinclude'*'启动类
xxxxxxxxxxpublic class PaymentApplication {public static void main(String[] args) {SpringApplication.run(PaymentApplication.class, args);}}控制器方法
将数据提前放入HashMap中模拟从数据库取值
xxxxxxxxxxpublic class PaymentController {("${server.port}")private String serverPort;public static HashMap<Long, Payment> hashMap = new HashMap<>();static {hashMap.put(1L, new Payment(1L, "28a8c1e3bc2742d8848569891fb42181"));hashMap.put(2L, new Payment(2L, "bba8c1e3bc2742d8848569891ac32182"));hashMap.put(3L, new Payment(3L, "6ua8c1e3bc2742d8848569891xt92183"));}(value = "/paymentSQL/{id}")public CommonResp<Payment> paymentSQL(("id") Long id) {Payment payment = hashMap.get(id);CommonResp<Payment> result = new CommonResp(200, "from mysql,serverPort: " + serverPort, payment);return result;}}
搭建29消费者模块
通过消费者调用生产者
pom.xml
xxxxxxxxxx<dependencies><!--SpringCloud ailibaba nacos --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--SpringCloud ailibaba sentinel --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId></dependency><!--SpringCloud openfeign --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!-- 引入自己定义的api通用包,可以使用Payment支付Entity --><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><!-- SpringBoot整合Web组件 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--日常通用jar包配置--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies>application.yml
xxxxxxxxxxserverport80springapplicationnamesentinel-order-consumercloudnacosdiscovery#Nacos服务注册中心地址server-addrlocalhost8848sentineltransport#配置Sentinel dashboard地址dashboardlocalhost8080#默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口port8719managementendpointswebexposureinclude'*'# 激活Sentinel对Feign的支持feignsentinelenabledtrue启动类
xxxxxxxxxxpublic class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}}控制器方法
xxxxxxxxxxpublic class CircleBreakerController {public static final String SERVICE_URL = "http://nacos-payment-provider";private RestTemplate restTemplate;("/consumer/fallback/{id}")//@SentinelResource(value = "fallback") //没有配置//@SentinelResource(value = "fallback",fallback = "handlerFallback") //fallback只负责业务异常//@SentinelResource(value = "fallback",blockHandler = "blockHandler") //blockHandler只负责sentinel控制台配置违规(value = "fallback", fallback = "handlerFallback", blockHandler = "blockHandler",exceptionsToIgnore = {IllegalArgumentException.class})public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}//本例是fallbackpublic CommonResp handlerFallback( Long id, Throwable e) {Payment payment = new Payment(id, "null");return new CommonResp<>(444, "兜底异常handlerFallback,exception内容 " + e.getMessage(), payment);}//本例是blockHandlerpublic CommonResp blockHandler( Long id, BlockException blockException) {Payment payment = new Payment(id, "null");return new CommonResp<>(445, "blockHandler-sentinel限流,无此流水: blockException " + blockException.getMessage(), payment);}//==================OpenFeignprivate PaymentClient paymentClient;(value = "/consumer/openfeign/{id}")public CommonResp<Payment> paymentSQL(("id") Long id) {if (id == 4) {throw new RuntimeException("没有该id");}return paymentClient.paymentSQL(id);}}FeignClient调用类
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 使用 fallback 方式是无法获取异常信息的,如果想要获取异常信息,可以使用 fallbackFactory参数* @创建日期 2023/11/22* @since 1.0.0*/(value = "nacos-payment-provider", fallback = PaymentFallback.class)//调用中关闭9003服务提供者public interface PaymentClient {(value = "/paymentSQL/{id}")public CommonResp<Payment> paymentSQL(("id") Long id);}FeignClient调用类的fallback
xxxxxxxxxxpublic class PaymentFallback implements PaymentClient {public CommonResp<Payment> paymentSQL(Long id) {return new CommonResp<>(444, "服务降级返回,没有该流水信息", new Payment(id, "errorSerial......"));}}RestTemplate配置类
xxxxxxxxxxpublic class ApplicationContextConfig {/*** @return {@link RestTemplate }* @描述 注入RestTemplate对象* @author Earl* @version 1.0.0* @创建日期 2023/10/20* @since 1.0.0*/public RestTemplate getRestTemplate(){return new RestTemplate();}}
环境测试
消费者29模块向生产者28、27发起服务调用,使用ribbon进行负载均衡
使用了默认的轮询负载均衡策略
【openfeign调用】
【RestTemplate调用】
熔断测试
使用RestTemplate和Ribbon实现服务调用情况下的运行时异常的前台信息提示
没有配置服务降级情况下程序异常前端信息显示
对应控制器方法
@SentinelResource(value = "fallback") 注解没有配置对应的发生异常的降级方法
xxxxxxxxxx("/consumer/fallback/{id}")(value = "fallback") //没有配置public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}异常发生效果
未配置降级方法下的异常,用户体验很不好
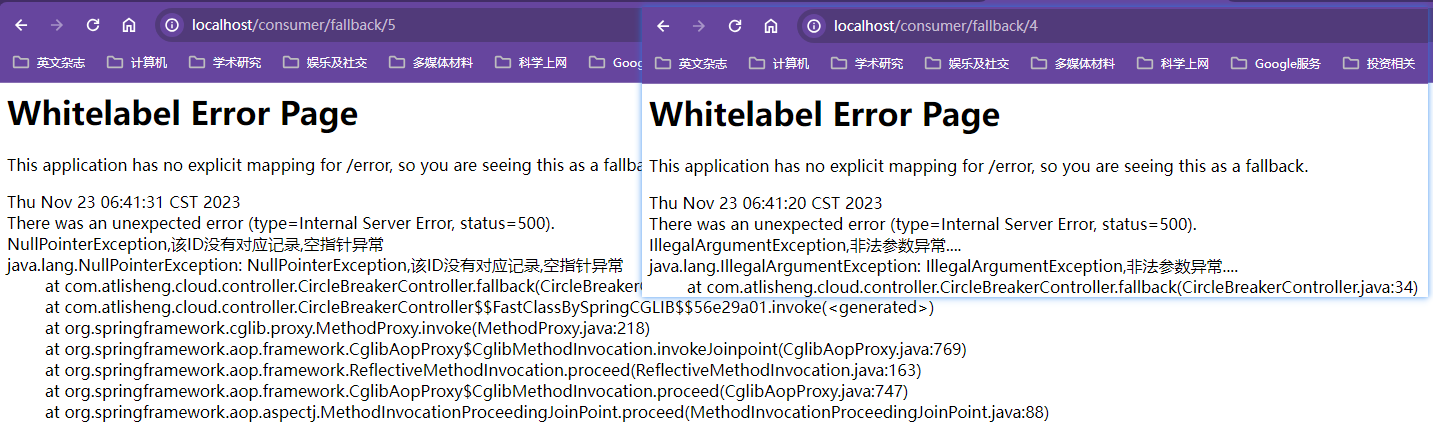
使用fallback属性添加用户自定义运行异常降级方法
fallback可以在程序发生运行时异常的时候自动调用对应的降级服务来给前台展示友好的用户提示界面,只负责业务异常,?是否还能负责sentinel的流控限制提示呢?【这里演示了对sentinel的限流规则服务降级用
blockHandler属性指定,所以暂且认为falloback不能处理sentinel限流规则的服务降级】fallback/fallbackClass:fallback 函数名称,可选项,用于在抛出异常的时候提供 fallback 处理逻辑。fallback 函数可以针对所有类型的异常(除了exceptionsToIgnore里面排除掉的异常类型)进行处理。fallback 函数签名和位置要求:返回值类型必须与原函数返回值类型一致;
方法参数列表需要和原函数一致,或者可以额外多一个
Throwable类型的参数用于接收对应的异常。fallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
fallbackClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。1.6.0 之前的版本 fallback 函数只针对降级异常(
DegradeException)进行处理,不能针对业务异常进行处理。
对应控制器方法
xxxxxxxxxx("/consumer/fallback/{id}")(value = "fallback",fallback = "handlerFallback") //fallback只负责业务异常public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}//本例是fallbackpublic CommonResp handlerFallback( Long id, Throwable e) {Payment payment = new Payment(id, "null");return new CommonResp<>(444, "兜底异常handlerFallback,exception内容 " + e.getMessage(), payment);}异常发生效果
发生异常自动调用
@SentinelResource(value = "fallback",fallback = "handlerFallback")注解中指定的handlerFallback降级方法,该方法的第二个参数为正常服务发生的异常,可以打印异常信息,注意此时后台执行了降级方法,不会再在控制台打印错误堆栈信息了比原生的errorPage友好而且还可以返回一个对应错误码的错误页面回去
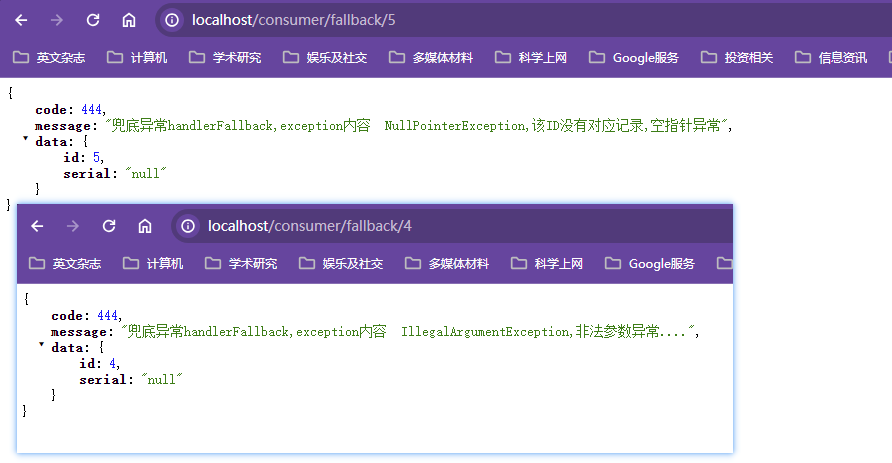
注意:在只配置了fallback服务降级的情况下,sentinel控制违规和运行时异常都走的是fallback的服务降级
下图为只配置了fallback属性,没有配置blockHandler属性,sentinel控制规则违背且未发生运行时异常的效果
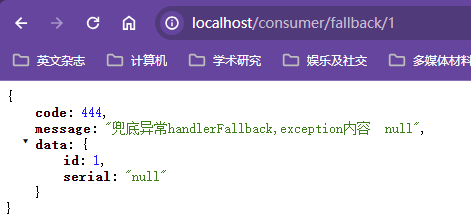
使用
blockHandler属性添加用户自定义资源限流降级方法blockHandler/blockHandlerClass:blockHandler对应处理BlockException的函数名称,可选项。blockHandler 函数访问范围需要是
public,返回类型需要与原方法相匹配,参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为BlockException,可以从这里面获取限流的信息。blockHandler 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定
blockHandlerClass为对应的类的Class对象,注意对应的函数必需为 static 函数,否则无法解析。
对应控制器方法
xxxxxxxxxx("/consumer/fallback/{id}")(value = "fallback",blockHandler = "blockHandler") //blockHandler只负责sentinel控制台配置违规public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}//本例是blockHandlerpublic CommonResp blockHandler( Long id, BlockException blockException) {Payment payment = new Payment(id, "null");return new CommonResp<>(445, "blockHandler-sentinel限流,无此流水: blockException " + blockException.getMessage(), payment);}sentinel限流规则设置
表示控制器方法一分钟内发生两次异常以上,就触发资源限流,当配置了自定义降级方法,就调用用户自己的降级服务
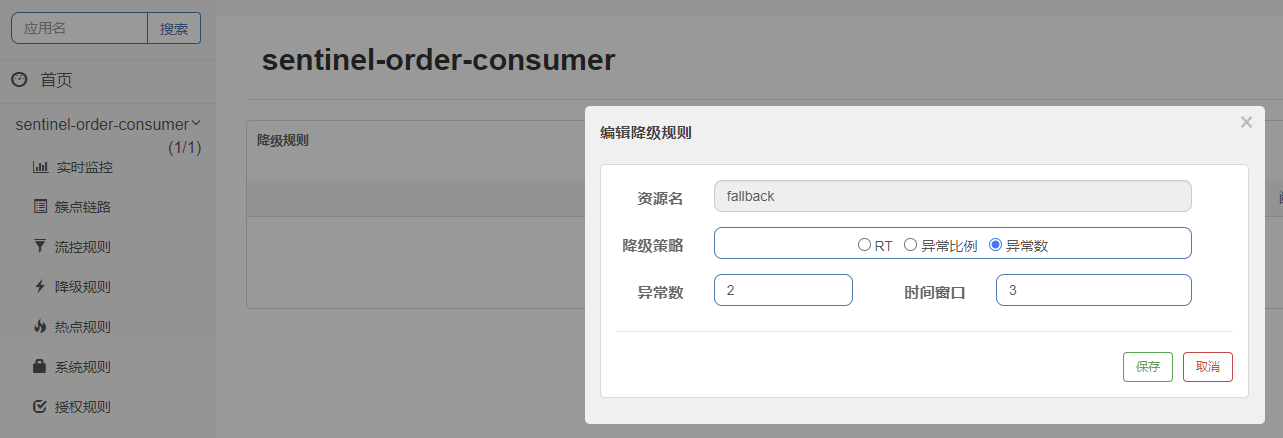
流控效果
第一次点击,因为
blockHandler配置的服务降级不负责运行时异常的降级方法,而且没有配置fallback属性,没有违背流控规则,因此展示原生不友好的错误页;第三次点击违背了流控规则,直接调用
blockHandler配置的资源限流降级方法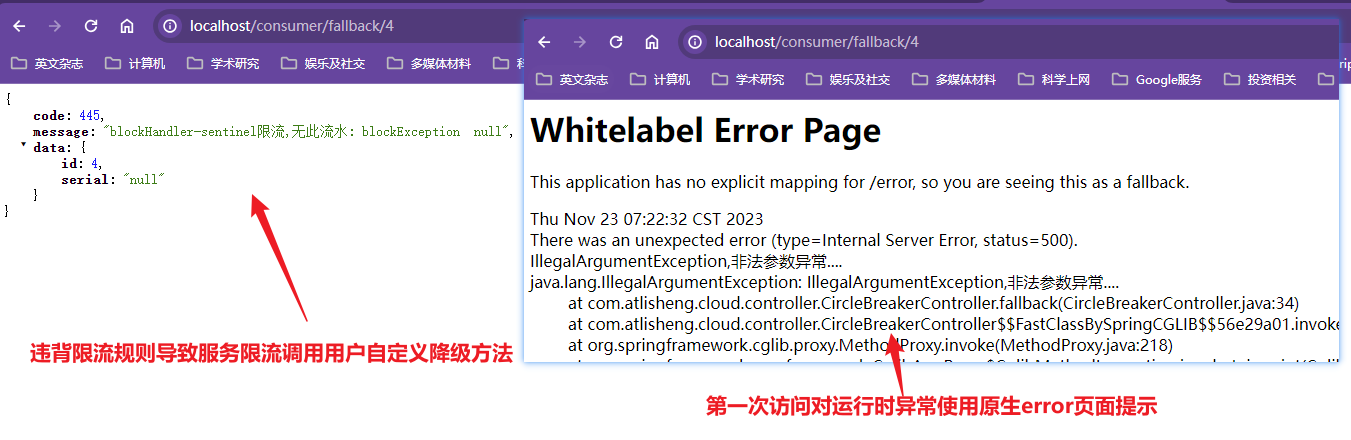
同时配置
fallback属性和blockhandler属性对应控制器方法
xxxxxxxxxx("/consumer/fallback/{id}")(value = "fallback", fallback = "handlerFallback", blockHandler = "blockHandler")public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}//本例是fallbackpublic CommonResp handlerFallback( Long id, Throwable e) {Payment payment = new Payment(id, "null");return new CommonResp<>(444, "兜底异常handlerFallback,exception内容 " + e.getMessage(), payment);}//本例是blockHandlerpublic CommonResp blockHandler( Long id, BlockException blockException) {Payment payment = new Payment(id, "null");return new CommonResp<>(445, "blockHandler-sentinel限流,无此流水: blockException " + blockException.getMessage(), payment);}流控规则
同时可能存在运行时异常和sentinel控制的违规情况,配置sentinel对资源的QPS限制每秒一次
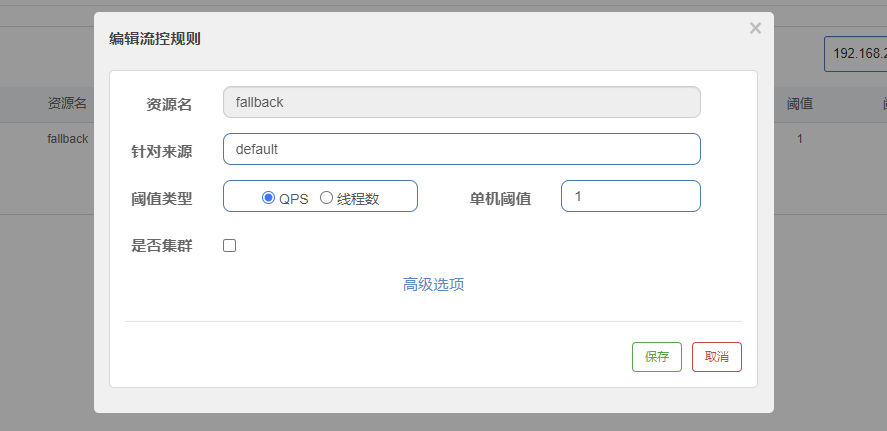
测试效果
sentinel控制违规时
blockhandler起作用进行服务降级;当sentinel控制没有违规,但是发生运行时异常fallback正常生效;当sentinel控制违规且会发生运行时blockhandler生效,其实就是违规了根本不会执行正常处理的方法【流控服务降级还要执行正常的方法那流控就不起作用了】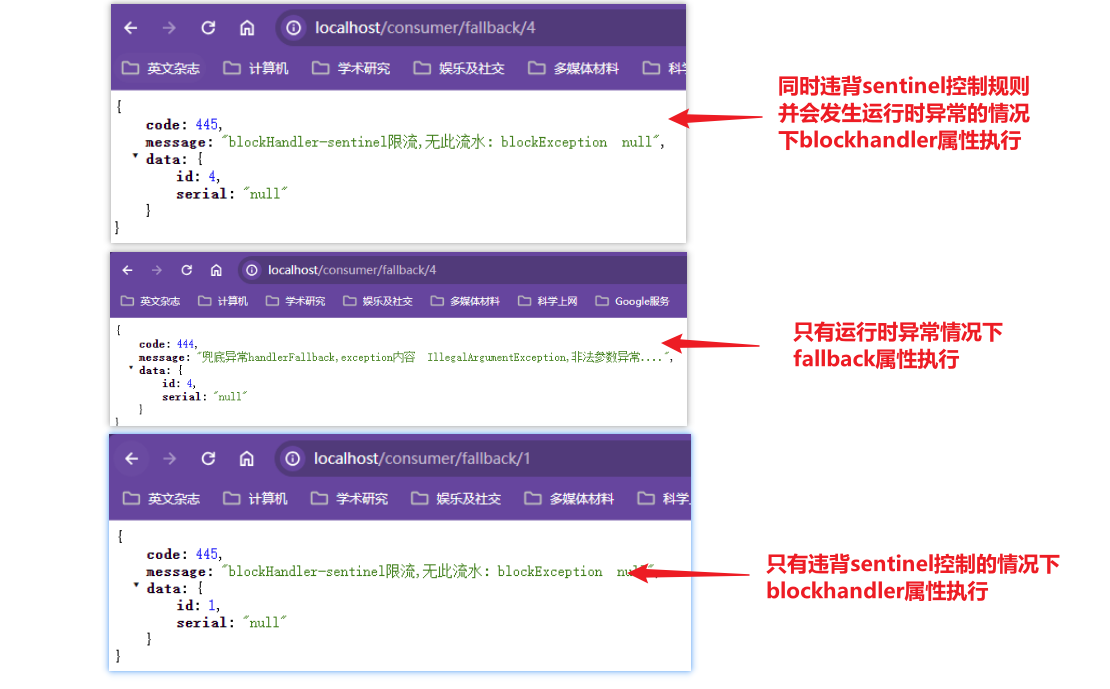
用
exceptionsToIgnore属性配置对指定运行时异常的降级方法忽略加入报
exceptionsToIgnore指定的异常,不再有fallback方法兜底,没有降级效果对应控制器方法
当参数为4抛出的异常不再进行服务降级,不为1234的情况下抛出的异常会被服务降级
xxxxxxxxxx("/consumer/fallback/{id}")(value = "fallback", fallback = "handlerFallback", blockHandler = "blockHandler",exceptionsToIgnore = {IllegalArgumentException.class})public CommonResp<Payment> fallback( Long id) {CommonResp<Payment> result = restTemplate.getForObject(SERVICE_URL + "/paymentSQL/" + id, CommonResp.class, id);if (id == 4) {throw new IllegalArgumentException("IllegalArgumentException,非法参数异常....");} else if (result.getData() == null) {throw new NullPointerException("NullPointerException,该ID没有对应记录,空指针异常");}return result;}//本例是fallbackpublic CommonResp handlerFallback( Long id, Throwable e) {Payment payment = new Payment(id, "null");return new CommonResp<>(444, "兜底异常handlerFallback,exception内容 " + e.getMessage(), payment);}测试效果
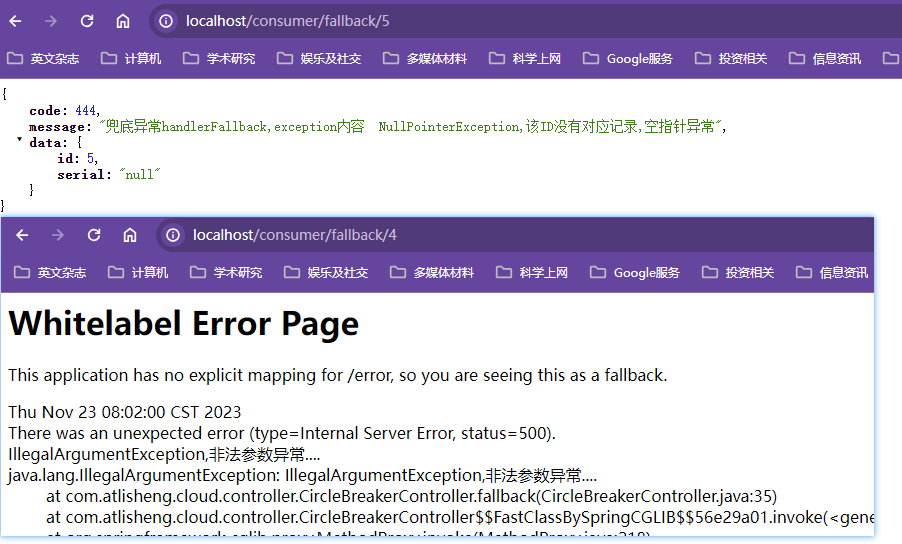
OpenFeign整合Sentinel
引入OpenFeign依赖
xxxxxxxxxx<!--SpringCloud openfeign --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency>在配置文件中激活sentinel对feign的支持
xxxxxxxxxx# 激活Sentinel对Feign的支持feignsentinelenabledtrue启动类上添加@EnableFeignClients启动Feign的服务调用功能
xxxxxxxxxx//启动Feign的服务调用功能public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}}正常写带
@FeignClient注解的业务调用接口xxxxxxxxxx(value = "sentinel-payment-provider", fallback = PaymentFallback.class)//调用中关闭9003服务提供者public interface PaymentClient {(value = "/paymentSQL/{id}")public CommonResp<Payment> paymentSQL(("id") Long id);}服务调用接口降级实现类
xxxxxxxxxxpublic class PaymentFallback implements PaymentClient {public CommonResp<Payment> paymentSQL(Long id) {return new CommonResp<>(444, "服务降级返回,没有该流水信息", new Payment(id, "errorSerial......"));}}控制器方法
xxxxxxxxxxprivate PaymentClient paymentClient;(value = "/consumer/openfeign/{id}")(value = "fallback", fallback = "handlerFallback", blockHandler = "blockHandler")public CommonResp<Payment> paymentSQL(("id") Long id) {if (id == 4) {throw new RuntimeException("没有该id");}return paymentClient.paymentSQL(id);}测试效果
这里教程试图用sentinel来解释调用服务挂掉,由sentinel负责服务调用失败的服务降级,因此开启sentinel对feign的支持,然而这里实际上用的明明是openFeign本身自带的hystrix进行的服务降级处理啊,没和Sentinel配合使用【要确认一下开启sentinel对feign的支持的实际作用,经过验证,教程是对的】
正常的资源sentinel控制就和正常的一样操作不就行了吗?
经过查询博客,了解到
feign.sentinel.enabled=true作为Feign.Builder组件的自动配置条件,会在其中创建一个继承了InvocationHandler的SentinelInvocationHandler对象,这个对象会获取FeignClient接口对应的服务降级fallback【不敢确定】,所以说,添加了feign.sentinel.enabled=trueFeignClient的服务调用失败进行的服务降级是SentinelFeignAutoConfiguration实现的,而非openFeign自带的hystrix实现的吗?注意:在使用RestTemplate调用服务,服务挂掉以后是作为异常被捕获并执行@SentinelResource注解的fallback属性对应的降级方法
在指定了服务调用接口的降级实现类以后,不会走sentinel注解中的服务降级方法,而是直接使用服务调用接口实现类中的服务降级,即和OpenFeign自带的hystrix效果是相同的,
本来想测试一下没有服务调用的服务降级情况下会不会走sentinel的运行时异常处理服务降级,但是不写服务调用的fallback服务会直接启动不起来【复习一下FeignClient的服务降级,我记得不写服务调用的降级也是可以运行的检查了一下,OpenFeign使用hystrix进行服务降级调用也要设置
feign: hystrix: enabled: true,这里只设置feign对sentinel的支持可能真的是换了sentinel的方式进行服务调用降级,尝试把这个对sentinel的支持取消掉,此时应该调用的是sentinel对运行时异常响应的fallback服务降级,经过测试,确实此时项目可以正常启动,且调用的是运行时异常响应的fallback的服务降级】没开启sentinel对openFeign的支持没有调用服务降级实现类项目可以启动,开启了没有调用服务降级项目是启动不了的【已验证】
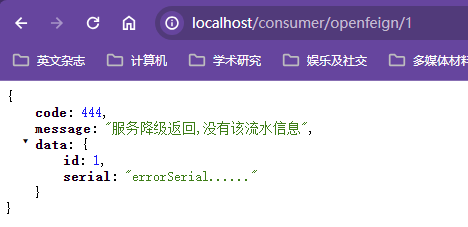
feign.sentinel.enabled=true首先看SentinelFeignAutoConfiguration中如何自动配置:
自动配置类使用条件配置,当feign.sentinel.enabled=true的时候自动配置,@ConditionalOnProperty 中 feign.sentinel.enabled 起了决定性作用,这也就是为什么我们需要在配置文件中指定
feign.sentinel.enabled=true。xxxxxxxxxx("prototype")(name = "feign.sentinel.enabled")public Feign.Builder feignSentinelBuilder() {return SentinelFeign.builder();}接下来看 SentinelFeign.builder 里面的实现:
build方法中重新实现了super.invocationHandlerFactory方法,也就是动态代理工厂,构建的是InvocationHandler对象。
build中会获取Feign Client中的信息,比如fallback,fallbackFactory等,然后创建一个SentinelInvocationHandler,SentinelInvocationHandler继承了InvocationHandler。
xxxxxxxxxxpublic Feign build() {super.invocationHandlerFactory(new InvocationHandlerFactory() {public InvocationHandler create(Target target,Map<Method, MethodHandler> dispatch) {// 得到Feign Client BeanObject feignClientFactoryBean = Builder.this.applicationContext.getBean("&" + target.type().getName());// 得到fallback类Class fallback = (Class) getFieldValue(feignClientFactoryBean,"fallback");// 得到fallbackFactory类Class fallbackFactory = (Class) getFieldValue(feignClientFactoryBean,"fallbackFactory");// 得到调用的服务名称String name = (String) getFieldValue(feignClientFactoryBean, "name");Object fallbackInstance;FallbackFactory fallbackFactoryInstance;// 检查 fallback 和 fallbackFactory 属性if (void.class != fallback) {fallbackInstance = getFromContext(name, "fallback", fallback,target.type());return new SentinelInvocationHandler(target, dispatch,new FallbackFactory.Default(fallbackInstance));}if (void.class != fallbackFactory) {fallbackFactoryInstance = (FallbackFactory) getFromContext(name,"fallbackFactory", fallbackFactory,FallbackFactory.class);return new SentinelInvocationHandler(target, dispatch,fallbackFactoryInstance);}return new SentinelInvocationHandler(target, dispatch);}// 省略部分代码});super.contract(new SentinelContractHolder(contract));return super.build();}SentinelInvocationHandler中的invoke方法里面进行熔断限流的处理
xxxxxxxxxx// 得到资源名称(GET:http://user-service/user/get)String resourceName = methodMetadata.template().method().toUpperCase() + ":"+ hardCodedTarget.url() + methodMetadata.template().url();Entry entry = null;try {ContextUtil.enter(resourceName);entry = SphU.entry(resourceName, EntryType.OUT, 1, args);result = methodHandler.invoke(args);}catch (Throwable ex) {// fallback handleif (!BlockException.isBlockException(ex)) {Tracer.trace(ex);}if (fallbackFactory != null) {try {// 回退处理Object fallbackResult = fallbackMethodMap.get(method).invoke(fallbackFactory.create(ex), args);return fallbackResult;}catch (IllegalAccessException e) {// shouldn't happen as method is public due to being an interfacethrow new AssertionError(e);}catch (InvocationTargetException e) {throw new AssertionError(e.getCause());}}// 省略.....}总结
总的来说,这些框架的整合都有相似之处,前面讲RestTemplate的整合其实和Ribbon中的@LoadBalanced原理差不多,这次的Feign的整合其实我们从其他框架的整合也是可以参考出来的,最典型的就是Hystrix了。
我们想下Hystrix要对Feign的调用进行熔断处理,那么肯定是将Feign的请求包装了HystrixCommand。同样的道理,我们只要找到Hystrix是如何包装的,无非就是将Hystrix的代码换成Sentinel的代码而已。
InvocationHandlerFactory是用于创建动态代理的工厂,有默认的实现,也有Hystrix的实现feign.hystrix.HystrixFeign。
xxxxxxxxxxFeign build(final FallbackFactory<?> nullableFallbackFactory) {super.invocationHandlerFactory(new InvocationHandlerFactory() {@Override public InvocationHandler create(Target target,Map<Method, MethodHandler> dispatch) {return new HystrixInvocationHandler(target, dispatch, setterFactory, nullableFallbackFactory);}});super.contract(new HystrixDelegatingContract(contract));return super.build();}上面这段代码是不是跟Sentinel包装的类似,不同的是Sentinel构造的是SentinelInvocationHandler ,Hystrix构造的是HystrixInvocationHandle。在HystrixInvocationHandler的invoke方法中进行HystrixCommand的包装。
Sentinel持久化
一旦重启应用,sentinel控制规则将消失,生产环境需要将配置规则进行持久化,因为生产环境可能存在大量的流量限制规则,个人玩玩都很烦,要是生产不能持久化就炸了
将限流配置规则持久化进Nacos保存,只要刷新应用的某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对应用上的sentinel上的流控规则持续有效
构建sentinel控制规则持久化
更改26模块实现sentinel控制规则在nacos中的持久化
pom.xml
引入sentinel-datasource-nacos依赖
xxxxxxxxxx<!--SpringCloud ailibaba sentinel-datasource-nacos 后续做持久化用到,sentinel和nacos是有关联的,可以用nacos做持久化,所以项目之初就可以引入nacos、sentinel、sentinel和nacos的数据源依赖--><dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</artifactId></dependency>application.yml
添加nacos数据源配置
xxxxxxxxxxspringcloudsentineldatasourceds1nacosserver-addrlocalhost8848dataIdsentinel-client #dataId,一般起名为应用名,和配置文件的命名规范不同groupIdDEFAULT_GROUP #分组data-typejson #流控规则是一个json串rule-typeflow #表示是一个流控规则在nacos中添加sentinel控制规则配置
注意json中不能有注释,有注释sentinel不生效
xxxxxxxxxx[{"resource": "/sentinel/byUrl","limitApp": "default","grade": 1,"count": 1,"strategy": 0,"contrilBehavior": 0,"clusterMode": false}]【配置详情】
resource:资源名称,就是访问的资源url或者value属性值配置吧
limitApp:来源应用;【没讲什么意思】
grade:阈值类型,0表示线程数,1表示QPS;
count:单机阈值;
strategy:流控模式,0表示直接,1表示关联,2表示链路;
controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待;
clusterMode:是否集群。
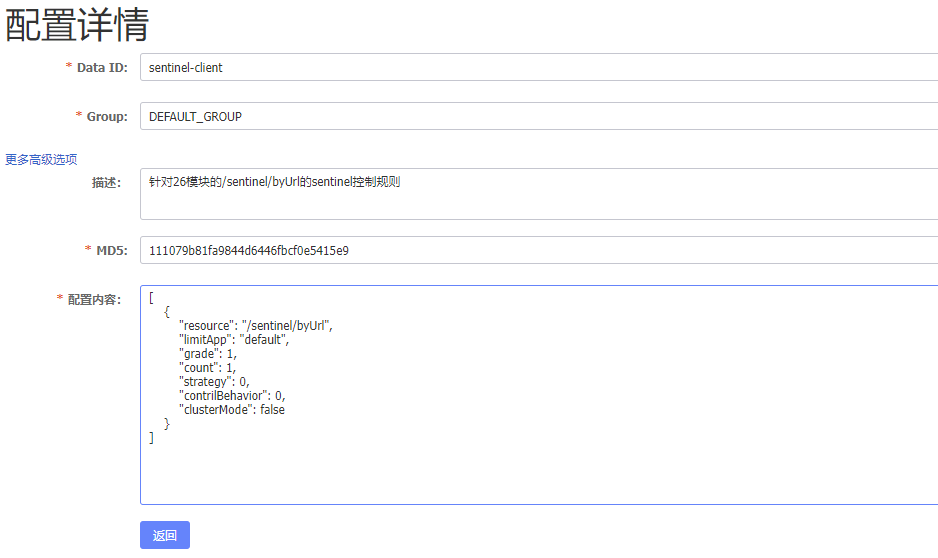
启动服务,并对目标控制器方法进行一次访问,观察sentinel的流控规则列表并测试流控限流效果
流控规则直接出现,其多次点击流控规则生效
在sentinel控制台创建流控规则,重启服务观察是否自动持久化到nacos配置中心
sentinel控制台配置的流控规则无法持久化到nacos中,必须在nacos中用json串的方式进行指定
【重启后效果】
重启前还有test6

Seata分布式事务
分布式事务,单体项目可能最初只有一个数据库【1个服务对1个数据库】,项目大了以后会分库分表,可能一个应用对应多个数据库【一个服务对多个数据库】;到分布式系统,可能一个服务就对应一个数据库,比如订单服务对应一个数据库、物流服务对应一个数据库、商品库存对应一个数据库【多个服务对应多个数据库】;当下单支付成功后,看这个操作可能需要调用多个系统对数据库进行数据更新,但是万一某一步失败就涉及到整体的事务回滚,即产生新的问题,分布式系统下每个服务对应各自的数据库,一个操作多个数据库更新的情况下如何实现事务的相关操作,即牵涉到全局的,跨数据库的,多数据源的统一调度
分布式事务问题
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
即假如一个服务调用出了问题,无法保证服务调用链路上所有操作的事务问题【一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题】
项目架构图
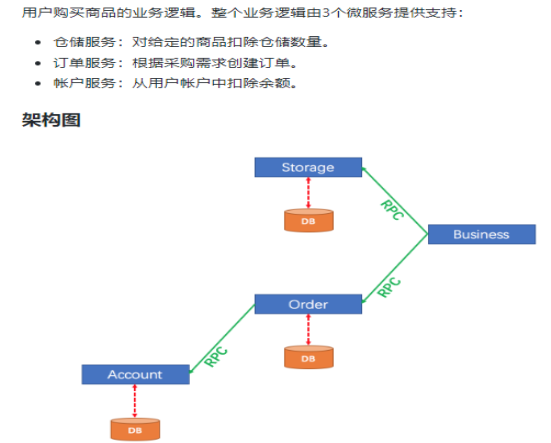
Seata简介
Seata是阿里巴巴的一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
演示用Seata1.1.0,
分布式事务处理过程
Seata由1+3的套件组成,1是id证明涉及数据库是同一批业务的;3指三套组件,
【一个ID】
Transaction ID【XID】:全局唯一的事务ID,用来辨识某次业务中所有涉及到的数据库操作,类似于通过班级id找到班级下的学生,即通过全局的事务ID找到所有涉及的数据库操作
【三个组件】
Transaction Coordinator【TC】:事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
Transaction Manager 【TM】:控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
Resource Manager 【RM】:控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
处理流程
第一步:TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
把TC理解成总管,活跃于整个业务调用链路,既接受TM发起的全局事务申请和全局事务回滚或者提交的决议,接收RM的分支事务注册;也负责调度分支事务RM完成分支事务的提交或者回滚,简而言之,把各个服务的事务提交或者回滚放在整个服务调用链路走完发起的总的提交或者回滚决议,当总的服务调用链路走完发起总的提交或者回滚决议之后由TC调度各个分支事务完成总的提交或者回滚决议
TM负责全局层面上的开启、提交或者回滚事务
XID 在微服务调用链路的上下文中传播;
就是XID在调用链路中传播,放哪儿的没有讲,XID作为同一个业务全局事务的判定【比如根据key放分支事务对象,根据key依次取出分支事务进行调度提交或者回滚】
RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖;
RM可以直接理解成对应每个数据库的数据源
TM 向 TC 发起针对 XID 的全局提交或回滚决议;
这个TM是怎么发起全局提交或者回滚决议的?
TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
事务的实现只需要在业务方法上添加一个@GlobalTransactional注解
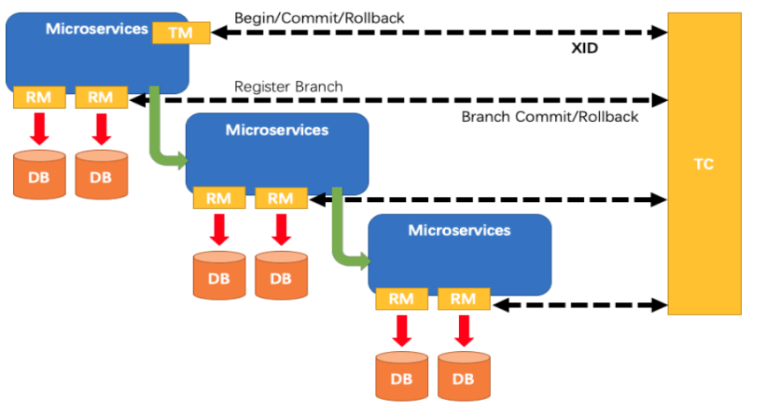
Seata Server的安装
下载地址:https://github.com/seata/seata/releases
http://seata.io/zh-cn/官网点击下载也可以
mysql版本为8的 自行替换lib目录的mysql jar包,jdk_1.8.125 以上 才可以 运行
演示用0.9版本的windows版本,seata的版本更新比较频繁
下载对应版本的binary选项并解压缩【下载慢,需要梯子】
备份原始的file.conf文件,主要修改自定义事务组名称和事务日志存储模式为db+日志存储到的对应数据库连接信息
更改配置文件file.conf的service模块
默认配置的属性
vgroup_mapping.my_test_tx_group = "default"默认值是default,更改为自定义的事务组名称,名字随便取xxxxxxxxxxservice {#将该属性设置为自定义属性vgroup_mapping.my_test_tx_group = "fsp_tx_group"default.grouplist = "127.0.0.1:8091"enableDegrade = falsedisable = falsemax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"}更改配置文件file.conf的store模块
修改事务日志存储模式为db,默认模式为file,表示日志存入文件中,将日志存储模式改成db表示将日志存入数据库
添加日志存储到的对应数据库连接信息【mysql8+连接配置如下(注意时区可能不一样),如果是Steata0.9.0配合MySQL8.0以上版本,须更改driver-class-name = "com.mysql.cj.jdbc.Driver",此外还要将mysql8+的驱动jar包复制到seta的lib目录,将原来的5的驱动删除,url的seata后面增加?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false】
【事务日志存储模块】
注意数据库需要创建对应的seata或其他名字的数据库
seata的conf目录下有db_store.sql数据库,直接拷贝执行,会生成分支表,全局表和锁表【没有sql语句的再去下载相应的source,找到script目录下的sql文件导入到数据库即可,官网文档有部署讲解】
xxxxxxxxxx## transaction log storestore {## store mode: file、dbmode = "db"## file storefile {dir = "sessionStore"# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptionsmax-branch-session-size = 16384# globe session size , if exceeded throws exceptionsmax-global-session-size = 512# file buffer size , if exceeded allocate new bufferfile-write-buffer-cache-size = 16384# when recover batch read sizesession.reload.read_size = 100# async, syncflush-disk-mode = async}## database storedb {## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.datasource = "dbcp"## mysql/oracle/h2/oceanbase etc.db-type = "mysql"driver-class-name = "com.mysql.jdbc.Driver"url = "jdbc:mysql://127.0.0.1:3306/seata"user = "root"password = "你自己数据库的密码"min-conn = 1max-conn = 3global.table = "global_table"branch.table = "branch_table"lock-table = "lock_table"query-limit = 100}}创建对应配置文件的seata数据库,并将conf目录下的db_store.sql拷贝执行到该数据库下
修改配置文件registry.conf的配置内容
表示将seata注册到那个注册中心,从配置文件能看出支持file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
需要在type属性指定注册中心的类型并配置对应的注册中心信息
将注册中心修改为nacos,并添加nacos连接信息
xxxxxxxxxxregistry {# file 、nacos 、eureka、redis、zk、consul、etcd3、sofatype = "nacos"nacos {serverAddr = "localhost:8848"namespace = ""cluster = "default"}当前目录下执行
seata-server.bat命令如果能看到load ResgistryProvider表示成功运行【seata启动前需要先启动nacos,否则启动不起来,报错no available server to connect】
业务场景搭建
搭建一个包括订单/库存/账户业务3个数据库和对应三个微服务
业务逻辑:用户拒下单在订单服务创建订单,远程调用库存服务扣减单个商品的库存,再远程调用账户服务扣减账户余额,最后在订单服务中修改订单状态为已完成
创建三个业务数据
数据库名字分别为
seata_order,seata_storage,seata_accountseata_order:存储订单的数据库;
创建订单表
xxxxxxxxxxCREATE TABLE t_order (`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,`user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id',`product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id',`count` INT(11) DEFAULT NULL COMMENT '数量',`money` DECIMAL(11,0) DEFAULT NULL COMMENT '金额',`status` INT(1) DEFAULT NULL COMMENT '订单状态:0:创建中;1:已完结') ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;SELECT * FROM t_order;seata_storage:存储库存的数据库;
创建库存表
xxxxxxxxxxCREATE TABLE t_storage (`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,`product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id',`total` INT(11) DEFAULT NULL COMMENT '总库存',`used` INT(11) DEFAULT NULL COMMENT '已用库存',`residue` INT(11) DEFAULT NULL COMMENT '剩余库存') ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;INSERT INTO seata_storage.t_storage(`id`, `product_id`, `total`, `used`, `residue`)VALUES ('1', '1', '100', '0', '100');SELECT * FROM t_storage;seata_account:存储账户信息的数据库
xxxxxxxxxxCREATE TABLE t_account (`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'id',`user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id',`total` DECIMAL(10,0) DEFAULT NULL COMMENT '总额度',`used` DECIMAL(10,0) DEFAULT NULL COMMENT '已用余额',`residue` DECIMAL(10,0) DEFAULT '0' COMMENT '剩余可用额度') ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;INSERT INTO seata_account.t_account(`id`, `user_id`, `total`, `used`, `residue`) VALUES ('1', '1', '1000', '0', '1000');SELECT * FROM t_account;
在三个业务数据库下创建3个库各自对应的回滚日志表undo_log
这个回滚日志表seata提供了,在conf目录下,不是seata必须的,可以用于seata在业务中添加各个业务的回滚日志
每个业务数据库都要创建该回滚日志表,建表语句在\seata-server-0.9.0\seata\conf目录下的db_undo_log.sql
xxxxxxxxxx-- the table to store seata xid data-- 0.7.0+ add context-- you must to init this sql for you business databese. the seata server not need it.-- 此脚本必须初始化在你当前的业务数据库中,用于AT 模式XID记录。与server端无关(注:业务数据库)-- 注意此处0.3.0+ 增加唯一索引 ux_undo_logCREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;创建30订单模块
pom.xml
xxxxxxxxxx<dependencies><!--nacos--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--seata,seata中自带了seata服务器的相关依赖seata-all,一定要剔除自己带的seata-all,引入对应使用的seata server版本的依赖--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId><exclusions><exclusion><artifactId>seata-all</artifactId><groupId>io.seata</groupId></exclusion></exclusions></dependency><!--引入对应seata server对应版本的seata server--><dependency><groupId>io.seata</groupId><artifactId>seata-all</artifactId><version>0.9.0</version></dependency><!--使用openfeign来进行服务调用--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><!--web-actuator--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!--mysql-druid--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.0.0</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!--使用其中的通用返回结果--><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency></dependencies>application.yml
xxxxxxxxxxserverport80springapplicationnameseata-consumer-ordercloudalibabaseata#微服务配置的事务组名称需要与seata-server中的自定义事务组名称对应,其实就相当于把相关微服务安排到同一个事务组中,在seata server的配置#文件中声明该事务组tx-service-groupfsp_tx_groupnacosdiscoveryserver-addrlocalhost8848datasourcedriver-class-namecom.mysql.cj.jdbc.Driver#url: jdbc:mysql://localhost:3306/seata_order#mysql8的分布式事务需要添加useInformationSchema=false参数,mysql5默认就是false,而且使用seata的全局分布式事务控制才需要注意这个问题urljdbcmysql//localhost3306/seata_order?useInformationSchema=falseusernamerootpasswordHaworthia0715#不开启hystrix对feign的支持,即不支持服务调用熔断feignhystrixenabledfalselogginglevelioseatainfomybatismapperLocationsclasspathmapper/*.xml启动类
xxxxxxxxxx(exclude = DataSourceAutoConfiguration.class)//取消数据源的自动配置,谁管理数据源,谁就能控制事务。默认druid管理,应该交由seata管理。seata管理数据源后,seata才能管理事务。public class SeataOrderApplication {public static void main(String[] args){SpringApplication.run(SeataOrderApplication.class, args);}}实体类
订单类,包括id,用户id,商品id,商品下单数量,金额,支付状态
xxxxxxxxxxpublic class Order {private Long id;private Long userId;private Long productId;private Integer count;private BigDecimal money;/*** 订单状态:0:创建中;1:已完结*/private Integer status;}远程调用openFeign代理接口
【库存远程调用接口】
xxxxxxxxxx(value = "seata-provider-storage")public interface StorageClient {/*** 扣减库存*/(value = "/storage/decrease")CommonResp decrease(("productId") Long productId, ("count") Integer count);}【用户远程调用接口】
xxxxxxxxxx(value = "seata-provider-account")public interface AccountClient {/*** 扣减账户余额*///@RequestMapping(value = "/account/decrease", method = RequestMethod.POST, produces = "application/json; charset=UTF-8")("/account/decrease")CommonResp decrease(("userId") Long userId, ("money") BigDecimal money);}控制器
xxxxxxxxxxpublic class OrderController {private OrderService orderService;/*** 创建订单*/("/order/create")public CommonResp create(Order order) {orderService.create(order);return new CommonResp(200, "订单创建成功!");}}service
【订单服务接口】
xxxxxxxxxxpublic interface OrderService {/*** 创建订单*/void create(Order order);}【实现类】
创建订单,调用mapper的创建订单方法向订单数据库插入一条订单记录
xxxxxxxxxxpublic class OrderServiceImpl implements OrderService {private OrderMapper orderMapper;private StorageClient storageClient;private AccountClient accountClient;/*** 创建订单->调用库存服务扣减库存->调用账户服务扣减账户余额->修改订单状态* 简单说:* 下订单->减库存->减余额->改状态*/(name = "fsp-create-order",rollbackFor = Exception.class)public void create(Order order) {log.info("------->下单开始");//本应用创建订单orderMapper.create(order);//远程调用库存服务扣减库存log.info("------->order-service中扣减库存开始");storageClient.decrease(order.getProductId(),order.getCount());log.info("------->order-service中扣减库存结束");//远程调用账户服务扣减余额log.info("------->order-service中扣减余额开始");accountClient.decrease(order.getUserId(),order.getMoney());log.info("------->order-service中扣减余额结束");//修改订单状态为已完成log.info("------->order-service中修改订单状态开始");orderMapper.update(order.getUserId(),0);log.info("------->order-service中修改订单状态结束");log.info("------->下单结束");}}mapper
【接口】
xxxxxxxxxxpublic interface OrderMapper {/*** 创建订单*/void create(Order order);/*** 修改订单金额*/void update(("userId") Long userId, ("status") Integer status);}【对应SQL映射的xml文件】
xxxxxxxxxx<mapper namespace="com.atlisheng.cloud.mapper.OrderMapper"><resultMap id="BaseResultMap" type="com.atlisheng.cloud.entities.Order"><id column="id" property="id" jdbcType="BIGINT"/><result column="user_id" property="userId" jdbcType="BIGINT"/><result column="product_id" property="productId" jdbcType="BIGINT"/><result column="count" property="count" jdbcType="INTEGER"/><result column="money" property="money" jdbcType="DECIMAL"/><result column="status" property="status" jdbcType="INTEGER"/></resultMap><insert id="create">INSERT INTO `t_order` (`id`, `user_id`, `product_id`, `count`, `money`, `status`)VALUES (NULL, #{userId}, #{productId}, #{count}, #{money}, 0);</insert><update id="update">UPDATE `t_order`SET status = 1WHERE user_id = #{userId} AND status = #{status};</update></mapper>配置类
【mybatis的mapper扫描】
xxxxxxxxxx({"com.atlisheng.cloud.mapper"})public class MyBatisConfig {}【数据源代理】
取消默认数据源的配置,同时也取消了默认数据源管理事务的能力,让seat来管理数据源和事务
xxxxxxxxxxpublic class DataSourceProxyConfig {("${mybatis.mapperLocations}")private String mapperLocations;(prefix = "spring.datasource")public DataSource druidDataSource(){return new DruidDataSource();}public DataSourceProxy dataSourceProxy(DataSource dataSource) {return new DataSourceProxy(dataSource);}public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSourceProxy);sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());return sqlSessionFactoryBean.getObject();}}seata server-0.9.0对应配置文件
【file.conf】
xxxxxxxxxxtransport {# tcp udt unix-domain-sockettype = "TCP"#NIO NATIVEserver = "NIO"#enable heartbeatheartbeat = true#thread factory for nettythread-factory {boss-thread-prefix = "NettyBoss"worker-thread-prefix = "NettyServerNIOWorker"server-executor-thread-prefix = "NettyServerBizHandler"share-boss-worker = falseclient-selector-thread-prefix = "NettyClientSelector"client-selector-thread-size = 1client-worker-thread-prefix = "NettyClientWorkerThread"# netty boss thread size,will not be used for UDTboss-thread-size = 1#auto default pin or 8worker-thread-size = 8}shutdown {# when destroy server, wait secondswait = 3}serialization = "seata"compressor = "none"}service {#vgroup->rgroup#这儿和seata server总的配置属性不同,不懂是啥意思vgroup_mapping.fsp_tx_group = "default"#only support single nodedefault.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"#总的file.conf也没有这个属性disableGlobalTransaction = false}client {async.commit.buffer.limit = 10000lock {retry.internal = 10retry.times = 30}report.retry.count = 5tm.commit.retry.count = 1tm.rollback.retry.count = 1}transaction {undo.data.validation = trueundo.log.serialization = "jackson"undo.log.save.days = 7#schedule delete expired undo_log in millisecondsundo.log.delete.period = 86400000undo.log.table = "undo_log"}support {## springspring {# auto proxy the DataSource beandatasource.autoproxy = false}}【registry.conf】
xxxxxxxxxxregistry {# file 、nacos 、eureka、redis、zktype = "nacos"nacos {serverAddr = "localhost:8848"namespace = ""cluster = "default"}eureka {serviceUrl = "http://localhost:8761/eureka"application = "default"weight = "1"}redis {serverAddr = "localhost:6381"db = "0"}zk {cluster = "default"serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}config {# file、nacos 、apollo、zktype = "file"nacos {serverAddr = "localhost"namespace = ""cluster = "default"}apollo {app.id = "fescar-server"apollo.meta = "http://192.168.1.204:8801"}zk {serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}
创建31库存模块
后两个模块在30模块正常启动的情况下报错register type为null,连续启几次都报错,找半天错误都找不到,唯一修改的地方就是yml中的数据源驱动忘记添加cj,但是当时还是无法启动,报错相同;过了很久没有任何修改,两个模块都能启动了,贼特么玄学
pom.xml
xxxxxxxxxx<dependencies><!--nacos--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId><exclusions><exclusion><artifactId>seata-all</artifactId><groupId>io.seata</groupId></exclusion></exclusions></dependency><dependency><groupId>io.seata</groupId><artifactId>seata-all</artifactId><version>0.9.0</version></dependency><!--feign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.0.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency></dependencies>application.yml
xxxxxxxxxxserverport8018springapplicationnameseata-provider-storagecloudalibabaseatatx-service-groupfsp_tx_groupnacosdiscoveryserver-addrlocalhost8848datasourcedriver-class-namecom.mysql.jdbc.Driverurljdbcmysql//localhost3306/seata_storageusernamerootpasswordHaworthia0715logginglevelioseatainfomybatismapperLocationsclasspathmapper/*.xml启动类
xxxxxxxxxx(exclude = DataSourceAutoConfiguration.class)//取消数据源的自动配置,谁管理数据源,谁就能控制事务。默认druid管理,应该交由seata管理。seata管理数据源后,seata才能管理事务。public class SeataOrderApplication {public static void main(String[] args){SpringApplication.run(SeataOrderApplication.class, args);}}实体类
库存类,包括库存id,商品id,总库存,已用,剩余库存
xxxxxxxxxxpublic class Storage {private Long id;/*** 产品id*/private Long productId;/*** 总库存*/private Integer total;/*** 已用库存*/private Integer used;/*** 剩余库存*/private Integer residue;}控制器
xxxxxxxxxxpublic class StorageController {private StorageService storageService;/*** 扣减库存*/("/storage/decrease")public CommonResp decrease(Long productId, Integer count) {storageService.decrease(productId, count);return new CommonResp(200,"扣减库存成功!");}}service
【订单服务接口】
xxxxxxxxxxpublic interface StorageService {/*** 扣减库存*/void decrease(Long productId, Integer count);}【实现类】
创建订单,调用mapper的创建订单方法向订单数据库插入一条订单记录
xxxxxxxxxxpublic class StorageServiceImpl implements StorageService {private static final Logger LOGGER = LoggerFactory.getLogger(StorageServiceImpl.class);private StorageMapper storageMapper;/*** 扣减库存*/public void decrease(Long productId, Integer count) {LOGGER.info("------->storage-service中扣减库存开始");storageMapper.decrease(productId,count);LOGGER.info("------->storage-service中扣减库存结束");}}mapper
【接口】
xxxxxxxxxxpublic interface StorageMapper {/*** 扣减库存*/void decrease(("productId") Long productId, ("count") Integer count);}【对应SQL映射的xml文件】
xxxxxxxxxx<mapper namespace="com.atlisheng.cloud.mapper.StorageMapper"><resultMap id="BaseResultMap" type="com.atlisheng.cloud.entities.Storage"><id column="id" property="id" jdbcType="BIGINT"/><result column="product_id" property="productId" jdbcType="BIGINT"/><result column="total" property="total" jdbcType="INTEGER"/><result column="used" property="used" jdbcType="INTEGER"/><result column="residue" property="residue" jdbcType="INTEGER"/></resultMap><!--更新库存信息同时更新了两个字段,已用库存和剩余库存--><update id="decrease">UPDATE t_storageSET used = used + #{count},residue = residue - #{count}WHERE product_id = #{productId}</update></mapper>配置类
【mybatis的mapper扫描】
xxxxxxxxxx({"com.atlisheng.cloud.mapper"})public class MyBatisConfig {}【数据源代理】
取消默认数据源的配置,同时也取消了默认数据源管理事务的能力,让seat来管理数据源和事务
xxxxxxxxxxpublic class DataSourceProxyConfig {("${mybatis.mapperLocations}")private String mapperLocations;(prefix = "spring.datasource")public DataSource druidDataSource(){return new DruidDataSource();}public DataSourceProxy dataSourceProxy(DataSource dataSource) {return new DataSourceProxy(dataSource);}public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSourceProxy);sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());return sqlSessionFactoryBean.getObject();}}seata server-0.9.0对应配置文件
【file.conf】
xxxxxxxxxxtransport {# tcp udt unix-domain-sockettype = "TCP"#NIO NATIVEserver = "NIO"#enable heartbeatheartbeat = true#thread factory for nettythread-factory {boss-thread-prefix = "NettyBoss"worker-thread-prefix = "NettyServerNIOWorker"server-executor-thread-prefix = "NettyServerBizHandler"share-boss-worker = falseclient-selector-thread-prefix = "NettyClientSelector"client-selector-thread-size = 1client-worker-thread-prefix = "NettyClientWorkerThread"# netty boss thread size,will not be used for UDTboss-thread-size = 1#auto default pin or 8worker-thread-size = 8}shutdown {# when destroy server, wait secondswait = 3}serialization = "seata"compressor = "none"}service {#vgroup->rgroup#这儿和seata server总的配置属性不同,不懂是啥意思vgroup_mapping.fsp_tx_group = "default"#only support single nodedefault.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"#总的file.conf也没有这个属性disableGlobalTransaction = false}client {async.commit.buffer.limit = 10000lock {retry.internal = 10retry.times = 30}report.retry.count = 5tm.commit.retry.count = 1tm.rollback.retry.count = 1}transaction {undo.data.validation = trueundo.log.serialization = "jackson"undo.log.save.days = 7#schedule delete expired undo_log in millisecondsundo.log.delete.period = 86400000undo.log.table = "undo_log"}support {## springspring {# auto proxy the DataSource beandatasource.autoproxy = false}}【registry.conf】
xxxxxxxxxxregistry {# file 、nacos 、eureka、redis、zktype = "nacos"nacos {serverAddr = "localhost:8848"namespace = ""cluster = "default"}eureka {serviceUrl = "http://localhost:8761/eureka"application = "default"weight = "1"}redis {serverAddr = "localhost:6381"db = "0"}zk {cluster = "default"serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}config {# file、nacos 、apollo、zktype = "file"nacos {serverAddr = "localhost"namespace = ""cluster = "default"}apollo {app.id = "fescar-server"apollo.meta = "http://192.168.1.204:8801"}zk {serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}
创建32账户模块
pom.xml和mybatis配置,数据源代理配置和seata的配置文件没有变化
pom.xml
xxxxxxxxxx<dependencies><!--nacos--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><!--seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId><exclusions><exclusion><artifactId>seata-all</artifactId><groupId>io.seata</groupId></exclusion></exclusions></dependency><dependency><groupId>io.seata</groupId><artifactId>seata-all</artifactId><version>0.9.0</version></dependency><!--feign--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.0.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency></dependencies>application.yml
xxxxxxxxxxserverport8019springapplicationnameseata-provider-accountcloudalibabaseatatx-service-groupfsp_tx_groupnacosdiscoveryserver-addrlocalhost8848datasourcedriver-class-namecom.mysql.jdbc.Driverurljdbcmysql//localhost3306/seata_accountusernamerootpasswordHaworthia0715feignhystrixenabledfalselogginglevelioseatainfomybatismapperLocationsclasspathmapper/*.xml启动类
xxxxxxxxxx(exclude = DataSourceAutoConfiguration.class)//取消数据源的自动配置,谁管理数据源,谁就能控制事务。默认druid管理,应该交由seata管理。seata管理数据源后,seata才能管理事务。public class SeataOrderApplication {public static void main(String[] args){SpringApplication.run(SeataOrderApplication.class, args);}}实体类
账户类,包括账户id,用户id,用户额度,已用额度,剩余额度
xxxxxxxxxxpublic class Account {private Long id;/*** 用户id*/private Long userId;/*** 总额度*/private BigDecimal total;/*** 已用额度*/private BigDecimal used;/*** 剩余额度*/private BigDecimal residue;}控制器
xxxxxxxxxxpublic class AccountController {AccountService accountService;/*** 扣减账户余额*/("/account/decrease")public CommonResp decrease(("userId") Long userId, ("money") BigDecimal money){accountService.decrease(userId,money);return new CommonResp(200,"扣减账户余额成功!");}}service
【订单服务接口】
xxxxxxxxxxpublic interface AccountService {/*** 扣减账户余额* @param userId 用户id* @param money 金额*/void decrease(("userId") Long userId, ("money") BigDecimal money);}【实现类】
创建订单,调用mapper的创建订单方法向订单数据库插入一条订单记录
xxxxxxxxxxpublic class AccountServiceImpl implements AccountService {private static final Logger LOGGER = LoggerFactory.getLogger(AccountServiceImpl.class);AccountMapper accountMapper;/*** 扣减账户余额*/public void decrease(Long userId, BigDecimal money) {LOGGER.info("------->account-service中扣减账户余额开始");//模拟超时异常,全局事务回滚//暂停几秒钟线程//try { TimeUnit.SECONDS.sleep(30); } catch (InterruptedException e) { e.printStackTrace(); }accountMapper.decrease(userId,money);LOGGER.info("------->account-service中扣减账户余额结束");}}mapper
【接口】
xxxxxxxxxxpublic interface AccountMapper {/*** 扣减账户余额*/void decrease(("userId") Long userId, ("money") BigDecimal money);}【对应SQL映射的xml文件】
xxxxxxxxxx<mapper namespace="com.atlisheng.cloud.mapper.AccountMapper"><resultMap id="BaseResultMap" type="com.atlisheng.cloud.entities.Account"><id column="id" property="id" jdbcType="BIGINT"/><result column="user_id" property="userId" jdbcType="BIGINT"/><result column="total" property="total" jdbcType="DECIMAL"/><result column="used" property="used" jdbcType="DECIMAL"/><result column="residue" property="residue" jdbcType="DECIMAL"/></resultMap><update id="decrease">UPDATE t_accountSETresidue = residue - #{money},used = used + #{money}WHEREuser_id = #{userId};</update></mapper>配置类
【mybatis的mapper扫描】
xxxxxxxxxx({"com.atlisheng.cloud.mapper"})public class MyBatisConfig {}【数据源代理】
取消默认数据源的配置,同时也取消了默认数据源管理事务的能力,让seat来管理数据源和事务
xxxxxxxxxxpublic class DataSourceProxyConfig {("${mybatis.mapperLocations}")private String mapperLocations;(prefix = "spring.datasource")public DataSource druidDataSource(){return new DruidDataSource();}public DataSourceProxy dataSourceProxy(DataSource dataSource) {return new DataSourceProxy(dataSource);}public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxy dataSourceProxy) throws Exception {SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSourceProxy);sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapperLocations));sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());return sqlSessionFactoryBean.getObject();}}seata server-0.9.0对应配置文件
【file.conf】
xxxxxxxxxxtransport {# tcp udt unix-domain-sockettype = "TCP"#NIO NATIVEserver = "NIO"#enable heartbeatheartbeat = true#thread factory for nettythread-factory {boss-thread-prefix = "NettyBoss"worker-thread-prefix = "NettyServerNIOWorker"server-executor-thread-prefix = "NettyServerBizHandler"share-boss-worker = falseclient-selector-thread-prefix = "NettyClientSelector"client-selector-thread-size = 1client-worker-thread-prefix = "NettyClientWorkerThread"# netty boss thread size,will not be used for UDTboss-thread-size = 1#auto default pin or 8worker-thread-size = 8}shutdown {# when destroy server, wait secondswait = 3}serialization = "seata"compressor = "none"}service {#vgroup->rgroup#这儿和seata server总的配置属性不同,不懂是啥意思vgroup_mapping.fsp_tx_group = "default"#only support single nodedefault.grouplist = "127.0.0.1:8091"#degrade current not supportenableDegrade = false#disabledisable = false#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanentmax.commit.retry.timeout = "-1"max.rollback.retry.timeout = "-1"#总的file.conf也没有这个属性disableGlobalTransaction = false}client {async.commit.buffer.limit = 10000lock {retry.internal = 10retry.times = 30}report.retry.count = 5tm.commit.retry.count = 1tm.rollback.retry.count = 1}transaction {undo.data.validation = trueundo.log.serialization = "jackson"undo.log.save.days = 7#schedule delete expired undo_log in millisecondsundo.log.delete.period = 86400000undo.log.table = "undo_log"}support {## springspring {# auto proxy the DataSource beandatasource.autoproxy = false}}【registry.conf】
xxxxxxxxxxregistry {# file 、nacos 、eureka、redis、zktype = "nacos"nacos {serverAddr = "localhost:8848"namespace = ""cluster = "default"}eureka {serviceUrl = "http://localhost:8761/eureka"application = "default"weight = "1"}redis {serverAddr = "localhost:6381"db = "0"}zk {cluster = "default"serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}config {# file、nacos 、apollo、zktype = "file"nacos {serverAddr = "localhost"namespace = ""cluster = "default"}apollo {app.id = "fescar-server"apollo.meta = "http://192.168.1.204:8801"}zk {serverAddr = "127.0.0.1:2181"session.timeout = 6000connect.timeout = 2000}file {name = "file.conf"}}
@GlobalTransactional注解
只需要在业务方法上使用@GlobalTransactional注解就能实现分布式事务的控制
测试在不加@GlobalTransactional注解的情况下因为超时异常引起的问题
初始状况,订单库为空,没有下任何订单; 库存表记录中已使用为0,剩余库存100;账户余额为1000,已使用为0
正常情况下的服务调用
启动nacos、seata、30模块、31模块、32模块,发送get请求
http://localhost/order/create?userId=1&productId=1&count=10&money=100默认下订单分布式事务mysql8需要在数据库连接中添加参数
useInformationSchema=false,mysql8默认是true,mysql5默认是false,不是分布式事务的不需要加,原因不清楚,能干什么也不清楚,大致原因是Connector/J 5.0.0以后的版本有一个名为useInformationSchema的数据库连接参数, 在默认连接参数情况下,useInformationSchema=false,导致Connection.getMetaData()方法返回的DatabaseMetaData 对象是com.mysql.jdbc.DatabaseMetaData,而不是com.mysql.jdbc。DatabaseMetaDataUsingInfoSchema,DatabaseMetaDataUsingInfoSchema是DatabaseMetaData是的子类,看名称就能联想到是通过 INFORMATION_SCHEMA 数据库获取数据库的metadata,可以正确返回table_comment字段。但是我这儿第一个入口服务需要添加,后续的调用服务不需要添加这个参数,而且也不需要添加时区等一系列参数也不会有问题,为什么永远不讲,完整的连接jdbc:mysql://localhost:3306/seata_order?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false&useInformationSchema=false,使用jdbc:mysql://localhost:3306/seata_order会报错,使用jdbc:mysql://localhost:3306/seata_order?useInformationSchema=false没问题,被调用服务没有这个参数直接裸jdbc:mysql://localhost:3306/seata_order也不会出问题 原文链接:https://blog.csdn.net/L1Ha1Y1/article/details/108681489【执行了两次的情况】
正常扣款,库存正常减,用户的余额正常减,订单状态正常改成1表示已支付
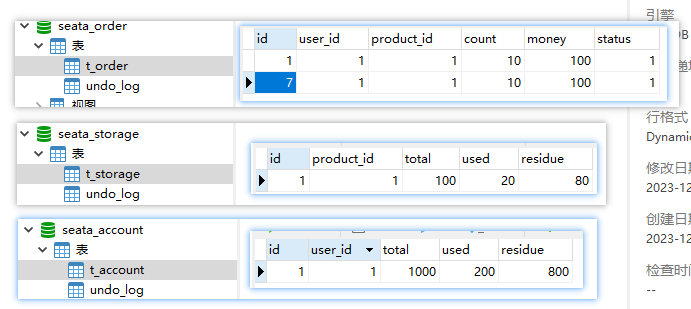
添加扣款服务扣款前睡30秒,模拟扣款网络不好,最后能扣款,但是服务调用超时,订单状态没有设置为已支付
此时没有使用@GlobalTransactional注解开启分布式事务
xxxxxxxxxxpublic void decrease(Long userId, BigDecimal money) {LOGGER.info("------->account-service中扣减账户余额开始");//模拟超时异常,全局事务回滚//暂停几秒钟线程try { TimeUnit.SECONDS.sleep(30); } catch (InterruptedException e) { e.printStackTrace(); }accountMapper.decrease(userId,money);LOGGER.info("------->account-service中扣减账户余额结束");}【执行效果】
服务调用报500错误
订单状态显示未支付,实际上库存已经扣除,用户余额已经扣款;根据订单状态判断的后续一系列操作会报错
由于feign的超时重试机制【ribbon负载均衡策略中的RetryRule重试策略】,账户余额还有可能被多次扣减
一旦发生异常导致事务没有被控制,非常恐怖,要查出所有关联数据库甚至集群中哪些数据影响了,哪些数据还没执行进行恢复,非常的痛苦
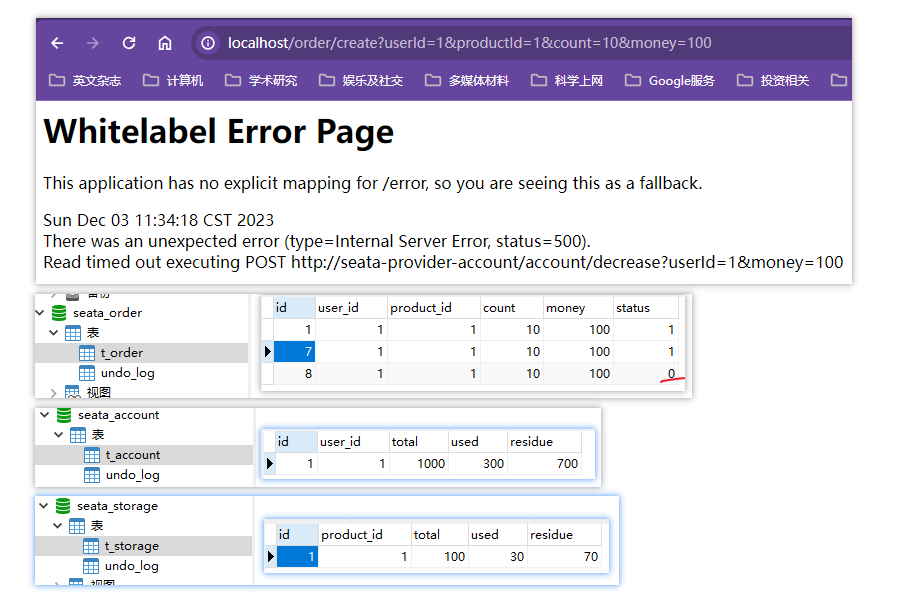
添加@GlobalTransactional注解开启分布式事务情况下设置扣款超时异常的执行情况
【@GlobalTransactional注解】
xxxxxxxxxx/*** The interface Global transactional.*/(RetentionPolicy.RUNTIME)(ElementType.METHOD)public @interface GlobalTransactional {/*** Global transaction timeoutMills in MILLISECONDS.毫秒级的全局事务超时** @return timeoutMills in MILLISECONDS.*/int timeoutMills() default TransactionInfo.DEFAULT_TIME_OUT;/*** Given name of the global transaction instance.全局事务实例名** @return Given name.*/String name() default "";/*** roll back for the Class哪些异常碰到了要回滚* @return*/Class<? extends Throwable>[] rollbackFor() default {};/*** roll back for the class name* @return*/String[] rollbackForClassName() default {};/*** not roll back for the Class* @return*/Class<? extends Throwable>[] noRollbackFor() default {};/*** not roll back for the class name哪些异常碰到了不要回滚* @return*/String[] noRollbackForClassName() default {};}【添加@GlobalTransactional注解】
且只要将@GlobalTransactional注解注释在要控制事务的方法上即可,里面发生服务调用的服务类不需要添加任何东西
xxxxxxxxxx/*** 创建订单->调用库存服务扣减库存->调用账户服务扣减账户余额->修改订单状态* 简单说:* 下订单->减库存->减余额->改状态*///name的名字是随便起的,和事务组也没有关系,只要唯一不重复即可;rollbackFor这里指发生任何异常都回滚(name = "fsp-create-order",rollbackFor = Exception.class)public void create(Order order) {log.info("------->下单开始");//本应用创建订单orderMapper.create(order);//远程调用库存服务扣减库存log.info("------->order-service中扣减库存开始");storageClient.decrease(order.getProductId(),order.getCount());log.info("------->order-service中扣减库存结束");//远程调用账户服务扣减余额log.info("------->order-service中扣减余额开始");accountClient.decrease(order.getUserId(),order.getMoney());log.info("------->order-service中扣减余额结束");//修改订单状态为已完成log.info("------->order-service中修改订单状态开始");orderMapper.update(order.getUserId(),0);log.info("------->order-service中修改订单状态结束");log.info("------->下单结束");}【测试效果】
事务被成功控制住
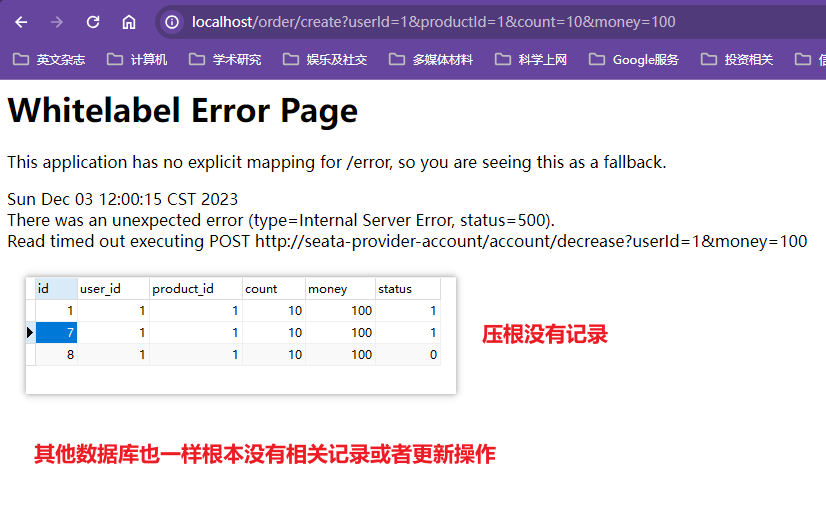
Seata执行流程
19年蚂蚁金服和alibaba共同开源的分布式事务解决方案,seata0.9.0不支持分布式服务集群,Seata1.0以后支持分布式集群,大厂一般才用集群,阿里在这个基础上开发的商用版本阿里云GTS
TC/TM/RM三大组件
TC就是seata服务器,即seata server
TM是标注了@GlobalTransactional注解的对应服务【是不是服务还需要自己查,这里只是方便理解】,TM是全局事务的发起方
RM近似理解为一个数据库就是一个RM,即事务的参与方,控制分支事务的提交回滚,状态汇报
事务执行流程
TM 开启分布式事务(TM 向 TC 注册全局事务记录);
按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
TC 汇总事务信息,决定分布式事务是提交还是回滚;
TC 通知所有 RM 提交/回滚 资源,事务二阶段结束。
seata的四大模式
非常多的企业都在用
AT模式
【低侵入自动补偿的事务模式,默认就是使用该模式,支持MySQL、Oracle、PostgreSQL、TiDB、MariaDB、DaMeng、PolarDB-X 2.0、SQLServer的AT模式】
TCC模式
【支持 TCC 模式并可与 AT 混用,灵活度更高】
SAGA模式
为长事务提供有效的解决方案,提供编排式与注解式(开发中)
XA模式
支持已实现 XA 接口的数据库的 XA 模式,目前已支持MySQL、Oracle和MariaDB
AT模式
实现事务的同时对业务无入侵,支持本地ACID事务的关系型数据库,是通过JDBC访问数据库的java应用
就是AOP思想加回退反写机制
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁【seata服务器中对应的数据库表lock_table】和连接资源
二阶段:提交异步化,能够非常快速地完成提交【提交就是异步删除所有的前置快照,后置快照和锁,所以快】;回滚通过一阶段的回滚日志进行反向补偿
undo_log和lock_table中没有数据是因为没有发生脏读情况,数据都被删除了,在debug中演示
一阶段seata拦截业务SQL,找到业务SQL要更新的业务数据,在业务数据被更新前,将其保存为前置镜像【before image】;然后才会执行业务SQL【如插入语句】更新业务数据;更新业务数据后将新的数据保存为后置镜像【after image】;并生产行锁【过程中将业务SQL、undo/redo日志和行锁提交到数据库的log表和lock表】,这有点类似AOP的前置后置通知的思想
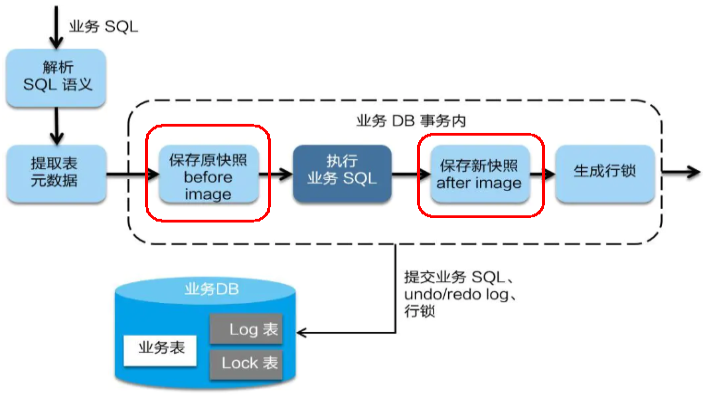
二阶段提交
逻辑就是JDBC的try、catch、finally;如果是业务SQL在一阶段都提交成功了,Seata框架只需要将一阶段保存的数据快照【包括前置数据和后置数据】和行锁全部删掉,完成数据的清理即可
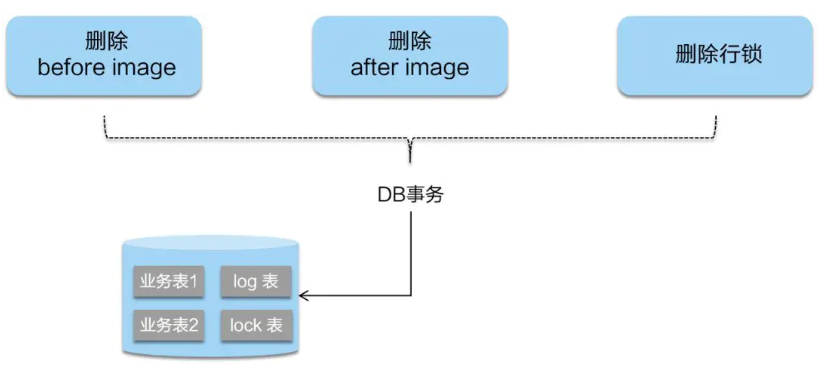
二阶段如果是回滚,seata回滚一阶段的业务SQL还原业务数据,回滚方式是使用before image还原业务数据,还原以前通过对比"数据库当前业务数据"和"after image"来校验数据是否被脏写,如果两份数据完全一致则没有脏写,直接还原数据【即官网介绍的反向补偿】即可,如果数据库表和后置镜像不一致,则说明有脏写,出现脏写需要人工处理
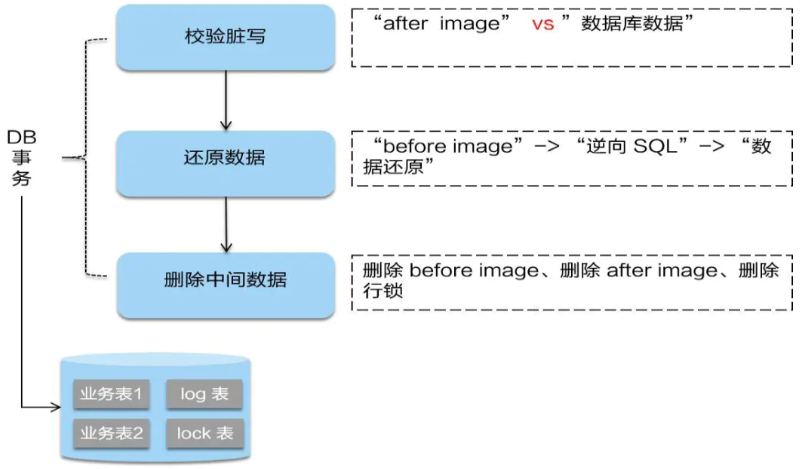
Debug演示AT模式的undo日志和快照信息
断点位置

【断点处前置后置快照、锁、事务相关信息的存储】
xid由
主机ip:seata服务器端口:事务id组成,事务名称【非事务组,在@GlobalTransactional注解的name属性指定】会存入global_table的transaction_name字段,undo日志会以json串的形式用mysql的blob类型保存每个子数据库操作的前置快照和后置快照到rollback_info字段中seata server的三个表和每个业务数据库的undo_log表中都会有对应数据
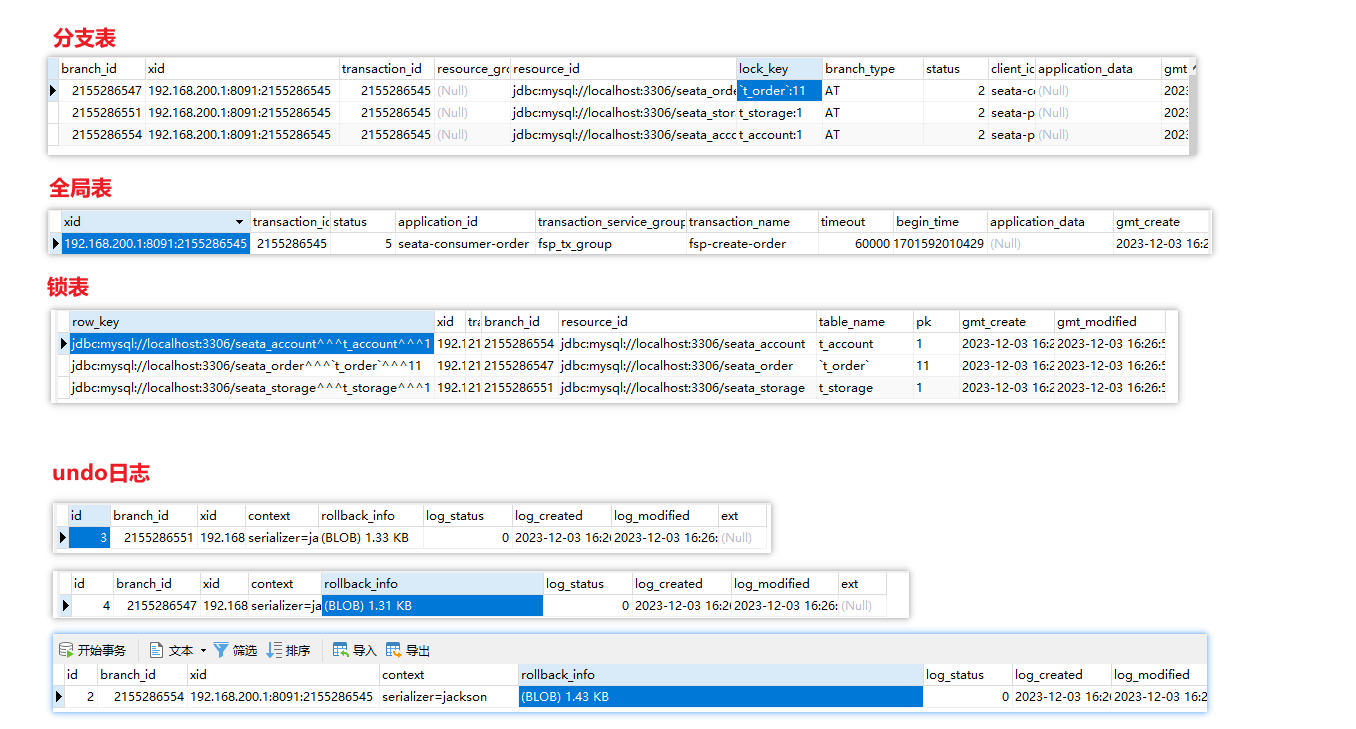
【rollback_info中的json串】
mysql中的blob格式需要选中文本选项或者图片选项才能查看,blob类型不限大小

【json内容】
其中有beforeImage,也有afterImage
xxxxxxxxxx{"@class": "io.seata.rm.datasource.undo.BranchUndoLog","xid": "192.168.200.1:8091:2155286545","branchId": 2155286554,"sqlUndoLogs": ["java.util.ArrayList",[{"@class": "io.seata.rm.datasource.undo.SQLUndoLog","sqlType": "UPDATE","tableName": "t_account","beforeImage": {"@class": "io.seata.rm.datasource.sql.struct.TableRecords","tableName": "t_account","rows": ["java.util.ArrayList",[{"@class": "io.seata.rm.datasource.sql.struct.Row","fields": ["java.util.ArrayList",[{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "id","keyType": "PrimaryKey","type": -5,"value": ["java.lang.Long",1]},{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "residue","keyType": "NULL","type": 3,"value": ["java.math.BigDecimal",600]},{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "used","keyType": "NULL","type": 3,"value": ["java.math.BigDecimal",400]}]]}]]},"afterImage": {"@class": "io.seata.rm.datasource.sql.struct.TableRecords","tableName": "t_account","rows": ["java.util.ArrayList",[{"@class": "io.seata.rm.datasource.sql.struct.Row","fields": ["java.util.ArrayList",[{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "id","keyType": "PrimaryKey","type": -5,"value": ["java.lang.Long",1]},{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "residue","keyType": "NULL","type": 3,"value": ["java.math.BigDecimal",500]},{"@class": "io.seata.rm.datasource.sql.struct.Field","name": "used","keyType": "NULL","type": 3,"value": ["java.math.BigDecimal",500]}]]}]]}}]]}分支事务流程
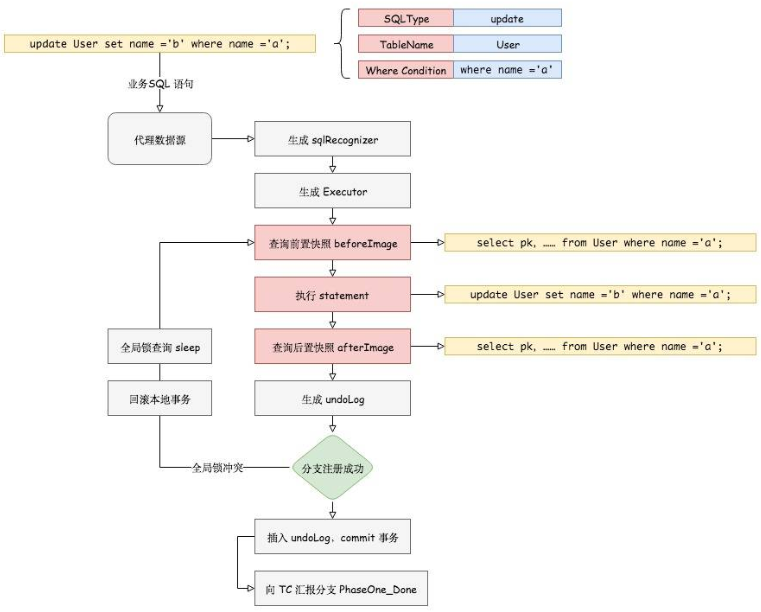
雪花算法
唯一全局ID生成
集群高并发情况下保证分布式唯一全局id的生成
分布式全局唯一id的业务需求
UUID、数据库自增主键【auto_increment】
分布式集群存在时钟和全局不重复的问题
复杂分布式系统中,需要对大量数据和消息进行唯一标识【如支付、酒店、电影票等数据,订单、骑手、优惠券等都需要唯一ID作为标识】,因此需要一种能够生成全局唯一ID的方法是很有必要的【全局唯一ID保证服务器扩容的情况下不会发生ID重复的情况】
ID生成规则的硬性要求
全局唯一【系统中不能出现重复的ID号】
趋势递增【mysql的InnoDB引擎使用的是聚集索引,多数RDBMS使用Btree的数据结构来存储索引数据,在主键的选择上应该尽量使用有序的主键来保证写入性能,InnoDB的特性就是将内容存储在主键索引树上的叶子结点,且从左到右递增,一般生成的ID单调递增会提高数据库的索引查询性能,如果无序会在叶子节点产生空位留白】
单调递增【净量保证下ID的生成随时间递增,以满足如事务版本号、IM增量消息、排序等特殊要求】
信息安全【需要ID净量无规则不规则,因为如果ID是连续的,恶意扒取就会变得相对容易,直接按顺序使用ID拼成指定URL即可,订单号就更危险,可以直接获取某天的单量】
含时间戳【可以快速了解分布式ID的生成时间,利于故障排查】
ID生成系统的可用性要求【假如算法部署在mysql服务器上,假设服务器宕机,所有业务就无法生成唯一标识号,因此生成唯一ID的算法部署服务器对硬件也有硬性要求】
高可用【要保证对获取分布式ID的请求,99.999%的情况下都要能成功创建唯一的分布式ID】
低延迟【发送获取分布式ID的请求,服务器要能急速处理】
高QPS【高并发访问的情况下要能处理所有的获取分布式ID的请求】
分布式ID生成的一般方案
snowflake【雪花算法】
Teitter的分布式自增ID算法snowflake,Twitter将存储系统从mysql迁移到Cassandra【由Facebook开发的一套开源分布式NoSQL数据库系统,可以看做Facebook版的redis】,因为Cassandra没有顺序ID生成机制,所以开发了一套全局唯一ID生成服务
雪花算法每秒能够产生26万个自增可排序的ID,在分布式系统内不会发生ID碰撞【由datacenter(数据中心)和workerId(机器码)作区分】且效率极高
雪花算法生成的ID能够按时间顺序有序生成
雪花算法生成的id是一个64bit的整数,为LONG型【LONG类型转换成字符串后长度最多19位字符串,而UUID转换成字符串不含连接符是32位】
满足无规则条件,防止别人爬取某台的交易量
雪花算法的核心部分
第一个bit是符号位,永远为0,因为1表示负数,0表示正数,生成的id一般都是用整数,最高位固定位0
1bit的时间戳可以表示69.73年,最小时间单位是1ms,就是使用雪花算法的系统可以使用69.73年保证不重复【这个竟然不能初始化时间1970年到2039年】,表示从0-2^{41}
xxxxxxxxxxpublic class TestUUID {public static void main(String[] args) {System.out.println(UUID.randomUUID());//ae9eaeb2-b467-4303-aa4c-df9769910235StringBuilder stringBuilder=new StringBuilder();for (int i = 0; i < 41; i++) {stringBuilder.append('1');}System.out.println(stringBuilder);//11111111111111111111111111111111111111111,这是雪花算法的时间戳部分System.out.println(stringBuilder.length());//41String endTimeString = stringBuilder.toString();//将二进制字符串转换成Long类型的十进制整数long endTimeLong = Long.parseLong(endTimeString, 2);System.out.println(endTimeLong);//2199023255551String endTimeDate = new SimpleDateFormat("yyyy-MM-dd").format(endTimeLong);System.out.println(endTimeDate);//2039-09-07}}10bit位表示工作进程位,分成前五个和后五个,前五个bit表示数据中心,后五个表示机器码,表示某个机房的哪一台机器,整体表示可以部署在2^{10}=1024个机器节点上,即最多可以有32个机房,每个机房可以有最多32台机器
12bit位序列号位,用来记录一个毫秒内产生的不同id,12bit可以表示0-(2^{12}-1)即0-4095个数字,表示同一个机器同一时间截【毫秒】内可以生成4096个ID序列号,理论上同一台机器可以生成409w6000个id
一共64位,所以雪花算法生成的id就是直接使用Long类型来存储

雪花算法的源码
官方网址:
github.com/twitter-archive/snowflake使用的是scale语法写的,网上活雷锋参考改出了一套java版本的
雪花算法java版源码
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 雪花算法生成唯一ID的原理* @创建日期 2023/12/04* @since 1.0.0*/public class SnowflakeIdWorker {/*** 工作机器Id(0-31)*/private long workerId;/***数据中心Id(0-31)*/private long datacenterId;/***毫秒内序列(0-4095)*/private long sequence = 0L;/***上次生成ID的时间戳,还没有生成初始值为-1*/private long lastTimestamp = -1L;/***系统开始时间截*/private final long twepoch=1420041600000L;/***机器id所占的位数,这个不是固定的,可以根据实际情况自定义*/private final long workerIdBits=5L;/***数据中心标识id占据位数*/private final long datacenterIdBits=5L;/***支持的最大机器ID,结果是31(由位移算法快速计算出表示机器码的几位二进制能表示的最大十进制数)*/private final long maxWorkerId=-1L^(-1L<<workerIdBits);/***支持的最大数据中心标识id,结果是31*/private final long maxDatacenterId=-1L^(-1L<<datacenterIdBits);/***序列在id中占的位数*/private final long sequenceBits=12L;/***机器ID向左移12位,准备合并唯一id,定好机器ID需要左移的次数*/private final long workerIdShift=sequenceBits;/***数据标识id向左移17位*/private final long datacenterIdShift=sequenceBits+workerIdBits;/***时间截需要左移的位数(5+5+12)*/private final long timestampLeftShift=sequenceBits+workerIdBits+datacenterIdBits;/***生成序列的掩码,此处为4095(0b1111111111=0xfff=4095)*/private final long sequenceMask=-1L^(-1L<<sequenceBits);//==================================Constructors=========================================/*** @param workerId 机器ID(0-31)* @param datacenterId 数据中心ID(0-31)* @return* @描述* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public SnowflakeIdWorker(long workerId,long datacenterId) throws IllegalAccessException {if (workerId>maxWorkerId || workerId <0) {//String.format类似于C语言的将后面的变量赋值给输出字符串中的占位符throw new IllegalAccessException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId>maxDatacenterId || datacenterId<0){throw new IllegalAccessException(String.format("datacenter Id can't be greater than %d or less than 0"));}this.workerId=workerId;this.datacenterId=datacenterId;}//==================================Methods=========================================/*** @return long* @描述 该方法是线程安全的,这个就是获取唯一ID的方法* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long nextId(){long timestamp=timeGen();//如果当前时间小于上一次ID生成的时间截,说明系统时钟回退过,此时应该抛出异常if(timestamp < lastTimestamp){throw new RuntimeException(String.format("CLock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp-timestamp));}//如果当前ID和上一个ID是同一时间截内生成的,则进行毫秒内序列处理if(lastTimestamp == timestamp){sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if(sequence == 0){//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}//时间戳改变,毫秒内序列重置else{sequence=0L;}//上次生成ID的时间截lastTimestamp = timestamp;//位移并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;}/*** @param lastTimestamp 上次生成ID的时间截* @return long 当前时间截* @描述 阻塞到下一个毫秒,直到获取到新的时间截* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/protected long tilNextMillis(long lastTimestamp){long timestamp = timeGen();while(timestamp < lastTimestamp){timestamp = timeGen();}return timestamp;}/*** @return long 当前时间(毫秒)* @描述 返回以毫秒为单位的当前时间* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/protected long timeGen(){return System.currentTimeMillis();}//==============================================测试========================================public static void main(String[] args) {SnowflakeIdWorker idWorker = null;try {idWorker = new SnowflakeIdWorker(0, 0);} catch (IllegalAccessException e) {e.printStackTrace();}for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id+"\t"+String.valueOf(id).length());}}}
雪花算法的工程落地
糊涂工具包:
非常爽,专门干小而美的事情
官网地址:
https://github.com/looly/hutool/,在hutool-captcha即图片验证码实现中就包含雪花算法的实现,如果要用全家桶,就引入hutool-allpom.xml
【只使用雪花算法】
xxxxxxxxxx<denpendency><groupId>cn.hutool</groupId><artifactId>hutool-captcha</artifactId><version>4.6.8</version></denpendency>【使用hutool-all】
xxxxxxxxxx<denpendency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.0.1</version></denpendency>
使用雪花算法的项目搭建
pom.xml
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-captcha</artifactId><version>4.6.8</version></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>启动类
xxxxxxxxxxpublic class IDApplication {public static void main(String[] args){SpringApplication.run(IDApplication.class,args);}}ID工具类
使用糊涂工具包生成的包括雪花算法【但是没用默认的机器id和数据中心id生成id,使用的是本机IP,细节要研究糊涂工具包源码】
xxxxxxxxxxpackage com.atlisheng.cloud.utils;import cn.hutool.core.lang.Snowflake;import cn.hutool.core.net.NetUtil;import cn.hutool.core.util.IdUtil;import lombok.extern.slf4j.Slf4j;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/*** @author Earl* @version 1.0.0* @描述 核心还是hutool工具包的IdUtil类,里面有很多生成各种ID的算法,这里只是对IdUtil生成雪花算法的又一层封装* @创建日期 2023/12/04* @since 1.0.0*/public class IdGeneratorUtilWithSnowflakeByHuTool {private long workerId = 0L;private long datacenterId = 1L;private Snowflake snowflake = IdUtil.createSnowflake(workerId,datacenterId);// @PostConstruct是java自带的注解,用途是被注解的方法,在对象加载完依赖注入后执行。此注解是在Java EE5规范中加入的,// 在Servlet生命周期中有一定作用,它通常都是一些初始化的操作,但初始化可能依赖于注入的其他组件,所以要等依赖全部加载完再执行。// 与之对应的还有@PreDestroy,在对象消亡之前执行,原理差不多,这里不做过多介绍public void init(){try{log.info(NetUtil.getLocalhostStr());//192.168.200.1//获取本机的workerIdworkerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());log.info("当前机器的workerId:{}",workerId);//当前机器的workerId:3232286721}catch (Exception e){e.printStackTrace();log.warn("当前机器的workerId获取失败:{}",e);//如果获取不到机器id为workerId手动生成一个,避免workerId没有值,具体的含义看文档workerId = NetUtil.getLocalhostStr().hashCode();log.warn("手动生成的workerId:{}",workerId);}}/*** @return long* @描述 这个是使用默认本机Id和数据中心Id生成的雪花算法ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long snowflakeId(){return snowflake.nextId();}/*** @param workerId* @param datacenterId* @return long* @描述 这个方法是指定机器Id和数据Id生成的雪花算法ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long snowflakeId(long workerId,long datacenterId){Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);return snowflake.nextId();}/*** @return {@link String }* @描述 生成UUID去掉-的字符串* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public String simpleUUID(){return IdUtil.simpleUUID();}/*** @return {@link String }* @描述 生成最纯净版的UUID,即带-的* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public String randomUUID(){return IdUtil.randomUUID();}/*** @param args* @描述 工具方法测试* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public static void main(String[] args) {IdGeneratorUtilWithSnowflakeByHuTool idGenerator = new IdGeneratorUtilWithSnowflakeByHuTool();log.info(String.valueOf(idGenerator.snowflakeId()));//1731649814501916672log.info(idGenerator.simpleUUID());//3493f90896d346659e3c5e54c035f75dlog.info(idGenerator.randomUUID());//75a40940-fb39-4b80-9810-555ccff3ebc7}}前端控制器
这里面的线程池就本例来说就是整活,以后可能会接触到
xxxxxxxxxx("/id")public class IDController {private IdGeneratorUtilWithSnowflakeByHuTool idGenerator;/*** @return {@link CommonResp }* @描述 测试通过一个线程池获取多个雪花算法生成的ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/("/create")public CommonResp generateId(){//生成含5个线程的线程池,线程池使用之后要立刻关ExecutorService threadPool = Executors.newFixedThreadPool(5);//意思是模拟20个请求,每个请求都通过线程池去获取雪花算法生成的idfor (int i = 0; i < 20; i++) {/*** 执行效果(只展示一部分)* 1731652083855261706* 1731652083855261707* 1731652083855261708* 1731652083855261709* 1731652083855261710* 1731652083855261711* 1731652083855261712* 1731652083855261713* 1731652083855261714* 1731652083855261715* */System.out.println(idGenerator.snowflakeId());}threadPool.shutdown();return new CommonResp(200,"snowflake");}}
【启动效果,这个机器ID似乎是用本机的IP生成的,不是使用0的机器ID和0的数据中心ID生成的】
【控制台id生成情况】
只展示了部分
xxxxxxxxxx1731652083855261706173165208385526170717316520838552617081731652083855261709173165208385526171017316520838552617111731652083855261712173165208385526171317316520838552617141731652083855261715
雪花算法的优缺点
优点
毫秒数在高位,毫秒内自增序列在低位,整个ID都是趋势递增的
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成地 ID性能也非常高
可以根据业务特性灵活分配bit位,非常的灵活
缺点
依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
单机上递增,如果设计到分布式系统,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况,该缺点可以认为无所谓,一般分布式ID值要求趋势递增,不会要求严格递增,90%的需求都只要求趋势递增
一般公司用雪花算法不用考虑时钟问题,如果非要要求有两家公司彻底解决了时钟回拨问题,并对雪花算法进行了优化,一个是百度开源的分布式唯一ID生成器UidGenerator、另一个是美团点评分布式ID生成系统Leaf,参考这两个进行雪花算法的时钟问题的同步
UUID
UUID.randomUUID().toString()生成一个32位的字符串,UUID【Universally Unique Identifier】的标准形式,包含32个16进制数字,以连字符分为字段,形式为8-4-4-4-12的36个字符【32个16进制数字+四个连字符,示例:2a007166-17a6-4394-b588-bb418ea15750】优点:肯定不重复,性能非常高,本地生成,没有网络消耗,jdk自带,只考虑唯一性的情况下已经够用,关键是无序,入数据库的性能比较差,id自增的情况下mysql的b树会生成的更好
缺点:
无序,无法看出UUID间的生成顺序,不能生成递增有序的数字
且比较长,分布式ID一般都会作为主键,mysql官方推荐主键越短越好,UUID每一个都很长,不推荐作为主键入数据库
拿UUID作为主键,会在特定的环境中存在一些问题【mysql官方说的如果主键太长,次级索引会使用更多的空间,强烈推荐使用短主键】
分布式ID一般作为主键,主键包含索引,mysql的索引是通过b+树实现的,因为UUID是无序的,为了查询的优化,每次新的UUID数据插入都会对主键地域的b+树进行很大的修改,会导致一些中间节点产生分裂,也会白白创造很多不饱和的节点,大大降低数据库插入的性能
五个分布式ID硬性要求只满足唯一性要求
数据库自增主键
单机的情况下可以使用,分布式系统有问题
数据库自增ID机制的原理是通过数据库自增ID和mysql数据库的replace into实现的,replace into和insert类似,不同点在于replace into先尝试插入数据到表中,如果发现表中已经有了相同主键或相同唯一索引的记录,就先删除原记录,再插入新数据,replace into的含义是插入一条记录,如果表中唯一索引的值遇到冲突则替换老数据】
代码
REPLACE INTO t_test (stub) values('b');反复执行会将此前相同唯一性约束的'b'的记录删掉,然后再重新插入相同stub字段属性值的记录,不同的是自增主键自加1,第一次为1,b,第二次会显示2,bxxxxxxxxxxCREATE TABLE t_test(id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,stub CHAR(1) NOT NULL DEFAULT '',UNIQUE KEY stub (stub))SELECT * FROM t_test;REPLACE INTO t_test (stub) values('b');SELECT LAST_INSERT_ID();创建以上这个表,通过唯一约束字段,使用自增主键来生成对应的ID肯定是唯一且自增的,比UUID好,多满足了一个有序的条件,可以通过代码
SELECT LAST_INSERT_ID();查出来当前自增主键的值作为生成的唯一ID【小厂用这种方式就足够了,不需要处理分布式高并发场景,但是搞不定电商金融系统】缺点,高并发情况下,mysql服务器扛不住,可能发生宕机的情况,mysql服务器一旦宕机,自增主键生成不了,会发生非常严重的问题,所以这种数据库自增ID机制不适合做分布式ID,分布式系统使用这种机制一定要配置mysql集群,而使用mysql集群且做分布式ID生成服务器,会导致系统的水平扩展比较困难,比如最开始只有一台mysql机器做分布式ID的生成,但是这时候需要再加一台,为了保证主键的唯一性,需要将第二台机器的初始ID值设置的远超第一台,这样长时间两台机器的主键都不会重复,但是如果要添加100台mysql服务器,此时每台服务器都要进行这样的设置会变得非常复杂,难以实现【更别说分表分库扩容会带来非常多的麻烦】
数据库压力大,每次获取ID都需要读写一次数据库,非常影响性能,不符合分布式ID中服务器低延迟和高QPS的要求,高并发情况下要去从数据库获取ID,是非常影响性能的
基于redis生成全局id的策略
redis是单线程的【redis6已经支持多线程了】,天生保证原子性,可以使用原子操作INCR和INCRBY来实现全局ID的生成
缺点:和MYSQL一样在Redis集群的情况下同样需要设置不同redis服务器的初始值和步长,同时key也需要设置有效期,使用redis集群能够增加生成主键的吞吐量,又要防止配置ID生成逻辑防止单点故障,又要设置哨兵宕机情况下的反应,非常的麻烦,系统不需要redis使用这种方案生成ID还需要单独引入redis集群,宕机以后ID的单增要求也无法保证了
应用举例:一个redis集群中有5台redis【A、B、C、D、E】,初始化每台redis的值分别为1、2、3、4、5,步长设置为5;每台Redis生成的ID分别为
A:1、6、11、16、21
B:2、7、12、17、22
C:3、8、13、18、23
D:4、9、14、19、24
E:5、10、15、20、25
附录
用户网页端口80:提供给用户的服务【如支付下订单的模块】,用户不应该关心输入哪个端口进行访问,浏览器网页服务的默认端口都是80,只需要输入网址,不需要输入:80,提升用户体验
分布式CAP理论
CAP:一致性、可用性、分区容错性
使用命令
ipconfig查看windows本地的ip地址用于虚拟机linux系统和本机的通信
引入mybatis的依赖必须配置数据源或者排除数据源的自动配置类项目才能启动
Zookeeper的运行最好配置完整的jdk环境,避免项目注册发生问题
注意Zookeeper的服务名区分大小写,Zookeeper集群需要开启多台虚拟机模拟
如果idea出现spring的配置文件无法读取的问题【IDEA的bug】,打开项目结构,选中项目右键,add选中spring,选中添加的叶子图表,将配置文件添加到spring的关联文件中去
模拟发送http请求的工具
jmeter
postman
curl
Dubbo框架也是阿里巴巴出的【美团和阿里用java比较多,58用的也多】
Dubbo停更了,spring【一些边缘功能】结合netflix【eureka、ribbon、zuul、Feign、config】整出了springCloud2018,现在netflix快噶了,阿里巴巴又想把springCloud给包了,springCloud Alibaba的相关设计是为了阿里云【核心业务全上云】,springCloud Alibaba基本替代netflix也和SpringCloud配合协调的很好,SpringCloud也对他眉来眼去
使用ribbon方式进行负载均衡时,只能使用在注册中心注册了的应用名,不能使用ip+port的形式进行访问,否则会抛异常【用的是RestTemplate加ribbon负载均衡调用】,服务调用无法实现。rbbion的工作原理是,对请求进行拦截,获取url中的应用名称(当然该应用名称不一定正确),然后从Eureka获取注册服务列表,采用负载均衡策略进行访问。
在bootstrap.yml中配置如下内容,可以避免nacos在客户端连续打印不重要信息
如nacos连续打印
naming.updater] com.alibaba.nacos.client.namingnacos只在客户端打印错误信息
xxxxxxxxxxlogginglevelcom.alibaba.nacos.client.namingerror生产上使用GA版本,版本知识
开发期
Pre-alpha
有时候软件会在Alpha或Beta版本前先发布Pre-alpha版本。一般而言相对于Alpha或Beta版本,Pre-alpha版本是一个功能不完整的版本。
Alpha
Alpha版本仍然需要测试,其功能亦未完善,因为它是整个软件发布周期中的第一个阶段,所以它的名称是“Alpha”,希腊字母中的第一个字母“α”。
Alpha版本通常会送到开发软件的组织或某群体中的软件测试者作内部测试。在市场上,越来越多公司会邀请外部客户或合作伙伴参与其测试。这令软件在此阶段有更大的可用性测试
Beta
Beta版本是软件最早对外公开的软件版本,由公众(通常为公司外的第三方开发者和业余玩家)参与测试。 因为是Alpha的下一个阶段,所以为希腊字母的第二个字Beta (β)。 一般来说,Beta包含所有功能,但可能有一些已知问题和较轻微的程序错误(BUG),要进行调试(debug)。Beta版本的测试者通常是开发软件的组织的客户,他们会以免费或优惠价钱得到软件。Beta版本亦作为测试产品的支持和市场反应等。
其他情况不同企业有不同的称法,例如微软曾以Community Technology Preview(简称CTP,中文称为“社群技术预览”)为发布软件的测试版本之一,微软将这个阶段的软件散布给有需要先行试用的用户或厂商,并收集这些人的使用经验,以便作为进一步修正软件的参考。
Release Candidate
Release Candidate(简称RC)指可能成为最终产品的候选版本,如果未出现问题则可发布成为正式版本。在此阶段的产品通常包含所有功能、或接近完整,亦不会出现严重问题。
多数开源软件会推出两个RC版本,最后的RC2则成为正式版本。闭源软件较少公开使用,微软公司在Windows 7上应用此名称。苹果公司把在这阶段的产品称为“Golden Master Candidate”(简称GM Candidate),而最后的GM即成为正式版本。而 iOS 自 14.2 开始亦采用 RC 称呼处于此阶段的版本状态。
完成期
生产商发放(Release to Manufacturing,RTM)
生产商发放(Release to Manufacturing,缩写RTM)是软件产品准备交付时使用的术语,来自于以前还需要使用实体载具(光盘,硬盘等)来进行安装的时代,某些计算机程序以“RTM”作为软件版本代号,例如微软Windows 7发行零售版前的RTM版本主要是发放给组装机生产商用,使制造商能够提早进行集成工作或解决软件与硬件设备可能遇到的错误。RTM版本并不一定意味着创作者解决了软件所有问题;仍有可能向公众发布前更新版本。以Windows 7为例:RTM版与零售版的版本号是一样的。
一般可用(General availability,GA)
一般可用(General availability, 缩写GA)是所有必要的商业活动已经完成,该软件产品已经可以发售的阶段。然而,这取决于语言、地域和电子设备与媒体的可用性,有些地区之间可能会有上市时间的延迟。商业活动可能也包括安全性和合法测试,以及本地化和全球销售的可能性评估。RTM与GA的间隔可能会是1周或几个月,因为在此过程中需要进行许多商业活动。在这个阶段,可以说软件已经“上线”了。
网络分发(Release to Web,RTW)
网络分发(Release to Web,缩写RTW),或称Web发布是一种利用互联网进行分发的软件交付方式。制造商在这种类型的发布中并不生产实体软件工具,而会借由OTA来进行发放。随着互联网使用人数的增长,RTW变得越来越普遍。
稳定版(Stable)
稳定版本来自预览版本释出使用与改善而修正完成,通常是初始版本进行几个小更新后的版本。为目前所使用的软件在符合需求规格的硬件与操作系统中运行不会造成严重的不兼容或是硬件冲突,其已受过某定量的测试无误后所释出者。
软件支持
在软件的生命周期内,有时会发布新版本、补丁或服务包。例如Windows XP,其32位有3个服务包,64位版本有两个。这些服务包包含以单个可安装软件包的形式提供的更新、补丁和功能增强,也有新功能提供。一些软件,例如防病毒软件和游戏,需要长期的更新支持。
软件寿命结束
主条目:产品寿命结束
当软件不再销售并已被停止支持时,该产品即达到使用寿命终止阶段。但忠实用户群可能会继续存在,甚至是持续很久。例如Windows XP在中国大陆的占有率依然很高。
包规范
VO:前端用与数据封装的叫
viewObject、后端用的封装数据的时候叫valueObjectdto:是前台将数据传输到后台的一个传输类